 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Space Analysis by Guided Diffusion Model
Sep 09, 2025One of the key issues in Deep Neural Networks (DNNs) is the black-box nature of their internal feature extraction process. Targeting vision-related domains, this paper focuses on analysing the feature space of a DNN by proposing a decoder that can generate images whose features are guaranteed to closely match a user-specified feature. Owing to this guarantee that is missed in past studies, our decoder allows us to evidence which of various attributes in an image are encoded into a feature by the DNN, by generating images whose features are in proximity to that feature. Our decoder is implemented as a guided diffusion model that guides the reverse image generation of a pre-trained diffusion model to minimise the Euclidean distance between the feature of a clean image estimated at each step and the user-specified feature. One practical advantage of our decoder is that it can analyse feature spaces of different DNNs with no additional training and run on a single COTS GPU. The experimental results targeting CLIP's image encoder, ResNet-50 and vision transformer demonstrate that images generated by our decoder have features remarkably similar to the user-specified ones and reveal valuable insights into these DNNs' feature spaces.
Domain Adaptation for Japanese Sentence Embeddings with Contrastive Learning based on Synthetic Sentence Generation
Mar 12, 2025Several backbone models pre-trained on general domain datasets can encode a sentence into a widely useful embedding. Such sentence embeddings can be further enhanced by domain adaptation that adapts a backbone model to a specific domain. However, domain adaptation for low-resource languages like Japanese is often difficult due to the scarcity of large-scale labeled datasets. To overcome this, this paper introduces SDJC (Self-supervised Domain adaptation for Japanese sentence embeddings with Contrastive learning) that utilizes a data generator to generate sentences, which have the same syntactic structure to a sentence in an unlabeled specific domain corpus but convey different semantic meanings. Generated sentences are then used to boost contrastive learning that adapts a backbone model to accurately discriminate sentences in the specific domain. In addition, the components of SDJC like a backbone model and a method to adapt it need to be carefully selected, but no benchmark dataset is available for Japanese. Thus, a comprehensive Japanese STS (Semantic Textual Similarity) benchmark dataset is constructed by combining datasets machine-translated from English with existing datasets. The experimental results validates the effectiveness of SDJC on two domain-specific downstream tasks as well as the usefulness of the constructed dataset. Datasets, codes and backbone models adapted by SDJC are available on our github repository https://github.com/ccilab-doshisha/SDJC.
JCSE: Contrastive Learning of Japanese Sentence Embeddings and Its Applications
Jan 19, 2023Contrastive learning is widely used for sentence representation learning. Despite this prevalence, most studies have focused exclusively on English and few concern domain adaptation for domain-specific downstream tasks, especially for low-resource languages like Japanese, which are characterized by insufficient target domain data and the lack of a proper training strategy. To overcome this, we propose a novel Japanese sentence representation framework, JCSE (derived from ``Contrastive learning of Sentence Embeddings for Japanese''), that creates training data by generating sentences and synthesizing them with sentences available in a target domain. Specifically, a pre-trained data generator is finetuned to a target domain using our collected corpus. It is then used to generate contradictory sentence pairs that are used in contrastive learning for adapting a Japanese language model to a specific task in the target domain. Another problem of Japanese sentence representation learning is the difficulty of evaluating existing embedding methods due to the lack of benchmark datasets. Thus, we establish a comprehensive Japanese Semantic Textual Similarity (STS) benchmark on which various embedding models are evaluated. Based on this benchmark result, multiple embedding methods are chosen and compared with JCSE on two domain-specific tasks, STS in a clinical domain and information retrieval in an educational domain. The results show that JCSE achieves significant performance improvement surpassing direct transfer and other training strategies. This empirically demonstrates JCSE's effectiveness and practicability for downstream tasks of a low-resource language.
Segmentation of Weakly Visible Environmental Microorganism Images Using Pair-wise Deep Learning Features
Aug 31, 2022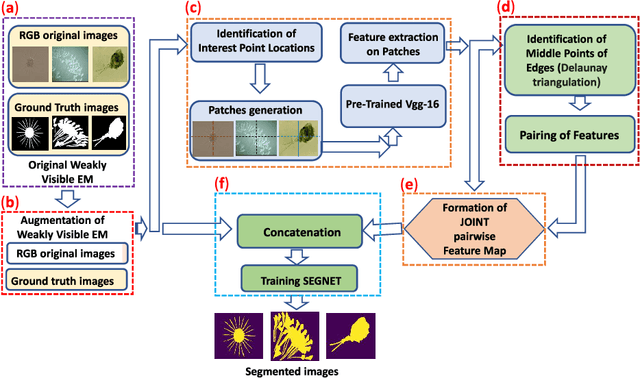



