 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning as Reinforcement: Applying Principles of Neuroscience for More General Reinforcement Learning Agents
Apr 20, 2020

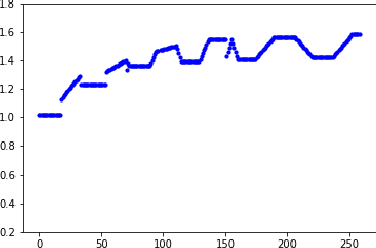
A significant challenge in developing AI that can generalize well is designing agents that learn about their world without being told what to learn, and apply that learning to challenges with sparse rewards. Moreover, most traditional reinforcement learning approaches explicitly separate learning and decision making in a way that does not correspond to biological learning. We implement an architecture founded in principles of experimental neuroscience, by combining computationally efficient abstractions of biological algorithms. Our approach is inspired by research on spike-timing dependent plasticity, the transition between short and long term memory, and the role of various neurotransmitters in rewarding curiosity. The Neurons-in-a-Box architecture can learn in a wholly generalizable manner, and demonstrates an efficient way to build and apply representations without explicitly optimizing over a set of criteria or actions. We find it performs well in many environments including OpenAI Gym's Mountain Car, which has no reward besides touching a hard-to-reach flag on a hill, Inverted Pendulum, where it learns simple strategies to improve the time it holds a pendulum up, a video stream, where it spontaneously learns to distinguish an open and closed hand, as well as other environments like Google Chrome's Dinosaur Game.
Modeling Sensorimotor Coordination as Multi-Agent Reinforcement Learning with Differentiable Communication
Sep 12, 2019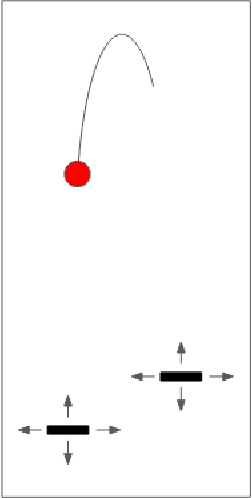
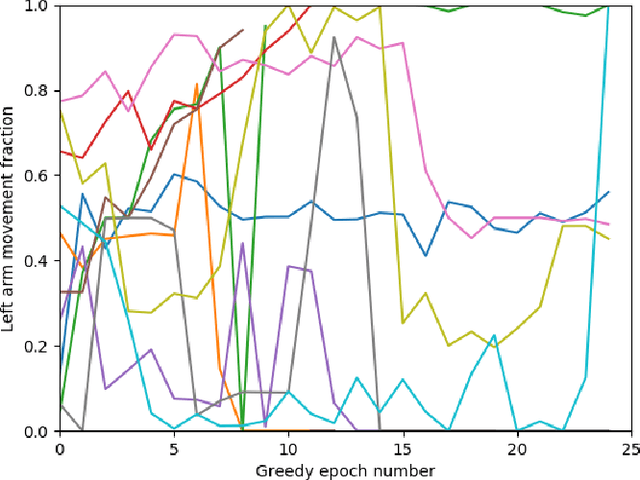
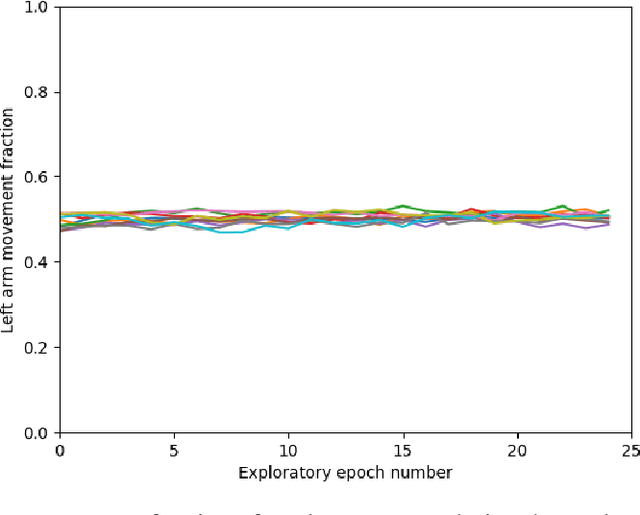
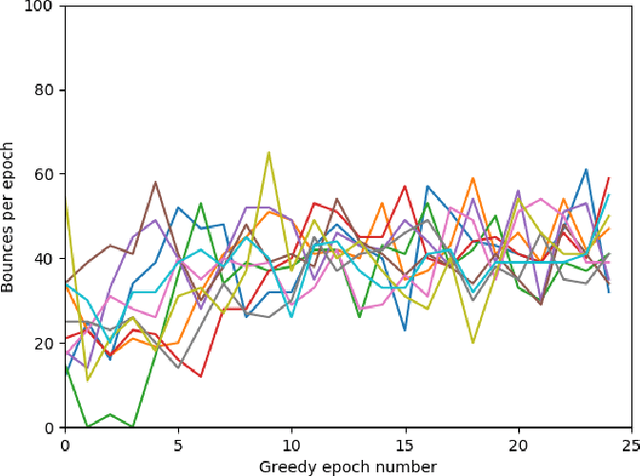
Multi-agent reinforcement learning has shown promise on a variety of cooperative tasks as a consequence of recent developments in differentiable inter-agent communication. However, most architectures are limited to pools of homogeneous agents, limiting their applicability. Here we propose a modular framework for learning complex tasks in which a traditional monolithic agent is framed as a collection of cooperating heterogeneous agents. We apply this approach to model sensorimotor coordination in the neocortex as a multi-agent reinforcement learning problem. Our results demonstrate proof-of-concept of the proposed architecture and open new avenues for learning complex tasks and for understanding functional localization in the brain and future intelligent systems.
