 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Online Forums Summarization via Unifying Hierarchical Attention Networks with Convolutional Neural Networks
Mar 25, 2021
Online discussion forums are prevalent and easily accessible, thus allowing people to share ideas and opinions by posting messages in the discussion threads. Forum threads that significantly grow in length can become difficult for participants, both newcomers and existing, to grasp main ideas. This study aims to create an automatic text summarizer for online forums to mitigate this problem. We present a framework based on hierarchical attention networks, unifying Bidirectional Long Short-Term Memory (Bi-LSTM) and Convolutional Neural Network (CNN) to build sentence and thread representations for the forum summarization. In this scheme, Bi-LSTM derives a representation that comprises information of the whole sentence and whole thread; whereas, CNN recognizes high-level patterns of dominant units with respect to the sentence and thread context. The attention mechanism is applied on top of CNN to further highlight the high-level representations that capture any important units contributing to a desirable summary. Extensive performance evaluation based on three datasets, two of which are real-life online forums and one is news dataset, reveals that the proposed model outperforms several competitive baselines.
A Self-supervised Representation Learning of Sentence Structure for Authorship Attribution
Oct 14, 2020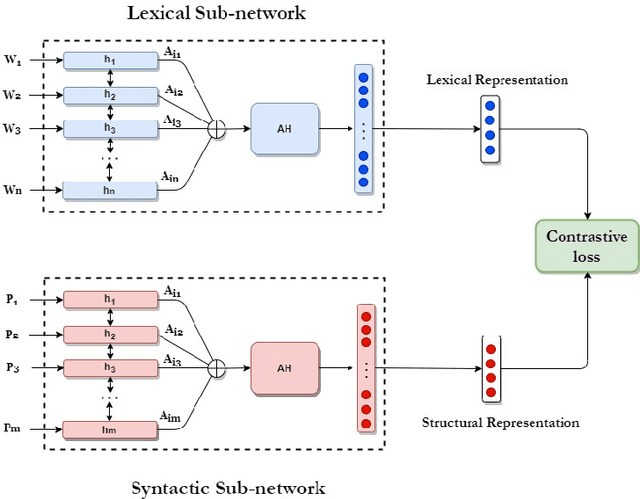
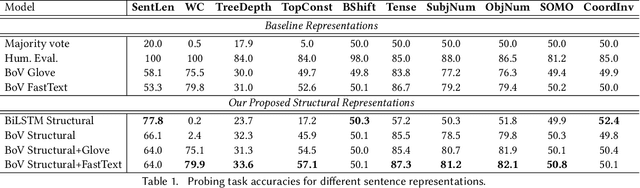
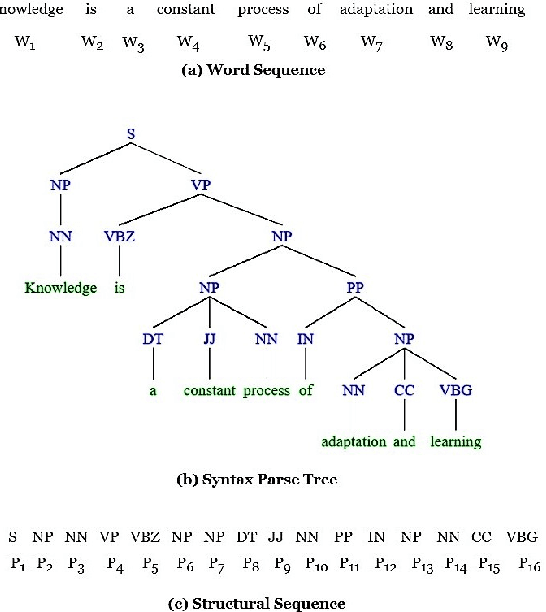
Syntactic structure of sentences in a document substantially informs about its authorial writing style. Sentence representation learning has been widely explored in recent years and it has been shown that it improves the generalization of different downstream tasks across many domains. Even though utilizing probing methods in several studies suggests that these learned contextual representations implicitly encode some amount of syntax, explicit syntactic information further improves the performance of deep neural models in the domain of authorship attribution. These observations have motivated us to investigate the explicit representation learning of syntactic structure of sentences. In this paper, we propose a self-supervised framework for learning structural representations of sentences. The self-supervised network contains two components; a lexical sub-network and a syntactic sub-network which take the sequence of words and their corresponding structural labels as the input, respectively. Due to the n-to-1 mapping of words to their structural labels, each word will be embedded into a vector representation which mainly carries structural information. We evaluate the learned structural representations of sentences using different probing tasks, and subsequently utilize them in the authorship attribution task. Our experimental results indicate that the structural embeddings significantly improve the classification tasks when concatenated with the existing pre-trained word embeddings.
