 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Online Forums Summarization via Unifying Hierarchical Attention Networks with Convolutional Neural Networks
Mar 25, 2021
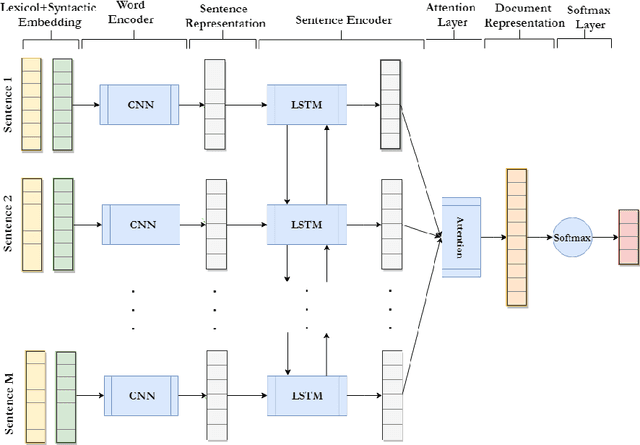
Online discussion forums are prevalent and easily accessible, thus allowing people to share ideas and opinions by posting messages in the discussion threads. Forum threads that significantly grow in length can become difficult for participants, both newcomers and existing, to grasp main ideas. This study aims to create an automatic text summarizer for online forums to mitigate this problem. We present a framework based on hierarchical attention networks, unifying Bidirectional Long Short-Term Memory (Bi-LSTM) and Convolutional Neural Network (CNN) to build sentence and thread representations for the forum summarization. In this scheme, Bi-LSTM derives a representation that comprises information of the whole sentence and whole thread; whereas, CNN recognizes high-level patterns of dominant units with respect to the sentence and thread context. The attention mechanism is applied on top of CNN to further highlight the high-level representations that capture any important units contributing to a desirable summary. Extensive performance evaluation based on three datasets, two of which are real-life online forums and one is news dataset, reveals that the proposed model outperforms several competitive baselines.
A Self-supervised Representation Learning of Sentence Structure for Authorship Attribution
Oct 14, 2020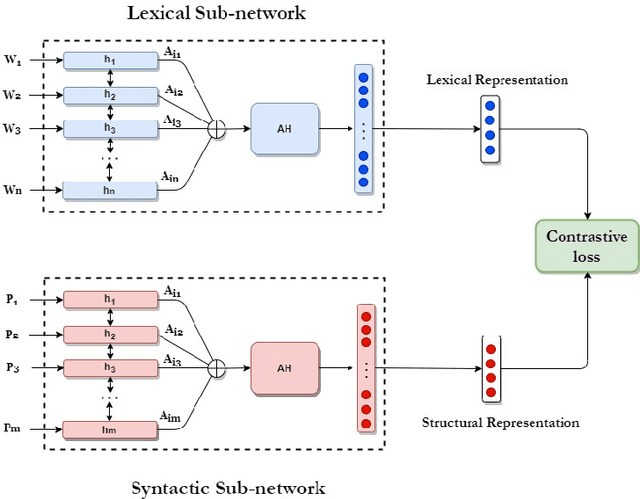
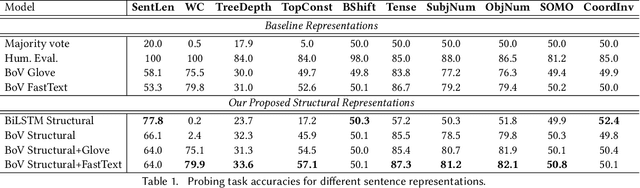
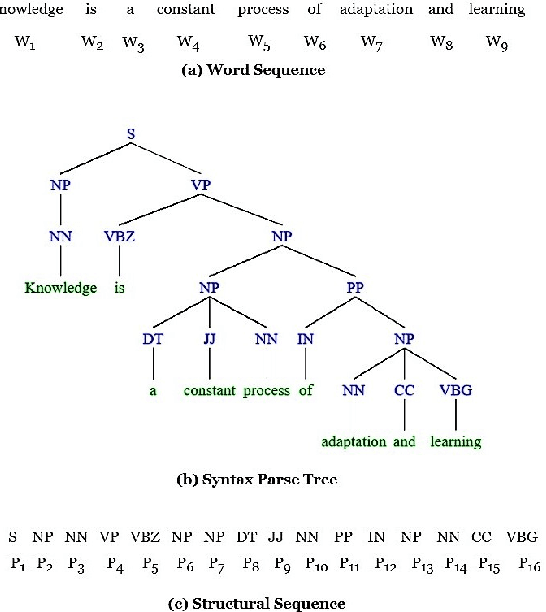
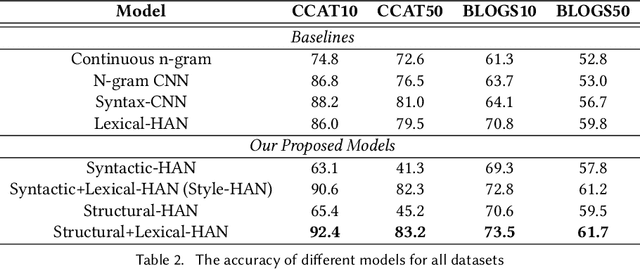
Syntactic structure of sentences in a document substantially informs about its authorial writing style. Sentence representation learning has been widely explored in recent years and it has been shown that it improves the generalization of different downstream tasks across many domains. Even though utilizing probing methods in several studies suggests that these learned contextual representations implicitly encode some amount of syntax, explicit