 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Context-Aware Semantic Relationships in Sparse Mobile Datasets
Dec 23, 2018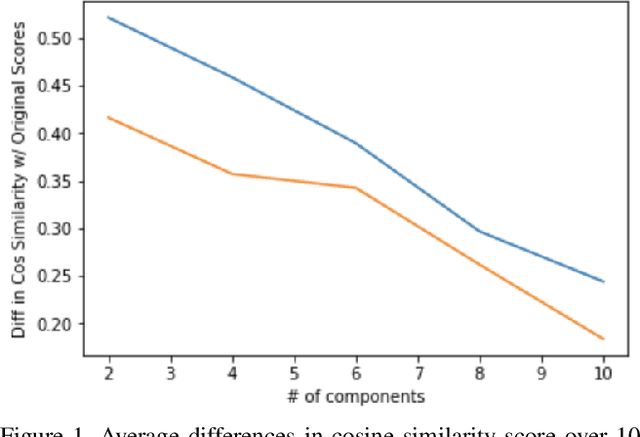
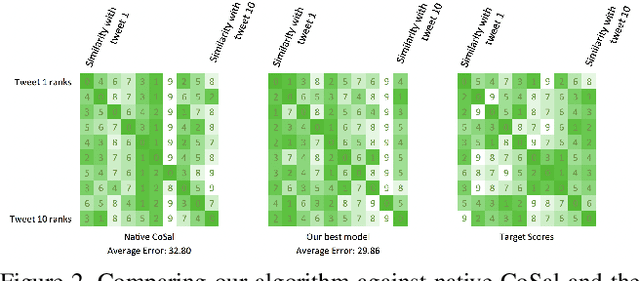
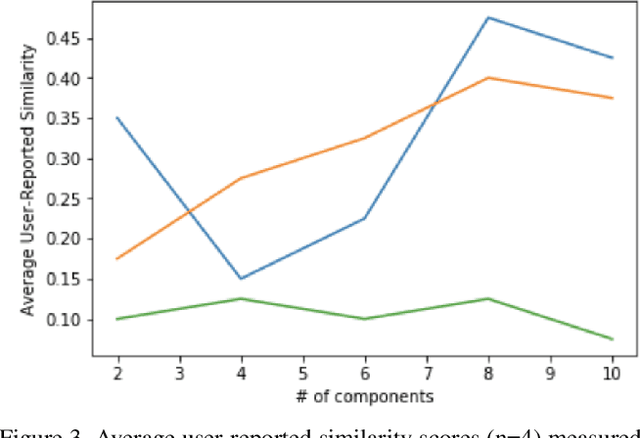
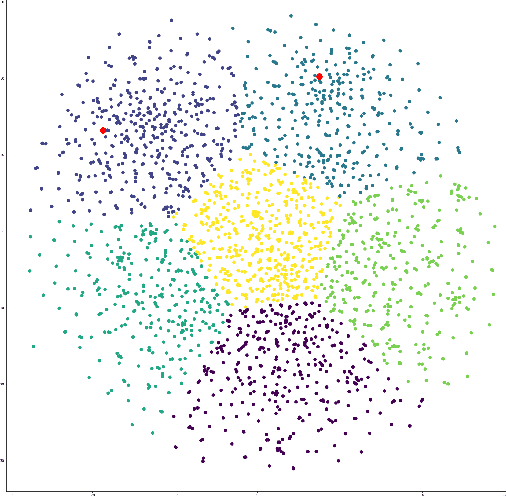
Traditional semantic similarity models often fail to encapsulate the external context in which texts are situated. However, textual datasets generated on mobile platforms can help us build a truer representation of semantic similarity by introducing multimodal data. This is especially important in sparse datasets, making solely text-driven interpretation of context more difficult. In this paper, we develop new algorithms for building external features into sentence embeddings and semantic similarity scores. Then, we test them on embedding spaces on data from Twitter, using each tweet's time and geolocation to better understand its context. Ultimately, we show that applying PCA with eight components to the embedding space and appending multimodal features yields the best outcomes. This yields a considerable improvement over pure text-based approaches for discovering similar tweets. Our results suggest that our new algorithm can help improve semantic understanding in various settings.