Attention Based Neural Architecture for Rumor Detection with Author Context Awareness
Sep 19, 2019

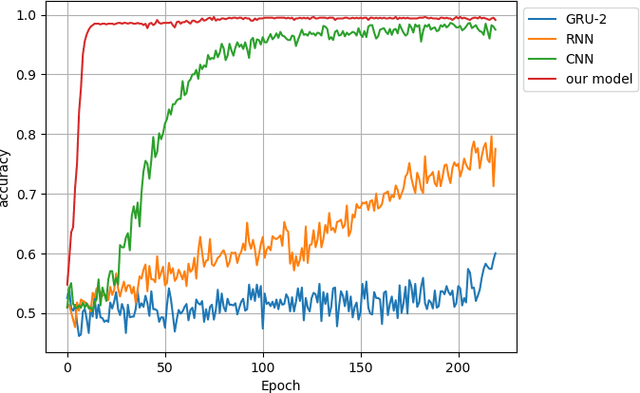

The prevalence of social media has made information sharing possible across the globe. The downside, unfortunately, is the wide spread of misinformation. Methods applied in most previous rumor classifiers give an equal weight, or attention, to words in the microblog, and do not take the context beyond microblog contents into account; therefore, the accuracy becomes plateaued. In this research, we propose an ensemble neural architecture to detect rumor on Twitter. The architecture incorporates word attention and context from the author to enhance the classification performance. In particular, the word-level attention mechanism enables the architecture to put more emphasis on important words when constructing the text representation. To derive further context, microblog posts composed by individual authors are exploited since they can reflect style and characteristics in spreading information, which are significant cues to help classify whether the shared content is rumor or legitimate news. The experiment on the real-world Twitter dataset collected from two well-known rumor tracking websites demonstrates promising results.
