 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning as Reinforcement: Applying Principles of Neuroscience for More General Reinforcement Learning Agents
Apr 20, 2020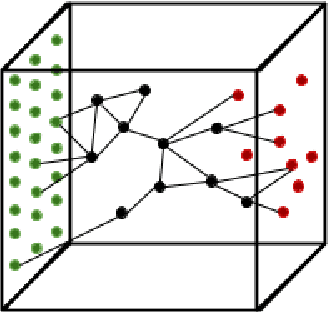

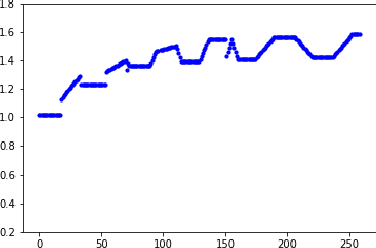
A significant challenge in developing AI that can generalize well is designing agents that learn about their world without being told what to learn, and apply that learning to challenges with sparse rewards. Moreover, most traditional reinforcement learning approaches explicitly separate learning and decision making in a way that does not correspond to biological learning. We implement an architecture founded in principles of experimental neuroscience, by combining computationally efficient abstractions of biological algorithms. Our approach is inspired by research on spike-timing dependent plasticity, the transition between short and long term memory, and the role of various neurotransmitters in rewarding curiosity. The Neurons-in-a-Box architecture can learn in a wholly generalizable manner, and demonstrates an efficient way to build and apply representations without explicitly optimizing over a set of criteria or actions. We find it performs well in many environments including OpenAI Gym's Mountain Car, which has no reward besides touching a hard-to-reach flag on a hill, Inverted Pendulum, where it learns simple strategies to improve the time it holds a pendulum up, a video stream, where it spontaneously learns to distinguish an open and closed hand, as well as other environments like Google Chrome's Dinosaur Game.
Batch Active Learning Using Determinantal Point Processes
Jun 19, 2019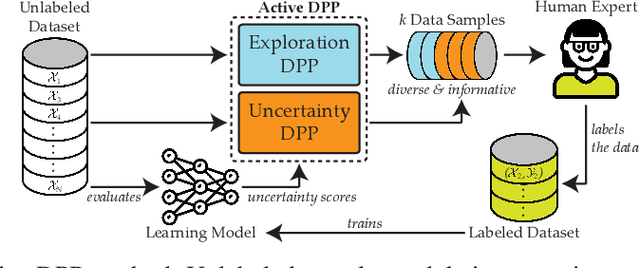

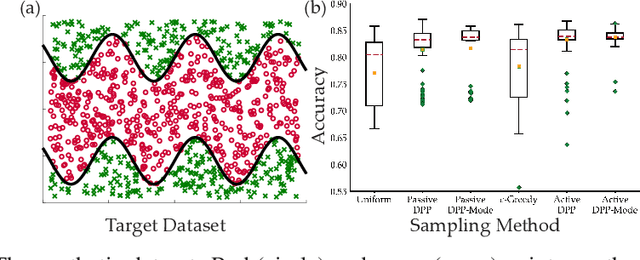
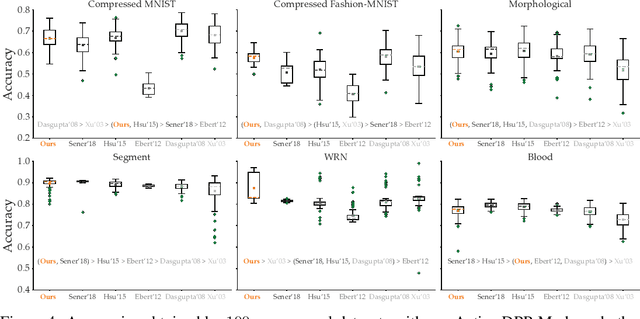
Data collection and labeling is one of the main challenges in employing machine learning algorithms in a variety of real-world applications with limited data. While active learning methods attempt to tackle this issue by labeling only the data samples that give high information, they generally suffer from large computational costs and are impractical in settings where data can be collected in parallel. Batch active learning methods attempt to overcome this computational burden by querying batches of samples at a time. To avoid redundancy between samples, previous works rely on some ad hoc combination of sample quality and diversity. In this paper, we present a new principled batch active learning method using Determinantal Point Processes, a repulsive point process that enables generating diverse batches of samples. We develop tractable algorithms to approximate the mode of a DPP distribution, and provide theoretical guarantees on the degree of approximation. We further demonstrate that an iterative greedy method for DPP maximization, which has lower computational costs but worse theoretical guarantees, still gives competitive results for batch active learning. Our experiments show the value of our methods on several datasets against state-of-the-art baselines.