 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Active Learning Using Determinantal Point Processes
Paper and Code
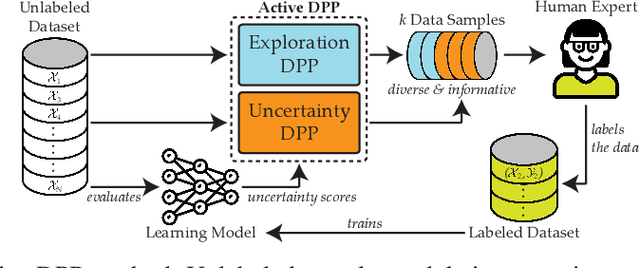

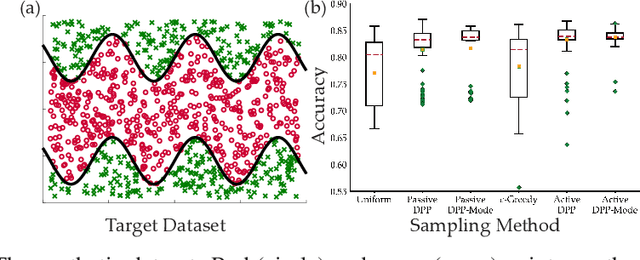
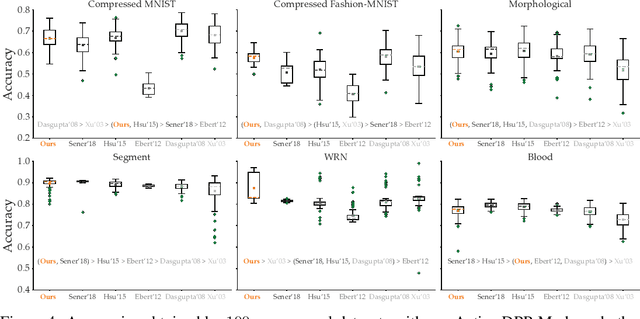
Data collection and labeling is one of the main challenges in employing machine learning algorithms in a variety of real-world applications with limited data. While active learning methods attempt to tackle this issue by labeling only the data samples that give high information, they generally suffer from large computational costs and are impractical in settings where data can be collected in parallel. Batch active learning methods attempt to overcome this computational burden by querying batches of samples at a time. To avoid redundancy between samples, previous works rely on some ad hoc combination of sample quality and diversity. In this paper, we present a new principled batch active learning method using Determinantal Point Processes, a repulsive point process that enables generating diverse batches of samples. We develop tractable algorithms to approximate the mode of a DPP distribution, and provide theoretical guarantees on the degree of approximation. We further demonstrate that an iterative greedy method for DPP maximization, which has lower computational costs but worse theoretical guarantees, still gives competitive results for batch active learning. Our experiments show the value of our methods on several datasets against state-of-the-art baselines.