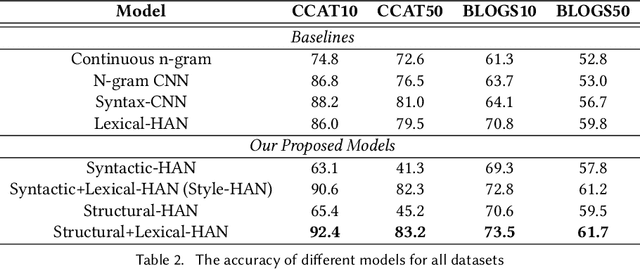
Style-aware Neural Model with Application in Authorship Attribution
Sep 12, 2019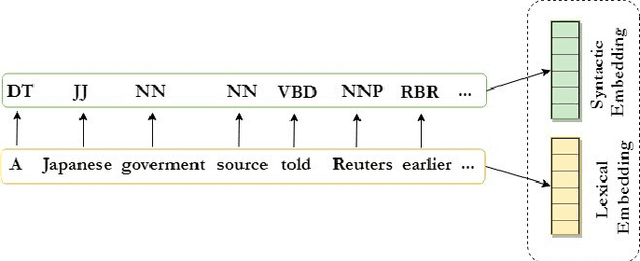
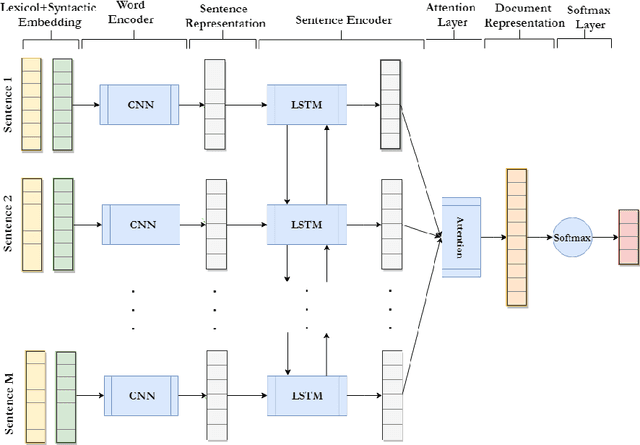
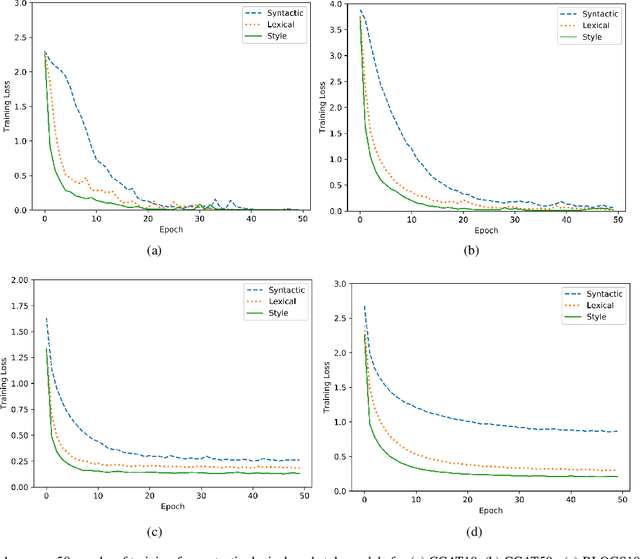
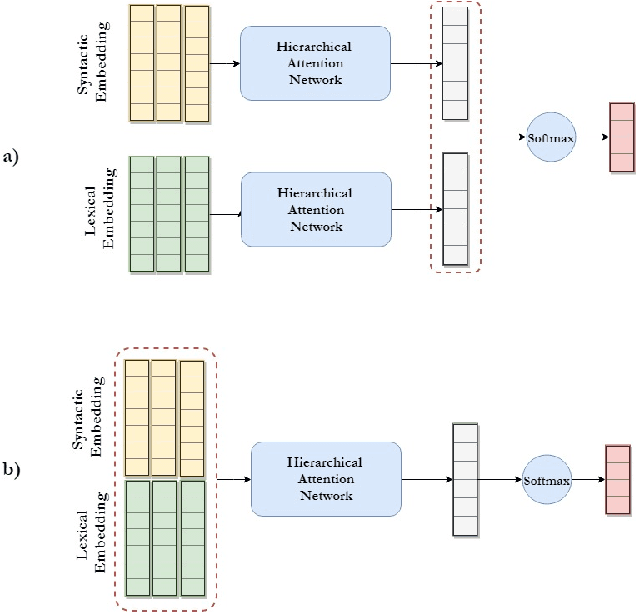
Writing style is a combination of consistent decisions associated with a specific author at different levels of language production, including lexical, syntactic, and structural. In this paper, we introduce a style-aware neural model to encode document information from three stylistic levels and evaluate it in the domain of authorship attribution. First, we propose a simple way to jointly encode syntactic and lexical representations of sentences. Subsequently, we employ an attention-based hierarchical neural network to encode the syntactic and semantic structure of sentences in documents while rewarding the sentences which contribute more to capturing the writing style. Our experimental results, based on four benchmark datasets, reveal the benefits of encoding document information from all three stylistic levels when compared to the baseline methods in the literature.