syntactic information further improves the performance of deep neural models in the domain of authorship attribution. These observations have motivated us to investigate the explicit representation learning of syntactic structure of sentences. In this paper, we propose a self-supervised framework for learning structural representations of sentences. The self-supervised network contains two components; a lexical sub-network and a syntactic sub-network which take the sequence of words and their corresponding structural labels as the input, respectively. Due to the n-to-1 mapping of words to their structural labels, each word will be embedded into a vector representation which mainly carries structural information. We evaluate the learned structural representations of sentences using different probing tasks, and subsequently utilize them in the authorship attribution task. Our experimental results indicate that the structural embeddings significantly improve the classification tasks when concatenated with the existing pre-trained word embeddings.
Style-aware Neural Model with Application in Authorship Attribution
Sep 12, 2019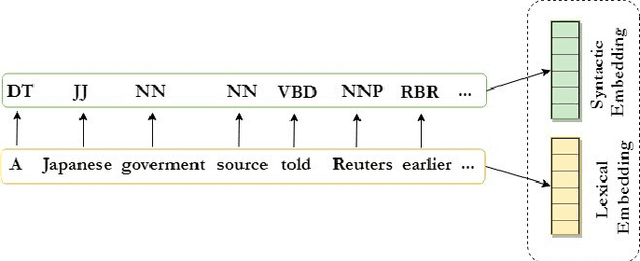
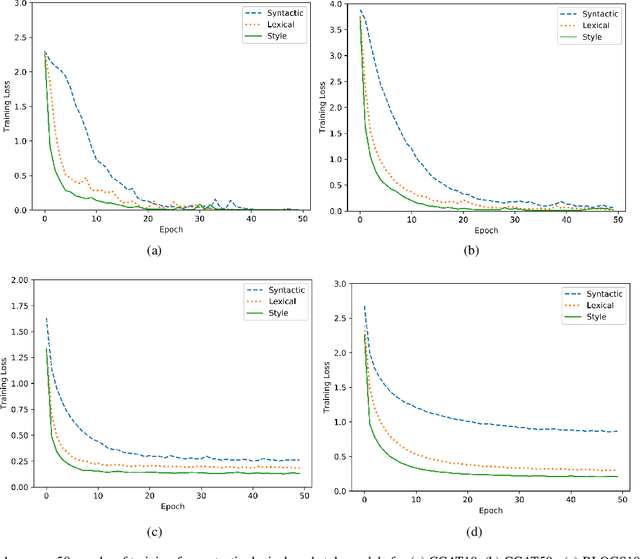
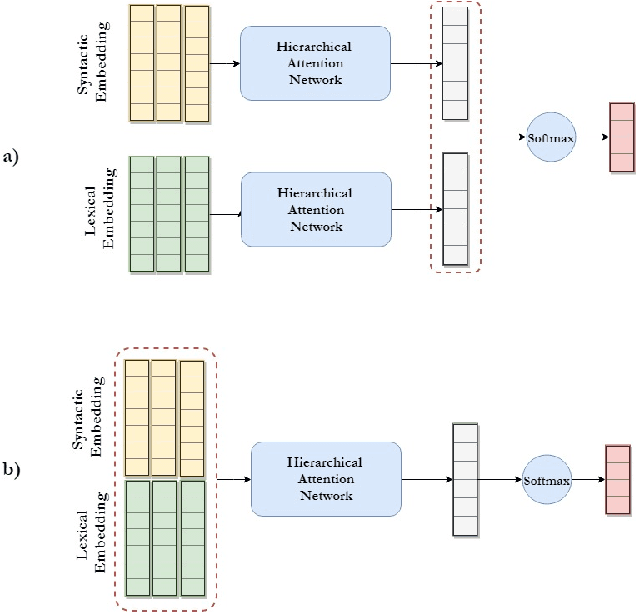
Writing style is a combination of consistent decisions associated with a specific author at different levels of language production, including lexical, syntactic, and structural. In this paper, we introduce a style-aware neural model to encode document information from three stylistic levels and evaluate it in the domain of authorship attribution. First, we propose a simple way to jointly encode syntactic and lexical representations of sentences. Subsequently, we employ an attention-based hierarchical neural network to encode the syntactic and semantic structure of sentences in documents while rewarding the sentences which contribute more to capturing the writing style. Our experimental results, based on four benchmark datasets, reveal the benefits of encoding document information from all three stylistic levels when compared to the baseline methods in the literature.
