 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCIRGC: Multi-Granularity Citation Recommendation and Citation Sentence Preference Alignment
May 26, 2025Citations are crucial in scientific research articles as they highlight the connection between the current study and prior work. However, this process is often time-consuming for researchers. In this study, we propose the SciRGC framework, which aims to automatically recommend citation articles and generate citation sentences for citation locations within articles. The framework addresses two key challenges in academic citation generation: 1) how to accurately identify the author's citation intent and find relevant citation papers, and 2) how to generate high-quality citation sentences that align with human preferences. We enhance citation recommendation accuracy in the citation article recommendation module by incorporating citation networks and sentiment intent, and generate reasoning-based citation sentences in the citation sentence generation module by using the original article abstract, local context, citation intent, and recommended articles as inputs. Additionally, we propose a new evaluation metric to fairly assess the quality of generated citation sentences. Through comparisons with baseline models and ablation experiments, the SciRGC framework not only improves the accuracy and relevance of citation recommendations but also ensures the appropriateness of the generated citation sentences in context, providing a valuable tool for interdisciplinary researchers.
An entity-guided text summarization framework with relational heterogeneous graph neural network
Feb 07, 2023Two crucial issues for text summarization to generate faithful summaries are to make use of knowledge beyond text and to make use of cross-sentence relations in text. Intuitive ways for the two issues are Knowledge Graph (KG) and Graph Neural Network (GNN) respectively. Entities are semantic units in text and in KG. This paper focuses on both issues by leveraging entities mentioned in text to connect GNN and KG for summarization. Firstly, entities are leveraged to construct a sentence-entity graph with weighted multi-type edges to model sentence relations, and a relational heterogeneous GNN for summarization is proposed to calculate node encodings. Secondly, entities are leveraged to link the graph to KG to collect knowledge. Thirdly, entities guide a two-step summarization framework defining a multi-task selector to select salient sentences and entities, and using an entity-focused abstractor to compress the sentences. GNN is connected with KG by constructing sentence-entity graphs where entity-entity edges are built based on KG, initializing entity embeddings on KG, and training entity embeddings using entity-entity edges. The relational heterogeneous GNN utilizes both edge weights and edge types in GNN to calculate graphs with weighted multi-type edges. Experiments show the proposed method outperforms extractive baselines including the HGNN-based HGNNSum and abstractive baselines including the entity-driven SENECA on CNN/DM, and outperforms most baselines on NYT50. Experiments on sub-datasets show the density of sentence-entity edges greatly influences the performance of the proposed method. The greater the density, the better the performance. Ablations show effectiveness of the method.
Transform, Contrast and Tell: Coherent Entity-Aware Multi-Image Captioning
Feb 04, 2023Coherent entity-aware multi-image captioning aims to generate coherent captions for multiple adjacent images in a news document. There are coherence relationships among adjacent images because they often describe same entities or events. These relationships are important for entity-aware multi-image captioning, but are neglected in entity-aware single-image captioning. Most existing work focuses on single-image captioning, while multi-image captioning has not been explored before. Hence, this paper proposes a coherent entity-aware multi-image captioning model by making use of coherence relationships. The model consists of a Transformer-based caption generation model and two types of contrastive learning-based coherence mechanisms. The generation model generates the caption by paying attention to the image and the accompanying text. The horizontal coherence mechanism aims to the make the caption coherent with captions of adjacent images. The vertical coherence mechanism aims to make the caption coherent with the image and the accompanying text. To evaluate coherence between captions, two coherence evaluation metrics are proposed. The new dataset DM800K is constructed that has more images per document than two existing datasets GoodNews and NYT800K, and are more suitable for multi-image captioning. Experiments on three datasets show the proposed captioning model outperforms 6 baselines according to single-image captioning evaluations, and the generated captions are more coherent than that of baselines according to coherence evaluations and human evaluations.
