 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Best Practices for Open Datasets for LLM Training
Jan 14, 2025Many AI companies are training their large language models (LLMs) on data without the permission of the copyright owners. The permissibility of doing so varies by jurisdiction: in countries like the EU and Japan, this is allowed under certain restrictions, while in the United States, the legal landscape is more ambiguous. Regardless of the legal status, concerns from creative producers have led to several high-profile copyright lawsuits, and the threat of litigation is commonly cited as a reason for the recent trend towards minimizing the information shared about training datasets by both corporate and public interest actors. This trend in limiting data information causes harm by hindering transparency, accountability, and innovation in the broader ecosystem by denying researchers, auditors, and impacted individuals access to the information needed to understand AI models. While this could be mitigated by training language models on open access and public domain data, at the time of writing, there are no such models (trained at a meaningful scale) due to the substantial technical and sociological challenges in assembling the necessary corpus. These challenges include incomplete and unreliable metadata, the cost and complexity of digitizing physical records, and the diverse set of legal and technical skills required to ensure relevance and responsibility in a quickly changing landscape. Building towards a future where AI systems can be trained on openly licensed data that is responsibly curated and governed requires collaboration across legal, technical, and policy domains, along with investments in metadata standards, digitization, and fostering a culture of openness.
Improving Context-Aware Semantic Relationships in Sparse Mobile Datasets
Dec 23, 2018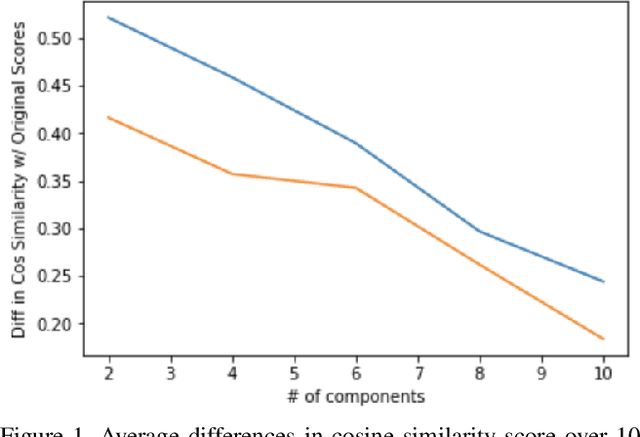
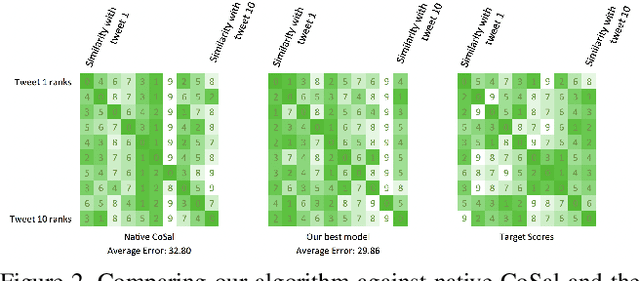
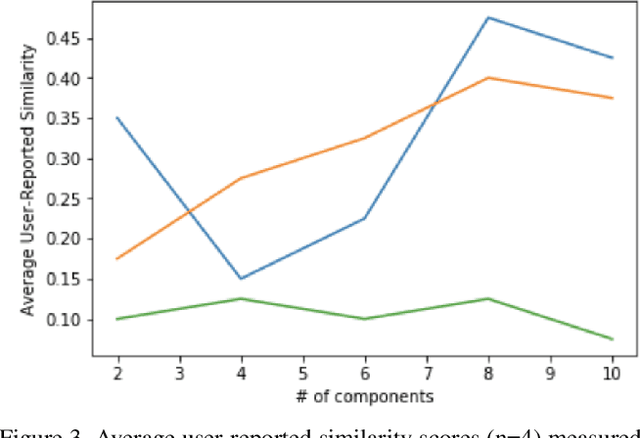
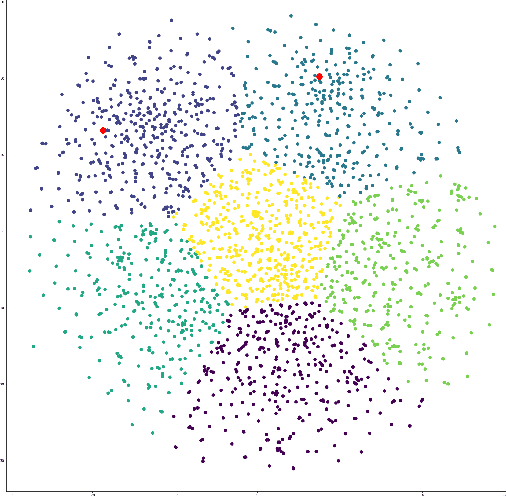
Traditional semantic similarity models often fail to encapsulate the external context in which texts are situated. However, textual datasets generated on mobile platforms can help us build a truer representation of semantic similarity by introducing multimodal data. This is especially important in sparse datasets, making solely text-driven interpretation of context more difficult. In this paper, we develop new algorithms for building external features into sentence embeddings and semantic similarity scores. Then, we test them on embedding spaces on data from Twitter, using each tweet's time and geolocation to better understand its context. Ultimately, we show that applying PCA with eight components to the embedding space and appending multimodal features yields the best outcomes. This yields a considerable improvement over pure text-based approaches for discovering similar tweets. Our results suggest that our new algorithm can help improve semantic understanding in various settings.