Differential Recurrent Neural Network and its Application for Human Activity Recognition
May 09, 2019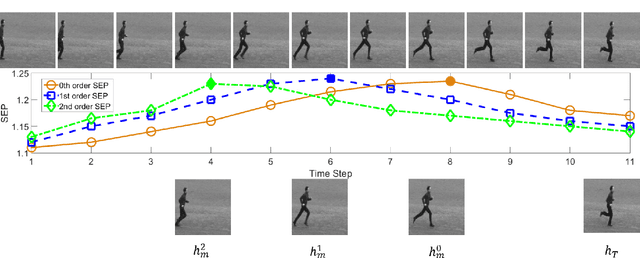
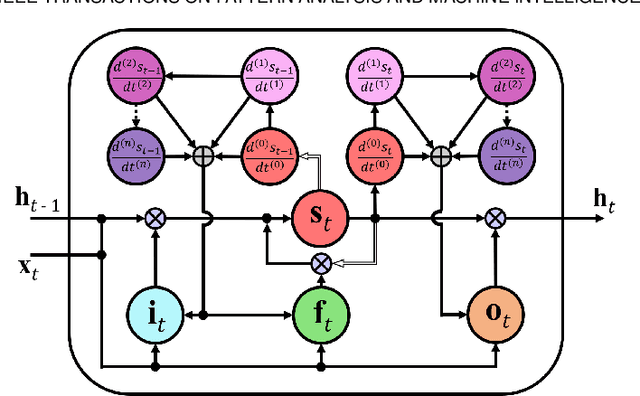

The Long Short-Term Memory (LSTM) recurrent neural network is capable of processing complex sequential information since it utilizes special gating schemes for learning representations from long input sequences. It has the potential to model any sequential time-series data, where the current hidden state has to be considered in the context of the past hidden states. This property makes LSTM an ideal choice to learn the complex dynamics present in long sequences. Unfortunately, the conventional LSTMs do not consider the impact of spatio-temporal dynamics corresponding to the given salient motion patterns, when they gate the information that ought to be memorized through time. To address this problem, we propose a differential gating scheme for the LSTM neural network, which emphasizes on the change in information gain caused by the salient motions between the successive video frames. This change in information gain is quantified by Derivative of States (DoS), and thus the proposed LSTM model is termed as differential Recurrent Neural Network (dRNN). In addition, the original work used the hidden state at the last time-step to model the entire video sequence. Based on the energy profiling of DoS, we further propose to employ the State Energy Profile (SEP) to search for salient dRNN states and construct more informative representations. The effectiveness of the proposed model was demonstrated by automatically recognizing human actions from the real-world 2D and 3D single-person action datasets. We point out that LSTM is a special form of dRNN. As a result, we have introduced a new family of LSTMs. Our study is one of the first works towards demonstrating the potential of learning complex time-series representations via high-order derivatives of states.
