 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing AI-Driven Education: Integrating Cognitive Frameworks, Linguistic Feedback Analysis, and Ethical Considerations for Improved Content Generation
May 01, 2025Artificial intelligence (AI) is rapidly transforming education, presenting unprecedented opportunities for personalized learning and streamlined content creation. However, realizing the full potential of AI in educational settings necessitates careful consideration of the quality, cognitive depth, and ethical implications of AI-generated materials. This paper synthesizes insights from four related studies to propose a comprehensive framework for enhancing AI-driven educational tools. We integrate cognitive assessment frameworks (Bloom's Taxonomy and SOLO Taxonomy), linguistic analysis of AI-generated feedback, and ethical design principles to guide the development of effective and responsible AI tools. We outline a structured three-phase approach encompassing cognitive alignment, linguistic feedback integration, and ethical safeguards. The practical application of this framework is demonstrated through its integration into OneClickQuiz, an AI-powered Moodle plugin for quiz generation. This work contributes a comprehensive and actionable guide for educators, researchers, and developers aiming to harness AI's potential while upholding pedagogical and ethical standards in educational content generation.
Improving Online Forums Summarization via Unifying Hierarchical Attention Networks with Convolutional Neural Networks
Mar 25, 2021
Online discussion forums are prevalent and easily accessible, thus allowing people to share ideas and opinions by posting messages in the discussion threads. Forum threads that significantly grow in length can become difficult for participants, both newcomers and existing, to grasp main ideas. This study aims to create an automatic text summarizer for online forums to mitigate this problem. We present a framework based on hierarchical attention networks, unifying Bidirectional Long Short-Term Memory (Bi-LSTM) and Convolutional Neural Network (CNN) to build sentence and thread representations for the forum summarization. In this scheme, Bi-LSTM derives a representation that comprises information of the whole sentence and whole thread; whereas, CNN recognizes high-level patterns of dominant units with respect to the sentence and thread context. The attention mechanism is applied on top of CNN to further highlight the high-level representations that capture any important units contributing to a desirable summary. Extensive performance evaluation based on three datasets, two of which are real-life online forums and one is news dataset, reveals that the proposed model outperforms several competitive baselines.
Attention Based Neural Architecture for Rumor Detection with Author Context Awareness
Sep 19, 2019

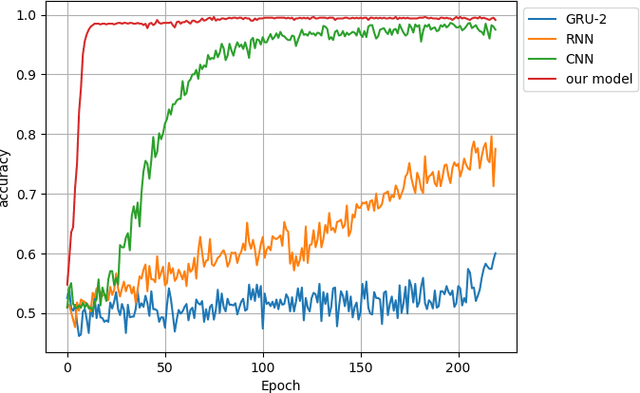

The prevalence of social media has made information sharing possible across the globe. The downside, unfortunately, is the wide spread of misinformation. Methods applied in most previous rumor classifiers give an equal weight, or attention, to words in the microblog, and do not take the context beyond microblog contents into account; therefore, the accuracy becomes plateaued. In this research, we propose an ensemble neural architecture to detect rumor on Twitter. The architecture incorporates word attention and context from the author to enhance the classification performance. In particular, the word-level attention mechanism enables the architecture to put more emphasis on important words when constructing the text representation. To derive further context, microblog posts composed by individual authors are exploited since they can reflect style and characteristics in spreading information, which are significant cues to help classify whether the shared content is rumor or legitimate news. The experiment on the real-world Twitter dataset collected from two well-known rumor tracking websites demonstrates promising results.
