 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeRB: Heterophily-Resolved Structure Balancer for Graph Neural Networks
Apr 24, 2025Recent research has witnessed the remarkable progress of Graph Neural Networks (GNNs) in the realm of graph data representation. However, GNNs still encounter the challenge of structural imbalance. Prior solutions to this problem did not take graph heterophily into account, namely that connected nodes process distinct labels or features, thus resulting in a deficiency in effectiveness. Upon verifying the impact of heterophily on solving the structural imbalance problem, we propose to rectify the heterophily first and then transfer homophilic knowledge. To the end, we devise a method named HeRB (Heterophily-Resolved Structure Balancer) for GNNs. HeRB consists of two innovative components: 1) A heterophily-lessening augmentation module which serves to reduce inter-class edges and increase intra-class edges; 2) A homophilic knowledge transfer mechanism to convey homophilic information from head nodes to tail nodes. Experimental results demonstrate that HeRB achieves superior performance on two homophilic and six heterophilic benchmark datasets, and the ablation studies further validate the efficacy of two proposed components.
HeGMN: Heterogeneous Graph Matching Network for Learning Graph Similarity
Mar 11, 2025

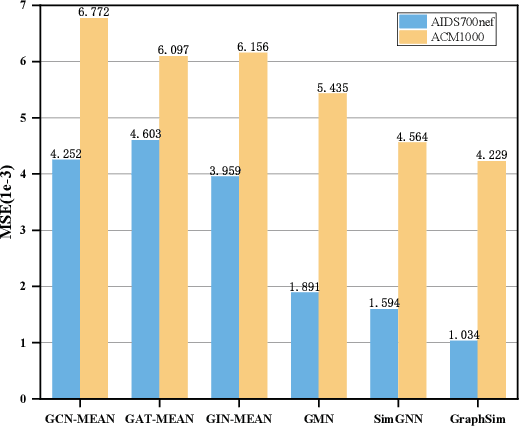
Graph similarity learning (GSL), also referred to as graph matching in many scenarios, is a fundamental problem in computer vision, pattern recognition, and graph learning. However, previous GSL methods assume that graphs are homogeneous and struggle to maintain their performance on heterogeneous graphs. To address this problem, this paper proposes a Heterogeneous Graph Matching Network (HeGMN), which is an end-to-end graph similarity learning framework composed of a two-tier matching mechanism. Firstly, a heterogeneous graph isomorphism network is proposed as the encoder, which reinvents graph isomorphism network for heterogeneous graphs by perceiving different semantic relationships during aggregation. Secondly, a graph-level and node-level matching modules are designed, both employing type-aligned matching principles. The former conducts graph-level matching by node type alignment, and the latter computes the interactions between the cross-graph nodes with the same type thus reducing noise interference and computational overhead. Finally, the graph-level and node-level matching features are combined and fed into fully connected layers for predicting graph similarity scores. In experiments, we propose a heterogeneous graph resampling method to construct heterogeneous graph pairs and define the corresponding heterogeneous graph edit distance, filling the gap in missing datasets. Extensive experiments demonstrate that HeGMN consistently achieves advanced performance on graph similarity prediction across all datasets.
Balancing Augmentation with Edge-Utility Filter for Signed GNNs
Oct 25, 2023



Signed graph neural networks (SGNNs) has recently drawn more attention as many real-world networks are signed networks containing two types of edges: positive and negative. The existence of negative edges affects the SGNN robustness on two aspects. One is the semantic imbalance as the negative edges are usually hard to obtain though they can provide potentially useful information. The other is the structural unbalance, e.g. unbalanced triangles, an indication of incompatible relationship among nodes. In this paper, we propose a balancing augmentation method to address the above two aspects for SGNNs. Firstly, the utility of each negative edge is measured by calculating its occurrence in unbalanced structures. Secondly, the original signed graph is selectively augmented with the use of (1) an edge perturbation regulator to balance the number of positive and negative edges and to determine the ratio of perturbed edges to original edges and (2) an edge utility filter to remove the negative edges with low utility to make the graph structure more balanced. Finally, a SGNN is trained on the augmented graph which effectively explores the credible relationships. A detailed theoretical analysis is also conducted to prove the effectiveness of each module. Experiments on five real-world datasets in link prediction demonstrate that our method has the advantages of effectiveness and generalization and can significantly improve the performance of SGNN backbones.
Self-Supervised Dynamic Graph Representation Learning via Temporal Subgraph Contrast
Dec 16, 2021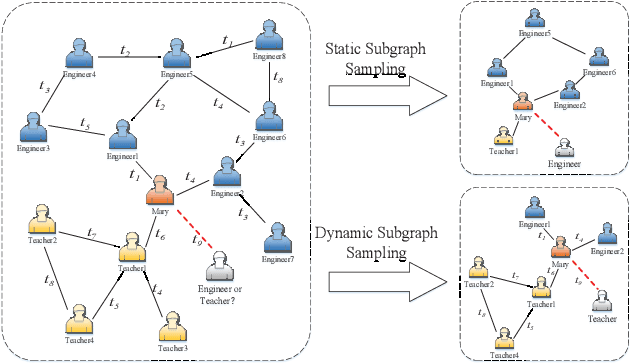