Syntactic Recurrent Neural Network for Authorship Attribution
Feb 27, 2019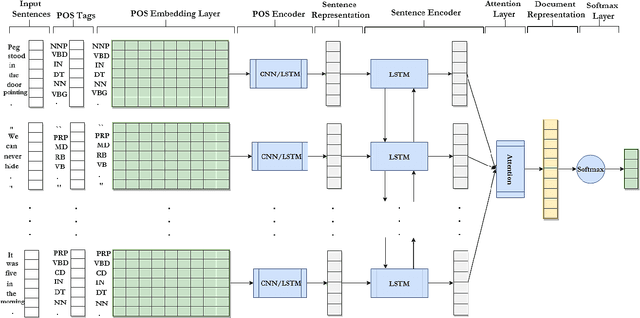
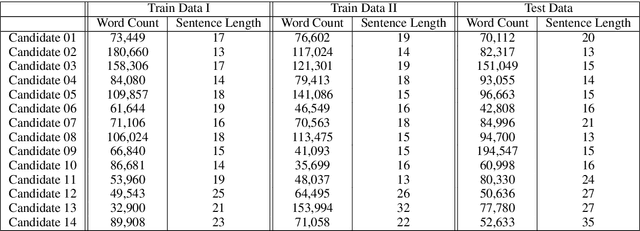
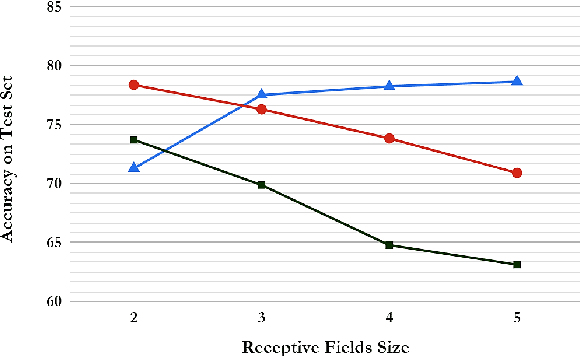
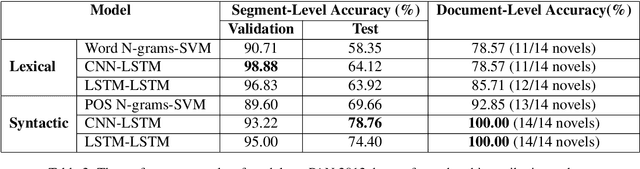
Writing style is a combination of consistent decisions at different levels of language production including lexical, syntactic, and structural associated to a specific author (or author groups). While lexical-based models have been widely explored in style-based text classification, relying on content makes the model less scalable when dealing with heterogeneous data comprised of various topics. On the other hand, syntactic models which are content-independent, are more robust against topic variance. In this paper, we introduce a syntactic recurrent neural network to encode the syntactic patterns of a document in a hierarchical structure. The model first learns the syntactic representation of sentences from the sequence of part-of-speech tags. For this purpose, we exploit both convolutional filters and long short-term memories to investigate the short-term and long-term dependencies of part-of-speech tags in the sentences. Subsequently, the syntactic representations of sentences are aggregated into document representation using recurrent neural networks. Our experimental results on PAN 2012 dataset for authorship attribution task shows that syntactic recurrent neural network outperforms the lexical model with the identical architecture by approximately 14% in terms of accuracy.
Deep Segment Hash Learning for Music Generation
May 30, 2018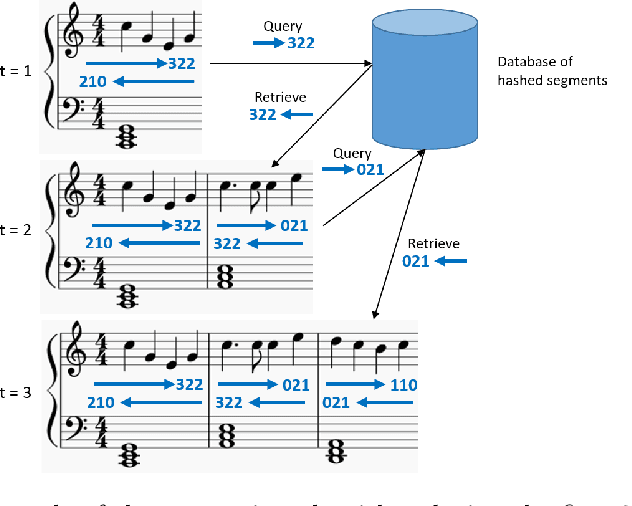
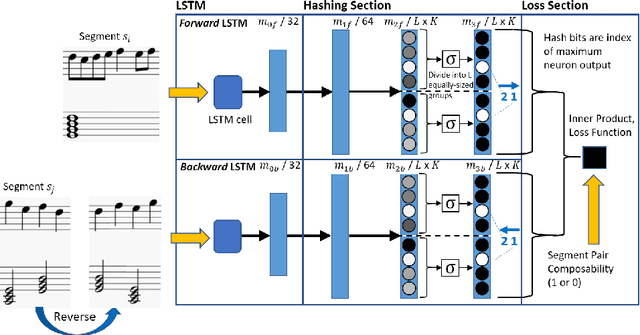
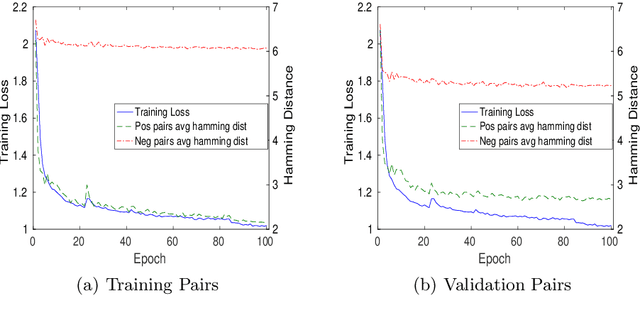

Music generation research has grown in popularity over the past decade, thanks to the deep learning revolution that has redefined the landscape of artificial intelligence. In this paper, we propose a novel approach to music generation inspired by musical segment concatenation methods and hash learning algorithms. Given a segment of music, we use a deep recurrent neural network and ranking-based hash learning to assign a forward hash code to the segment to retrieve candidate segments for continuation with matching backward hash codes. The proposed method is thus called Deep Segment Hash Learning (DSHL). To the best of our knowledge, DSHL is the first end-to-end segment hash learning method for music generation, and the first to use pair-wise training with segments of music. We demonstrate that this method is capable of generating music which is both original and enjoyable, and that DSHL offers a promising new direction for music generation research.