Self-Supervised Dynamic Graph Representation Learning via Temporal Subgraph Contrast
Dec 16, 2021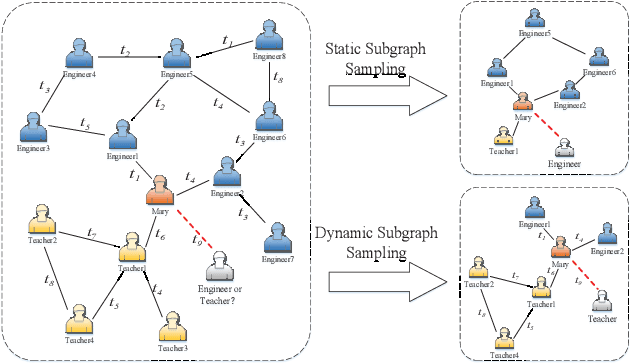

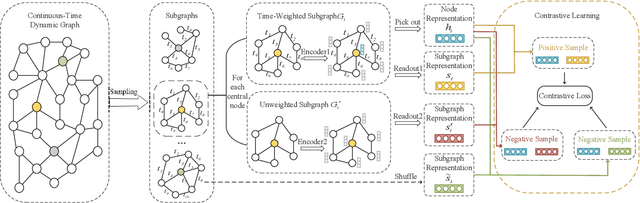
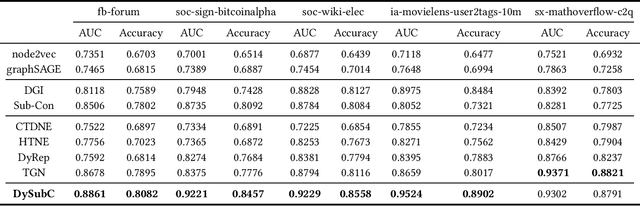
Self-supervised learning on graphs has recently drawn a lot of attention due to its independence from labels and its robustness in representation. Current studies on this topic mainly use static information such as graph structures but cannot well capture dynamic information such as timestamps of edges. Realistic graphs are often dynamic, which means the interaction between nodes occurs at a specific time. This paper proposes a self-supervised dynamic graph representation learning framework (DySubC), which defines a temporal subgraph contrastive learning task to simultaneously learn the structural and evolutional features of a dynamic graph. Specifically, a novel temporal subgraph sampling strategy is firstly proposed, which takes each node of the dynamic graph as the central node and uses both neighborhood structures and edge timestamps to sample the corresponding temporal subgraph. The subgraph representation function is then designed according to the influence of neighborhood nodes on the central node after encoding the nodes in each subgraph. Finally, the structural and temporal contrastive loss are defined to maximize the mutual information between node representation and temporal subgraph representation. Experiments on five real-world datasets demonstrate that (1) DySubC performs better than the related baselines including two graph contrastive learning models and four dynamic graph representation learning models in the downstream link prediction task, and (2) the use of temporal information can not only sample more effective subgraphs, but also learn better representation by temporal contrastive loss.
GIMIRec: Global Interaction Information Aware Multi-Interest Framework for Sequential Recommendation
Dec 16, 2021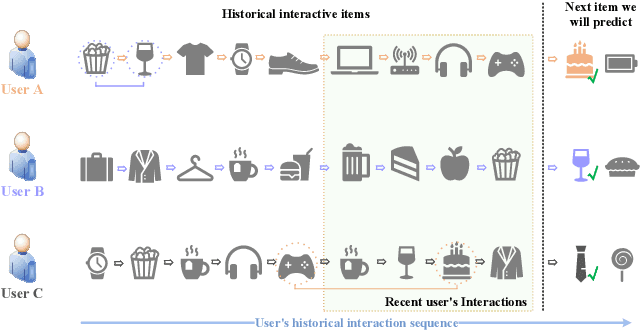
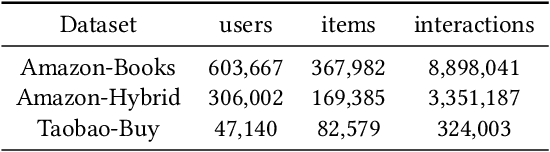

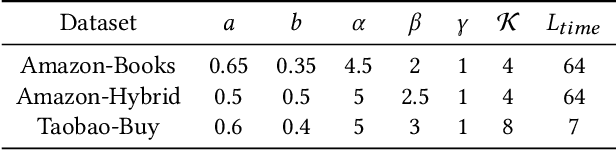
Sequential recommendation based on multi-interest framework models the user's recent interaction sequence into multiple different interest vectors, since a single low-dimensional vector cannot fully represent the diversity of user interests. However, most existing models only intercept users' recent interaction behaviors as training data, discarding a large amount of historical interaction sequences. This may raise two issues. On the one hand, data reflecting multiple interests of users is missing; on the other hand, the co-occurrence between items in historical user-item interactions is not fully explored. To tackle the two issues, this paper proposes a novel sequential recommendation model called "Global Interaction Aware Multi-Interest Framework for Sequential Recommendation (GIMIRec)". Specifically, a global context extraction module is firstly proposed without introducing any external information, which calculates a weighted co-occurrence matrix based on the constrained co-occurrence number of each item pair and their time interval from the historical interaction sequences of all users and then obtains the global context embedding of each item by using a simplified graph convolution. Secondly, the time interval of each item pair in the recent interaction sequence of each user is captured and combined with the global context item embedding to get the personalized item embedding. Finally, a self-attention based multi-interest framework is applied to learn the diverse interests of users for sequential recommendation. Extensive experiments on the three real-world datasets of Amazon-Books, Taobao-Buy and Amazon-Hybrid show that the performance of GIMIRec on the Recall, NDCG and Hit Rate indicators is significantly superior to that of the state-of-the-art methods. Moreover, the proposed global context extraction module can be easily transplanted to most sequential recommendation models.