Syntactic Recurrent Neural Network for Authorship Attribution
Feb 27, 2019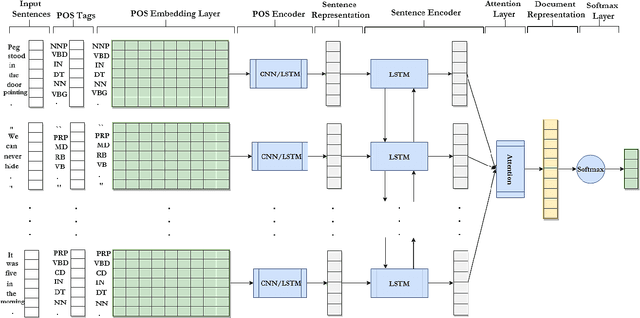
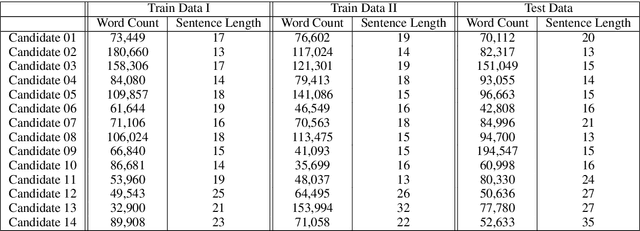
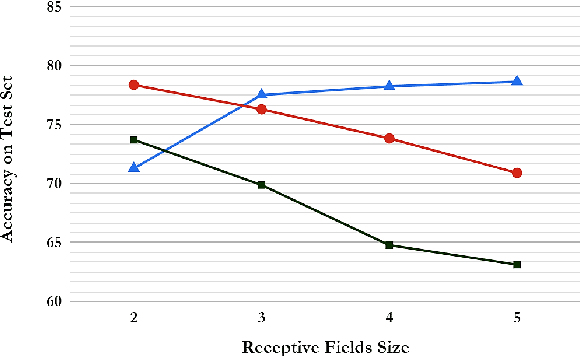
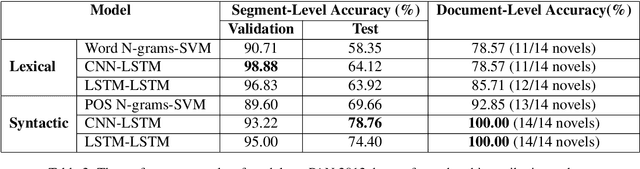
Writing style is a combination of consistent decisions at different levels of language production including lexical, syntactic, and structural associated to a specific author (or author groups). While lexical-based models have been widely explored in style-based text classification, relying on content makes the model less scalable when dealing with heterogeneous data comprised of various topics. On the other hand, syntactic models which are content-independent, are more robust against topic variance. In this paper, we introduce a syntactic recurrent neural network to encode the syntactic patterns of a document in a hierarchical structure. The model first learns the syntactic representation of sentences from the sequence of part-of-speech tags. For this purpose, we exploit both convolutional filters and long short-term memories to investigate the short-term and long-term dependencies of part-of-speech tags in the sentences. Subsequently, the syntactic representations of sentences are aggregated into document representation using recurrent neural networks. Our experimental results on PAN 2012 dataset for authorship attribution task shows that syntactic recurrent neural network outperforms the lexical model with the identical architecture by approximately 14% in terms of accuracy.