Syntactic Recurrent Neural Network for Authorship Attribution
Feb 27, 2019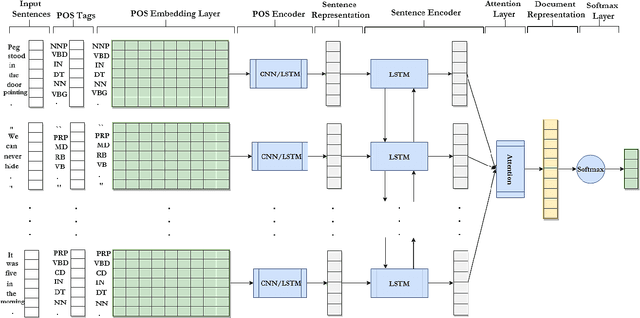
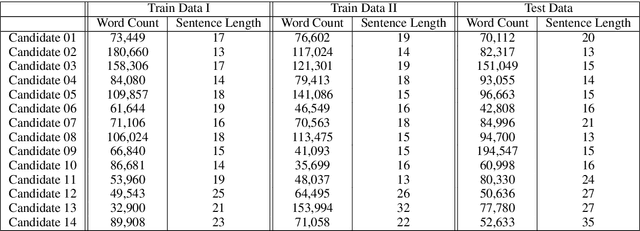
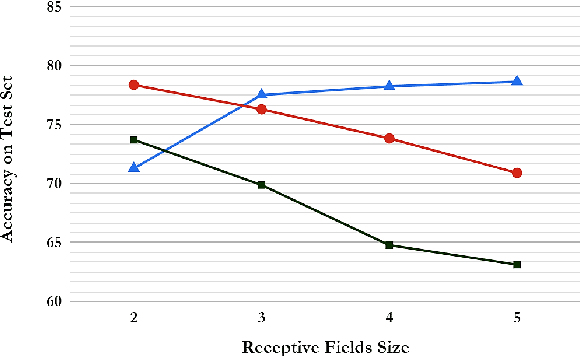
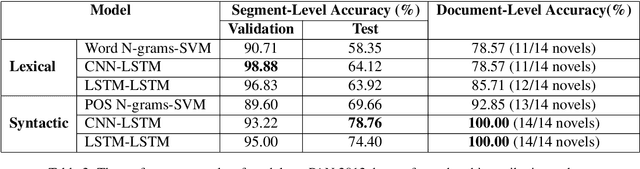
Writing style is a combination of consistent decisions at different levels of language production including lexical, syntactic, and structural associated to a specific author (or author groups). While lexical-based models have been widely explored in style-based text classification, relying on content makes the model less scalable when dealing with heterogeneous data comprised of various topics. On the other hand, syntactic models which are content-independent, are more robust against topic variance. In this paper, we introduce a syntactic recurrent neural network to encode the syntactic patterns of a document in a hierarchical structure. The model first learns the syntactic representation of sentences from the sequence of part-of-speech tags. For this purpose, we exploit both convolutional filters and long short-term memories to investigate the short-term and long-term dependencies of part-of-speech tags in the sentences. Subsequently, the syntactic representations of sentences are aggregated into document representation using recurrent neural networks. Our experimental results on PAN 2012 dataset for authorship attribution task shows that syntactic recurrent neural network outperforms the lexical model with the identical architecture by approximately 14% in terms of accuracy.
Toward Extractive Summarization of Online Forum Discussions via Hierarchical Attention Networks
May 25, 2018
Forum threads are lengthy and rich in content. Concise thread summaries will benefit both newcomers seeking information and those who participate in the discussion. Few studies, however, have examined the task of forum thread summarization. In this work we make the first attempt to adapt the hierarchical attention networks for thread summarization. The model draws on the recent development of neural attention mechanisms to build sentence and thread representations and use them for summarization. Our results indicate that the proposed approach can outperform a range of competitive baselines. Further, a redundancy removal step is crucial for achieving outstanding results.