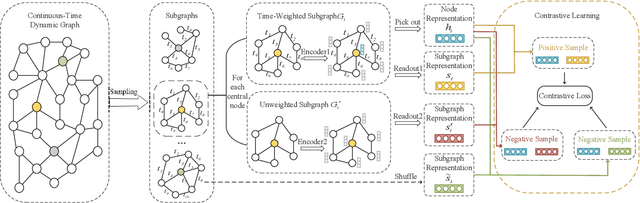
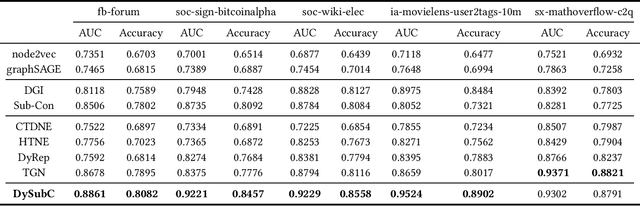
Self-supervised learning on graphs has recently drawn a lot of attention due to its independence from labels and its robustness in representation. Current studies on this topic mainly use static information such as graph structures but cannot well capture dynamic information such as timestamps of edges. Realistic graphs are often dynamic, which means the interaction between nodes occurs at a specific time. This paper proposes a self-supervised dynamic graph representation learning framework (DySubC), which defines a temporal subgraph contrastive learning task to simultaneously learn the structural and evolutional features of a dynamic graph. Specifically, a novel temporal subgraph sampling strategy is firstly proposed, which takes each node of the dynamic graph as the central node and uses both neighborhood structures and edge timestamps to sample the corresponding temporal subgraph. The subgraph representation function is then designed according to the influence of neighborhood nodes on the central node after encoding the nodes in each subgraph. Finally, the structural and temporal contrastive loss are defined to maximize the mutual information between node representation and temporal subgraph representation. Experiments on five real-world datasets demonstrate that (1) DySubC performs better than the related baselines including two graph contrastive learning models and four dynamic graph representation learning models in the downstream link prediction task, and (2) the use of temporal information can not only sample more effective subgraphs, but also learn better representation by temporal contrastive loss.
GIMIRec: Global Interaction Information Aware Multi-Interest Framework for Sequential Recommendation
Dec 16, 2021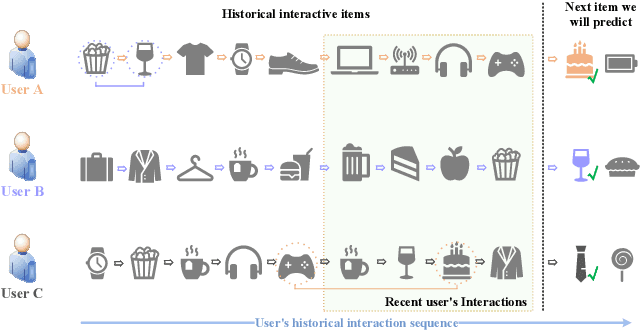
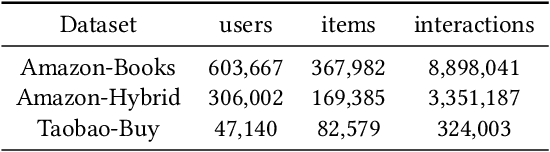

Sequential recommendation based on multi-interest framework models the user's recent interaction sequence into multiple different interest vectors, since a single low-dimensional vector cannot fully represent the diversity of user interests. However, most existing models only intercept users' recent interaction behaviors as training data, discarding a large amount of historical interaction sequences. This may raise two issues. On the one hand, data reflecting multiple interests of users is missing; on the other hand, the co-occurrence between items in historical user-item interactions is not fully explored. To tackle the two issues, this paper proposes a novel sequential recommendation model called "Global Interaction Aware Multi-Interest Framework for Sequential Recommendation (GIMIRec)". Specifically, a global context extraction module is firstly proposed without introducing any external information, which calculates a weighted co-occurrence matrix based on the constrained co-occurrence number of each item pair and their time interval from the historical interaction sequences of all users and then obtains the global context embedding of each item by using a simplified graph convolution. Secondly, the time interval of each item pair in the recent interaction sequence of each user is captured and combined with the global context item embedding to get the personalized item embedding. Finally, a self-attention based multi-interest framework is applied to learn the diverse interests of users for sequential recommendation. Extensive experiments on the three real-world datasets of Amazon-Books, Taobao-Buy and Amazon-Hybrid show that the performance of GIMIRec on the Recall, NDCG and Hit Rate indicators is significantly superior to that of the state-of-the-art methods. Moreover, the proposed global context extraction module can be easily transplanted to most sequential recommendation models.
Sequential online prediction in the presence of outliers and change points: an instant temporal structure learning approach
Jul 15, 2019