Toward Extractive Summarization of Online Forum Discussions via Hierarchical Attention Networks
May 25, 2018
Forum threads are lengthy and rich in content. Concise thread summaries will benefit both newcomers seeking information and those who participate in the discussion. Few studies, however, have examined the task of forum thread summarization. In this work we make the first attempt to adapt the hierarchical attention networks for thread summarization. The model draws on the recent development of neural attention mechanisms to build sentence and thread representations and use them for summarization. Our results indicate that the proposed approach can outperform a range of competitive baselines. Further, a redundancy removal step is crucial for achieving outstanding results.
Deep Differential Recurrent Neural Networks
Apr 11, 2018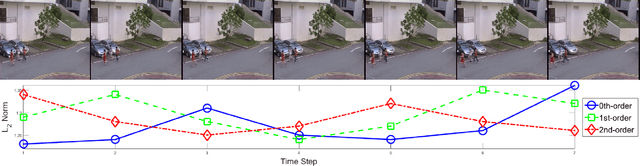

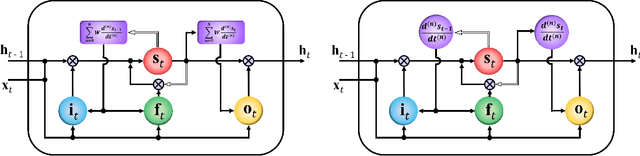
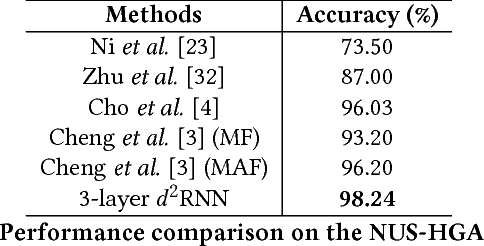
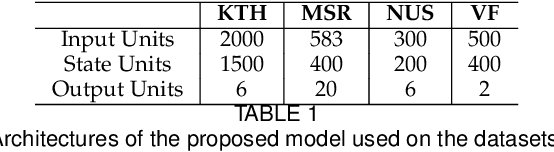
Due to the special gating schemes of Long Short-Term Memory (LSTM), LSTMs have shown greater potential to process complex sequential information than the traditional Recurrent Neural Network (RNN). The conventional LSTM, however, fails to take into consideration the impact of salient spatio-temporal dynamics present in the sequential input data. This problem was first addressed by the differential Recurrent Neural Network (dRNN), which uses a differential gating scheme known as Derivative of States (DoS). DoS uses higher orders of internal state derivatives to analyze the change in information gain caused by the salient motions between the successive frames. The weighted combination of several orders of DoS is then used to modulate the gates in dRNN. While each individual order of DoS is good at modeling a certain level of salient spatio-temporal sequences, the sum of all the orders of DoS could distort the detected motion patterns. To address this problem, we propose to control the LSTM gates via individual orders of DoS and stack multiple levels of LSTM cells in an increasing order of state derivatives. The proposed model progressively builds up the ability of the LSTM gates to detect salient dynamical patterns in deeper stacked layers modeling higher orders of DoS, and thus the proposed LSTM model is termed deep differential Recurrent Neural Network (d2RNN). The effectiveness of the proposed model is demonstrated on two publicly available human activity datasets: NUS-HGA and Violent-Flows. The proposed model outperforms both LSTM and non-LSTM based state-of-the-art algorithms.