Improving Context-Aware Semantic Relationships in Sparse Mobile Datasets
Dec 23, 2018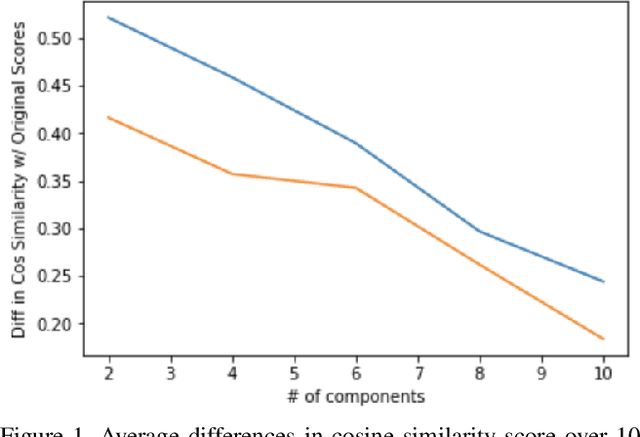
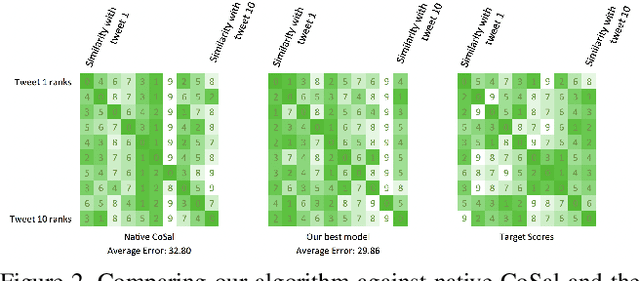
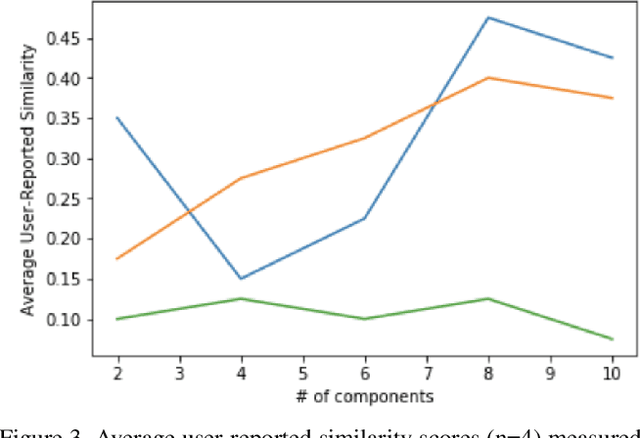
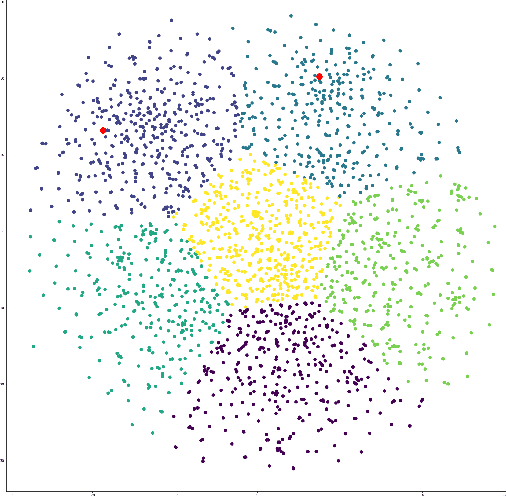
Traditional semantic similarity models often fail to encapsulate the external context in which texts are situated. However, textual datasets generated on mobile platforms can help us build a truer representation of semantic similarity by introducing multimodal data. This is especially important in sparse datasets, making solely text-driven interpretation of context more difficult. In this paper, we develop new algorithms for building external features into sentence embeddings and semantic similarity scores. Then, we test them on embedding spaces on data from Twitter, using each tweet's time and geolocation to better understand its context. Ultimately, we show that applying PCA with eight components to the embedding space and appending multimodal features yields the best outcomes. This yields a considerable improvement over pure text-based approaches for discovering similar tweets. Our results suggest that our new algorithm can help improve semantic understanding in various settings.