The use of Environmental Microorganisms (EMs) offers a highly efficient, low cost and harmless remedy to environmental pollution, by monitoring and decomposing of pollutants. This relies on how the EMs are correctly segmented and identified. With the aim of enhancing the segmentation of weakly visible EM images which are transparent, noisy and have low contrast, a Pairwise Deep Learning Feature Network (PDLF-Net) is proposed in this study. The use of PDLFs enables the network to focus more on the foreground (EMs) by concatenating the pairwise deep learning features of each image to different blocks of the base model SegNet. Leveraging the Shi and Tomas descriptors, we extract each image's deep features on the patches, which are centered at each descriptor using the VGG-16 model. Then, to learn the intermediate characteristics between the descriptors, pairing of the features is performed based on the Delaunay triangulation theorem to form pairwise deep learning features. In this experiment, the PDLF-Net achieves outstanding segmentation results of 89.24%, 63.20%, 77.27%, 35.15%, 89.72%, 91.44% and 89.30% on the accuracy, IoU, Dice, VOE, sensitivity, precision and specificity, respectively.
Cross-modal Music Emotion Recognition Using Composite Loss-based Embeddings
Dec 14, 2021
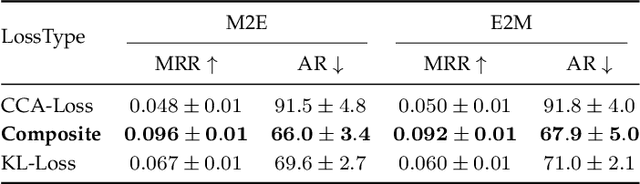

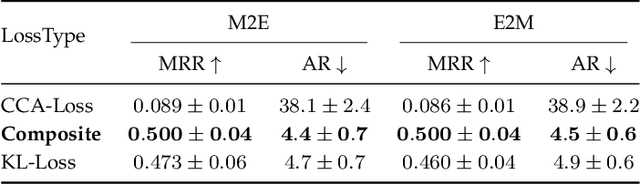
Most music emotion recognition approaches use one-way classification or regression that estimates a general emotion from a distribution of music samples, but without considering emotional variations (e.g., happiness can be further categorised into much, moderate or little happiness). We propose a cross-modal music emotion recognition approach that associates music samples with emotions in a common space by considering both of their general and specific characteristics. Since the association of music samples with emotions is uncertain due to subjective human perceptions, we compute composite loss-based embeddings obtained to maximise two statistical characteristics, one being the correlation between music samples and emotions based on canonical correlation analysis, and the other being a probabilistic similarity between a music sample and an emotion with KL-divergence. Experiments on two benchmark datasets demonstrate the superiority of our approach over one-way baselines. In addition, detailed analysis show that our approach can accomplish robust cross-modal music emotion recognition that not only identifies music samples matching with a specific emotion but also detects emotions expressed in a certain music sample.
Generic Itemset Mining Based on Reinforcement Learning
May 17, 2021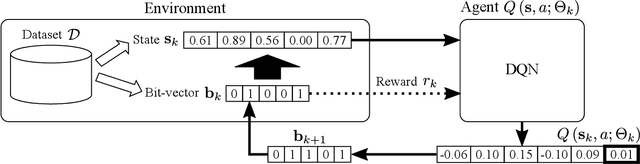

