 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINOv2 Driven Gait Representation Learning for Video-Based Visible-Infrared Person Re-identification
Nov 06, 2025Video-based Visible-Infrared person re-identification (VVI-ReID) aims to retrieve the same pedestrian across visible and infrared modalities from video sequences. Existing methods tend to exploit modality-invariant visual features but largely overlook gait features, which are not only modality-invariant but also rich in temporal dynamics, thus limiting their ability to model the spatiotemporal consistency essential for cross-modal video matching. To address these challenges, we propose a DINOv2-Driven Gait Representation Learning (DinoGRL) framework that leverages the rich visual priors of DINOv2 to learn gait features complementary to appearance cues, facilitating robust sequence-level representations for cross-modal retrieval. Specifically, we introduce a Semantic-Aware Silhouette and Gait Learning (SASGL) model, which generates and enhances silhouette representations with general-purpose semantic priors from DINOv2 and jointly optimizes them with the ReID objective to achieve semantically enriched and task-adaptive gait feature learning. Furthermore, we develop a Progressive Bidirectional Multi-Granularity Enhancement (PBMGE) module, which progressively refines feature representations by enabling bidirectional interactions between gait and appearance streams across multiple spatial granularities, fully leveraging their complementarity to enhance global representations with rich local details and produce highly discriminative features. Extensive experiments on HITSZ-VCM and BUPT datasets demonstrate the superiority of our approach, significantly outperforming existing state-of-the-art methods.
Enhancing the Generalization Capability of Skin Lesion Classification Models with Active Domain Adaptation Methods
Dec 01, 2024



We propose a method to improve the generalization ability of skin lesion classification models by combining self-supervised learning (SSL), unsupervised domain adaptation (UDA), and active domain adaptation (ADA). The main steps of the approach include selection of a SSL pretrained model on natural image datasets, subsequent SSL retraining on all available skin lesion datasets, finetuning of the model on source domain data with labels, application of UDA methods on target domain data, and lastly, implementation of ADA methods. The efficacy of the proposed approach is assessed across ten skin lesion datasets of domains, demonstrating its potential for enhancing the performance of skin lesion classification models. This approach holds promise for facilitating the widespread adoption of medical imaging models in clinical settings, thereby amplifying their impact.
Frequency comb and machine learning-based breath analysis for COVID-19 classification
Feb 04, 2022Human breath contains hundreds of volatile molecules that can provide powerful, non-intrusive spectral diagnosis of a diverse set of diseases and physiological/metabolic states. To unleash this tremendous potential for medical science, we present a robust analytical method that simultaneously measures tens of thousands of spectral features in each breath sample, followed by efficient and detail-specific multivariate data analysis for unambiguous binary medical response classification. We combine mid-infrared cavity-enhanced direct frequency comb spectroscopy (CE-DFCS), capable of real-time collection of tens of thousands of distinct molecular features at parts-per-trillion sensitivity, with supervised machine learning, capable of analysis and verification of extremely high-dimensional input data channels. Here, we present the first application of this method to the breath detection of Coronavirus Disease 2019 (COVID-19). Using 170 individual samples at the University of Colorado, we report a cross-validated area under the Receiver-Operating-Characteristics curve of 0.849(4), providing excellent prediction performance. Further, this method detected a significant difference between male and female breath as well as other variables such as smoking and abdominal pain. Together, these highlight the utility of CE-DFCS for rapid, non-invasive detection of diverse biological conditions and disease states. The unique properties of frequency comb spectroscopy thus help establish precise digital spectral fingerprints for building accurate databases and provide means for simultaneous multi-response classifications. The predictive power can be further enhanced with readily scalable comb spectral coverage.