First-Take-All: Temporal Order-Preserving Hashing for 3D Action Videos
Jun 06, 2015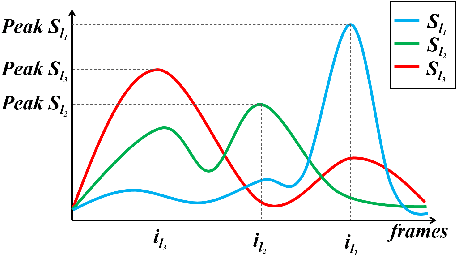
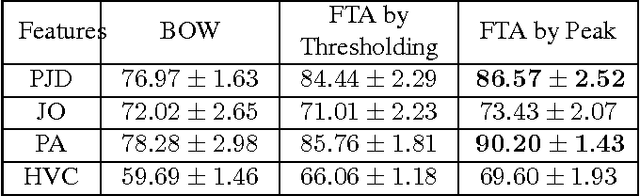
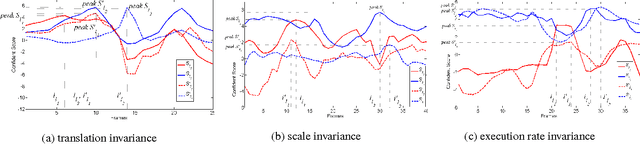
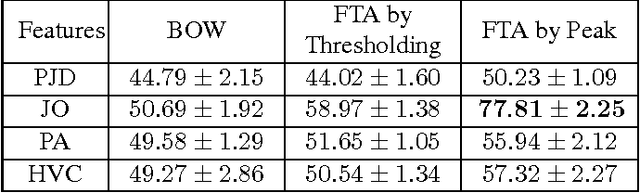
With the prevalence of the commodity depth cameras, the new paradigm of user interfaces based on 3D motion capturing and recognition have dramatically changed the way of interactions between human and computers. Human action recognition, as one of the key components in these devices, plays an important role to guarantee the quality of user experience. Although the model-driven methods have achieved huge success, they cannot provide a scalable solution for efficiently storing, retrieving and recognizing actions in the large-scale applications. These models are also vulnerable to the temporal translation and warping, as well as the variations in motion scales and execution rates. To address these challenges, we propose to treat the 3D human action recognition as a video-level hashing problem and propose a novel First-Take-All (FTA) Hashing algorithm capable of hashing the entire video into hash codes of fixed length. We demonstrate that this FTA algorithm produces a compact representation of the video invariant to the above mentioned variations, through which action recognition can be solved by an efficient nearest neighbor search by the Hamming distance between the FTA hash codes. Experiments on the public 3D human action datasets shows that the FTA algorithm can reach a recognition accuracy higher than 80%, with about 15 bits per frame considering there are 65 frames per video over the datasets.