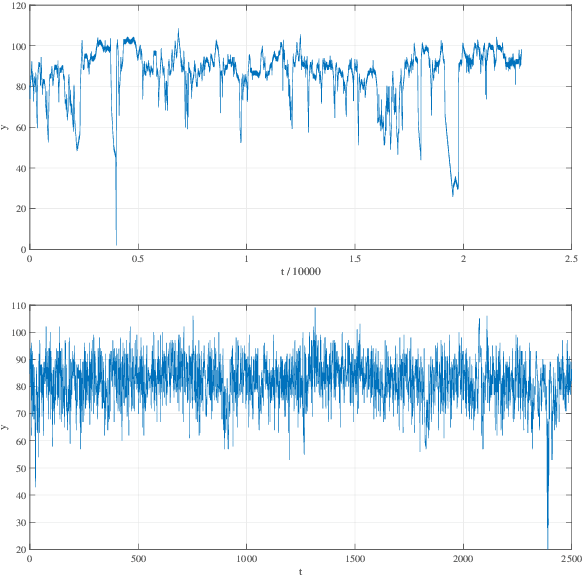
In this paper, we consider sequential online prediction (SOP) for streaming data in the presence of outliers and change points. We propose an INstant TEmporal structure Learning (INTEL) algorithm to address this problem.Our INTEL algorithm is developed based on a full consideration to the duality between online prediction and anomaly detection. We first employ a mixture of weighted GP models (WGPs) to cover the expected possible temporal structures of the data. Then, on the basis of the rich modeling capacity of this WGP mixture, we develop an efficient technique to instantly learn (capture) the temporal structure of the data that follows a regime shift. This instant learning is achieved only by adjusting one hyper-parameter value of the mixture model. A weighted generalization of the product of experts (POE) model is used for fusing predictions yielded from multiple GP models. An outlier is declared once a real observation seriously deviates from the fused prediction. If a certain number of outliers are consecutively declared, then a change point is declared. Extensive experiments are performed using a diverse of real datasets. Results show that the proposed algorithm is significantly better than benchmark methods for SOP in the presence of outliers and change points.
Maximum Likelihood Estimation based on Random Subspace EDA: Application to Extrasolar Planet Detection
Jul 21, 2017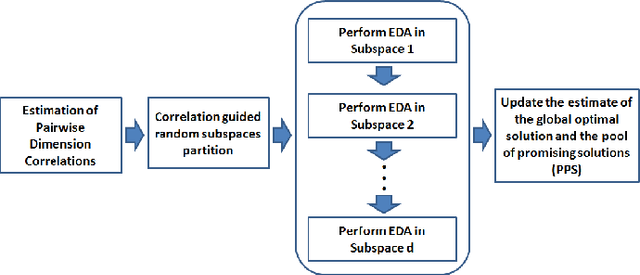



This paper addresses maximum likelihood (ML) estimation based model fitting in the context of extrasolar planet detection. This problem is featured by the following properties: 1) the candidate models under consideration are highly nonlinear; 2) the likelihood surface has a huge number of peaks; 3) the parameter space ranges in size from a few to dozens of dimensions. These properties make the ML search a very challenging problem, as it lacks any analytical or gradient based searching solution to explore the parameter space. A population based searching method, called estimation of distribution algorithm (EDA), is adopted to explore the model parameter space starting from a batch of random locations. EDA is featured by its ability to reveal and utilize problem structures. This property is desirable for characterizing the detections. However, it is well recognized that EDAs can not scale well to large scale problems, as it consists of iterative random sampling and model fitting procedures, which results in the well-known dilemma curse of dimensionality. A novel mechanism to perform EDAs in interactive random subspaces spanned by correlated variables is proposed and the hope is to alleviate the curse of dimensionality for EDAs by performing the operations of sampling and model fitting in lower dimensional subspaces. The effectiveness of the proposed algorithm is verified via both benchmark numerical studies and real data analysis.