Accelerate RNN-based Training with Importance Sampling
Oct 31, 2017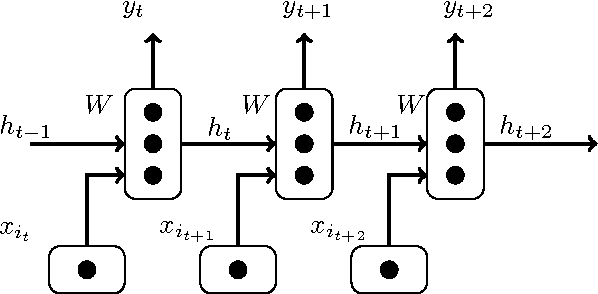
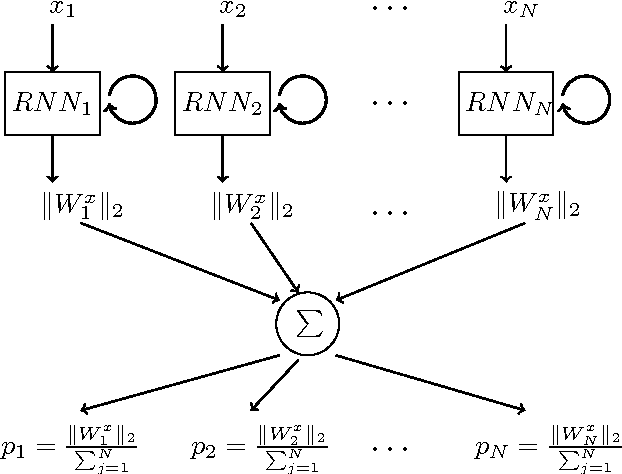
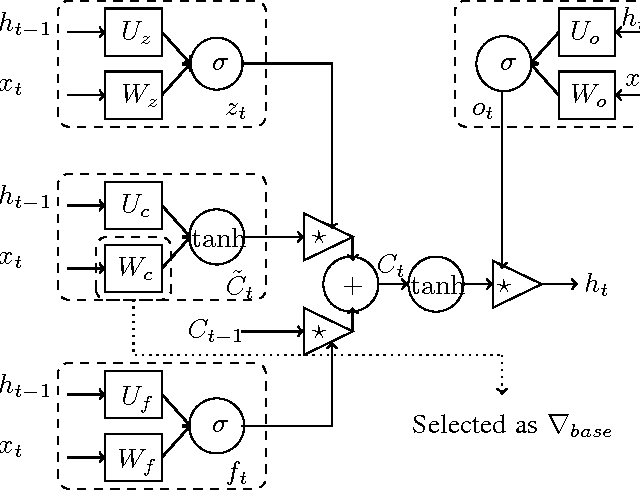
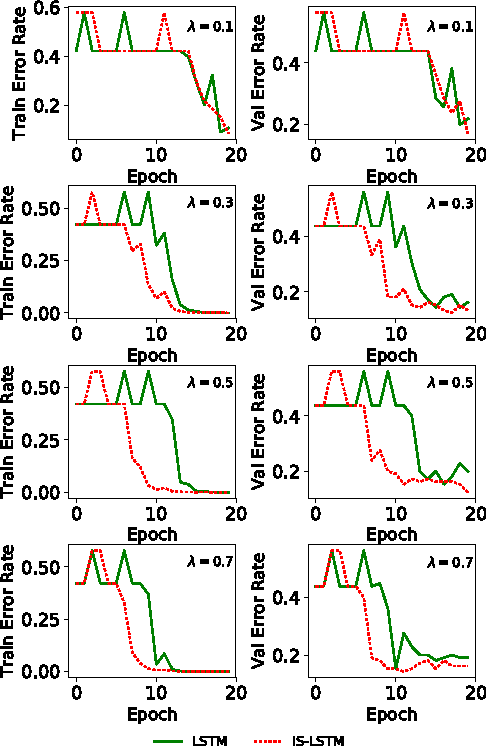
Importance sampling (IS) as an elegant and efficient variance reduction (VR) technique for the acceleration of stochastic optimization problems has attracted many researches recently. Unlike commonly adopted stochastic uniform sampling in stochastic optimizations, IS-integrated algorithms sample training data at each iteration with respect to a weighted sampling probability distribution $P$, which is constructed according to the precomputed importance factors. Previous experimental results show that IS has achieved remarkable progresses in the acceleration of training convergence. Unfortunately, the calculation of the sampling probability distribution $P$ causes a major limitation of IS: it requires the input data to be well-structured, i.e., the feature vector is properly defined. Consequently, recurrent neural networks (RNN) as a popular learning algorithm is not able to enjoy the benefits of IS due to the fact that its raw input data, i.e., the training sequences, are often unstructured which makes calculation of $P$ impossible. In considering of the the popularity of RNN-based learning applications and their relative long training time, we are interested in accelerating them through IS. This paper propose a novel Fast-Importance-Mining algorithm to calculate the importance factor for unstructured data which makes the application of IS in RNN-based applications possible. Our experimental evaluation on popular open-source RNN-based learning applications validate the effectiveness of IS in improving the convergence rate of RNNs.
