 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerate RNN-based Training with Importance Sampling
Paper and Code
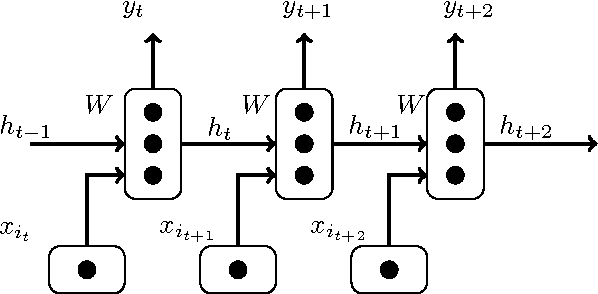
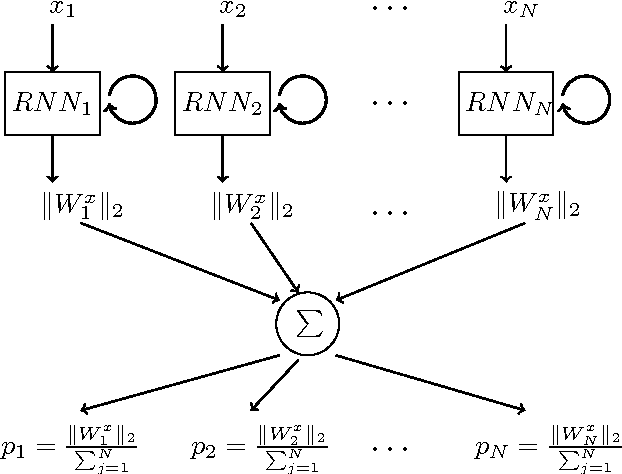
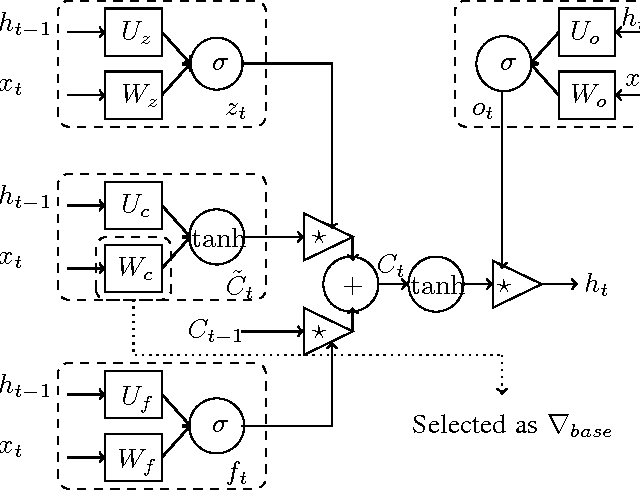
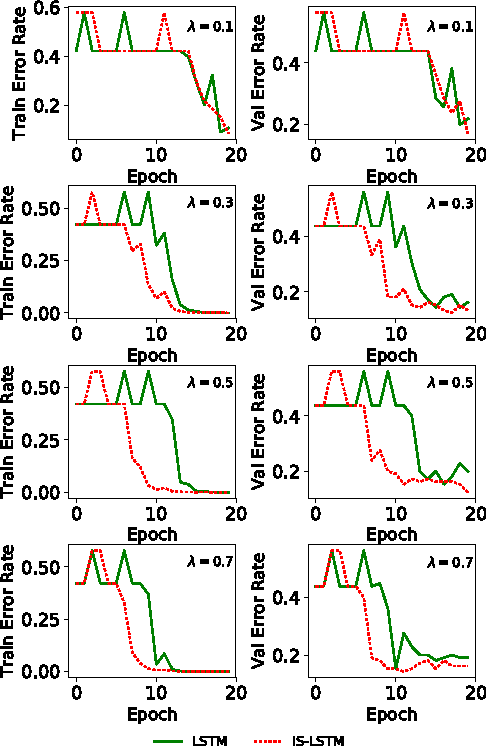
Importance sampling (IS) as an elegant and efficient variance reduction (VR) technique for the acceleration of stochastic optimization problems has attracted many researches recently. Unlike commonly adopted stochastic uniform sampling in stochastic optimizations, IS-integrated algorithms sample training data at each iteration with respect to a weighted sampling probability distribution $P$, which is constructed according to the precomputed importance factors. Previous experimental results show that IS has achieved remarkable progresses in the acceleration of training convergence. Unfortunately, the calculation of the sampling probability distribution $P$ causes a major limitation of IS: it requires the input data to be well-structured, i.e., the feature vector is properly defined. Consequently, recurrent neural networks (RNN) as a popular learning algorithm is not able to enjoy the benefits of IS due to the fact that its raw input data, i.e., the training sequences, are often unstructured which makes calculation of $P$ impossible. In considering of the the popularity of RNN-based learning applications and their relative long training time, we are interested in accelerating them through IS. This paper propose a novel Fast-Importance-Mining algorithm to calculate the importance factor for unstructured data which makes the application of IS in RNN-based applications possible. Our experimental evaluation on popular open-source RNN-based learning applications validate the effectiveness of IS in improving the convergence rate of RNNs.