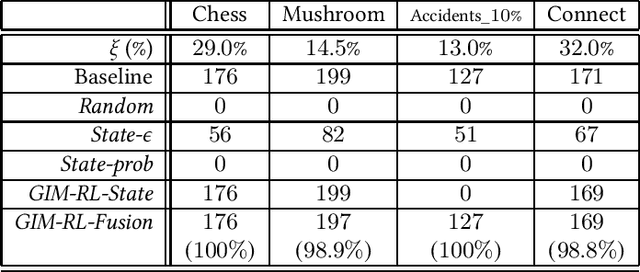

One of the biggest problems in itemset mining is the requirement of developing a data structure or algorithm, every time a user wants to extract a different type of itemsets. To overcome this, we propose a method, called Generic Itemset Mining based on Reinforcement Learning (GIM-RL), that offers a unified framework to train an agent for extracting any type of itemsets. In GIM-RL, the environment formulates iterative steps of extracting a target type of itemsets from a dataset. At each step, an agent performs an action to add or remove an item to or from the current itemset, and then obtains from the environment a reward that represents how relevant the itemset resulting from the action is to the target type. Through numerous trial-and-error steps where various rewards are obtained by diverse actions, the agent is trained to maximise cumulative rewards so that it acquires the optimal action policy for forming as many itemsets of the target type as possible. In this framework, an agent for extracting any type of itemsets can be trained as long as a reward suitable for the type can be defined. The extensive experiments on mining high utility itemsets, frequent itemsets and association rules show the general effectiveness and one remarkable potential (agent transfer) of GIM-RL. We hope that GIM-RL opens a new research direction towards learning-based itemset mining.
A New Pairwise Deep Learning Feature For Environmental Microorganism Image Analysis
Feb 24, 2021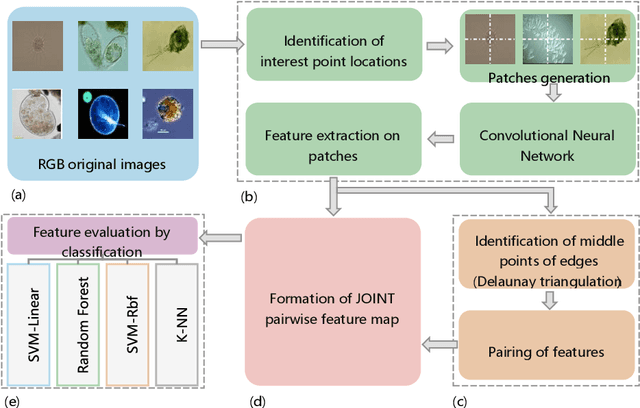

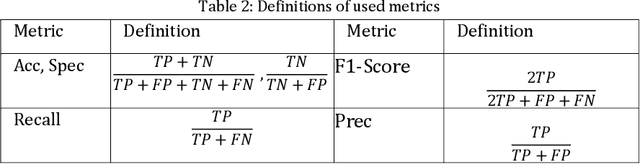
Environmental microorganism (EM) offers a high-efficient, harmless, and low-cost solution to environmental pollution. They are used in sanitation, monitoring, and decomposition of environmental pollutants. However, this depends on the proper identification of suitable microorganisms. In order to fasten, low the cost, increase consistency and accuracy of identification, we propose the novel pairwise deep learning features to analyze microorganisms. The pairwise deep learning features technique combines the capability of handcrafted and deep learning features. In this technique we, leverage the Shi and Tomasi interest points by extracting deep learning features from patches which are centered at interest points locations. Then, to increase the number of potential features that have intermediate spatial characteristics between nearby interest points, we use Delaunay triangulation theorem and straight-line geometric theorem to pair the nearby deep learning features. The potential of pairwise features is justified on the classification of EMs using SVMs, k-NN, and Random Forest classifier. The pairwise features obtain outstanding results of 99.17%, 91.34%, 91.32%, 91.48%, and 99.56%, which are the increase of about 5.95%, 62.40%, 62.37%, 61.84%, and 3.23% in accuracy, F1-score, recall, precision, and specificity respectively, compared to non-paired deep learning features.