First-Take-All: Temporal Order-Preserving Hashing for 3D Action Videos
Jun 06, 2015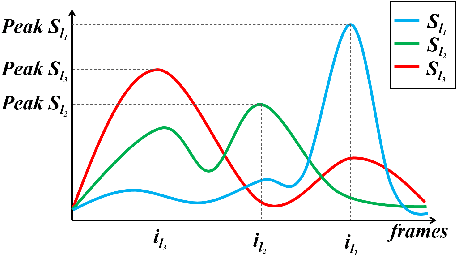
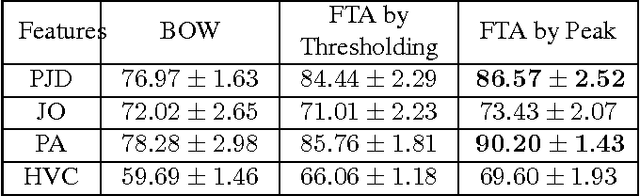
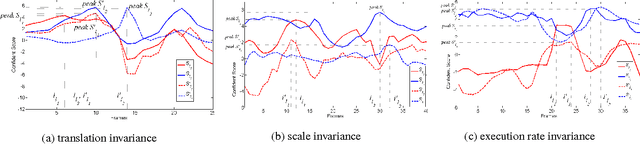
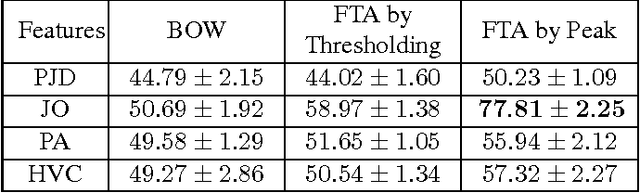
With the prevalence of the commodity depth cameras, the new paradigm of user interfaces based on 3D motion capturing and recognition have dramatically changed the way of interactions between human and computers. Human action recognition, as one of the key components in these devices, plays an important role to guarantee the quality of user experience. Although the model-driven methods have achieved huge success, they cannot provide a scalable solution for efficiently storing, retrieving and recognizing actions in the large-scale applications. These models are also vulnerable to the temporal translation and warping, as well as the variations in motion scales and execution rates. To address these challenges, we propose to treat the 3D human action recognition as a video-level hashing problem and propose a novel First-Take-All (FTA) Hashing algorithm capable of hashing the entire video into hash codes of fixed length. We demonstrate that this FTA algorithm produces a compact representation of the video invariant to the above mentioned variations, through which action recognition can be solved by an efficient nearest neighbor search by the Hamming distance between the FTA hash codes. Experiments on the public 3D human action datasets shows that the FTA algorithm can reach a recognition accuracy higher than 80%, with about 15 bits per frame considering there are 65 frames per video over the datasets.
Rank Subspace Learning for Compact Hash Codes
Mar 19, 2015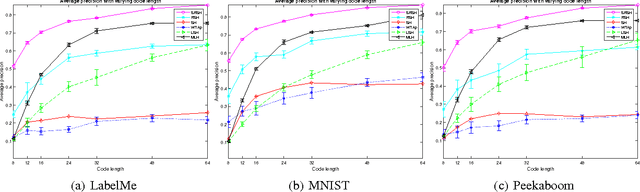
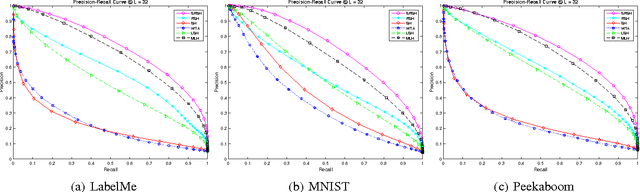

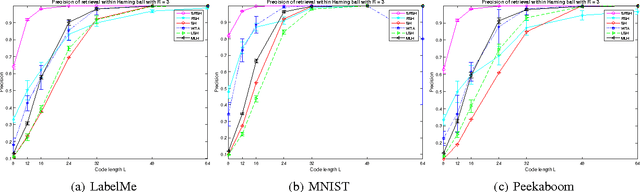
The era of Big Data has spawned unprecedented interests in developing hashing algorithms for efficient storage and fast nearest neighbor search. Most existing work learn hash functions that are numeric quantizations of feature values in projected feature space. In this work, we propose a novel hash learning framework that encodes feature's rank orders instead of numeric values in a number of optimal low-dimensional ranking subspaces. We formulate the ranking subspace learning problem as the optimization of a piece-wise linear convex-concave function and present two versions of our algorithm: one with independent optimization of each hash bit and the other exploiting a sequential learning framework. Our work is a generalization of the Winner-Take-All (WTA) hash family and naturally enjoys all the numeric stability benefits of rank correlation measures while being optimized to achieve high precision at very short code length. We compare with several state-of-the-art hashing algorithms in both supervised and unsupervised domain, showing superior performance in a number of data sets.