 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization of Information-Seeking Dialogue Strategy for Argumentation-Based Dialogue System
Nov 26, 2018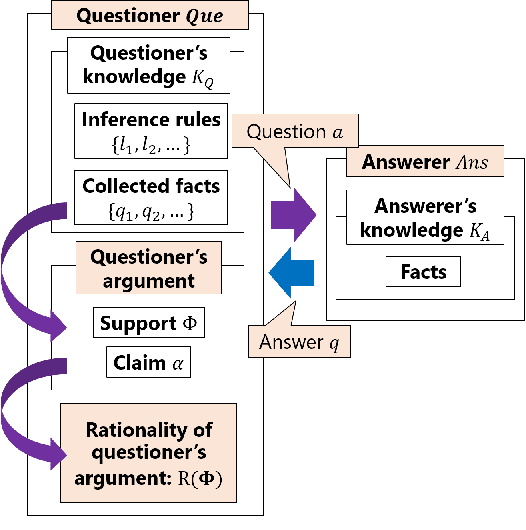
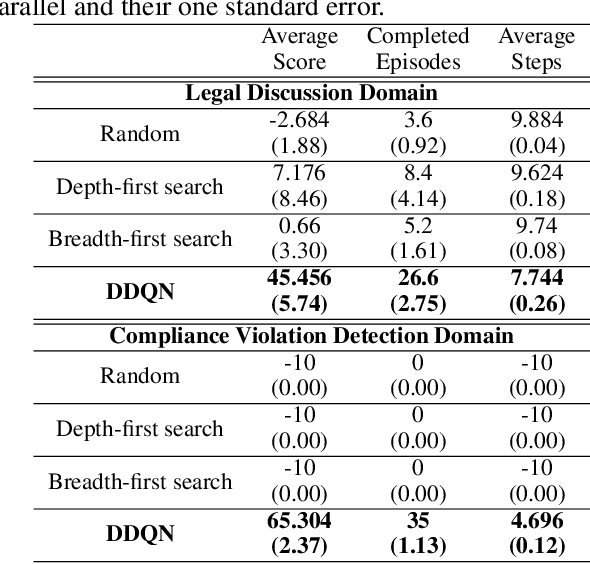
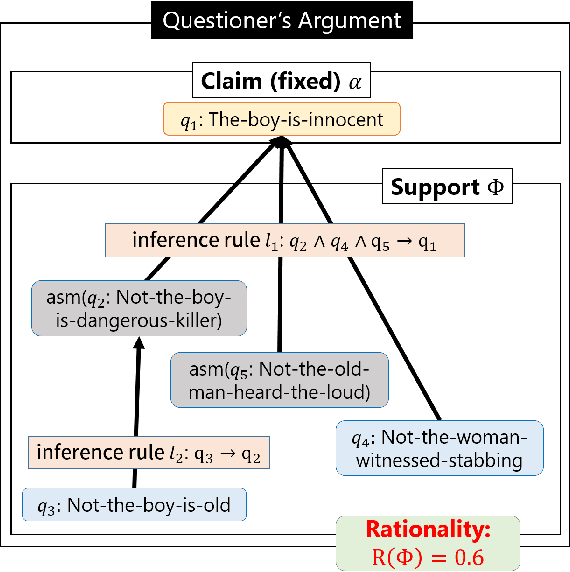

Argumentation-based dialogue systems, which can handle and exchange arguments through dialogue, have been widely researched. It is required that these systems have sufficient supporting information to argue their claims rationally; however, the systems often do not have enough of such information in realistic situations. One way to fill in the gap is acquiring such missing information from dialogue partners (information-seeking dialogue). Existing information-seeking dialogue systems are based on handcrafted dialogue strategies that exhaustively examine missing information. However, the proposed strategies are not specialized in collecting information for constructing rational arguments. Moreover, the number of system's inquiry candidates grows in accordance with the size of the argument set that the system deal with. In this paper, we formalize the process of information-seeking dialogue as Markov decision processes (MDPs) and apply deep reinforcement learning (DRL) for automatically optimizing a dialogue strategy. By utilizing DRL, our dialogue strategy can successfully minimize objective functions, the number of turns it takes for our system to collect necessary information in a dialogue. We conducted dialogue experiments using two datasets from different domains of argumentative dialogue. Experimental results show that the proposed formalization based on MDP works well, and the policy optimized by DRL outperformed existing heuristic dialogue strategies.
Hierarchical Reinforcement Learning with Abductive Planning
Jun 28, 2018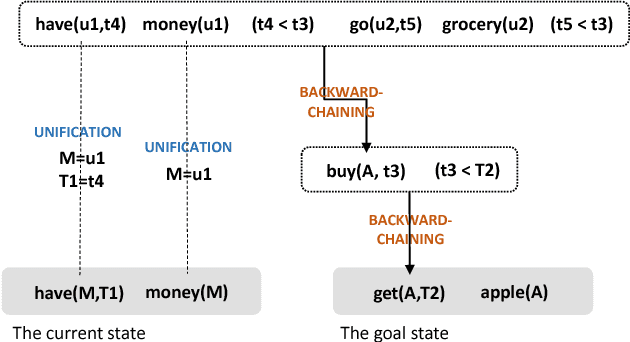
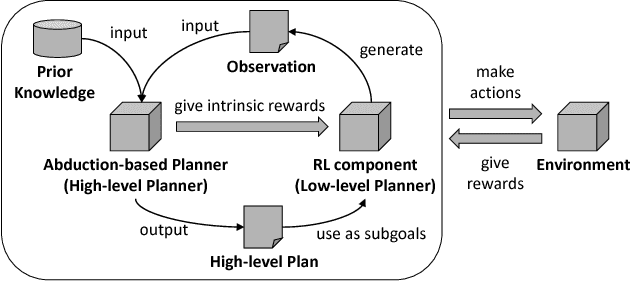


One of the key challenges in applying reinforcement learning to real-life problems is that the amount of train-and-error required to learn a good policy increases drastically as the task becomes complex. One potential solution to this problem is to combine reinforcement learning with automated symbol planning and utilize prior knowledge on the domain. However, existing methods have limitations in their applicability and expressiveness. In this paper we propose a hierarchical reinforcement learning method based on abductive symbolic planning. The planner can deal with user-defined evaluation functions and is not based on the Herbrand theorem. Therefore it can utilize prior knowledge of the rewards and can work in a domain where the state space is unknown. We demonstrate empirically that our architecture significantly improves learning efficiency with respect to the amount of training examples on the evaluation domain, in which the state space is unknown and there exist multiple goals.
Translating MFM into FOL: towards plant operation planning
Jun 19, 2018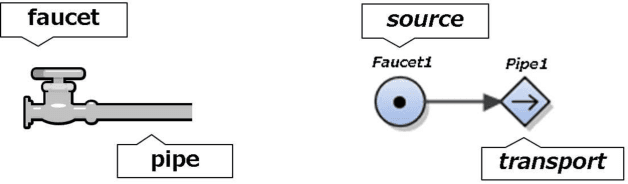
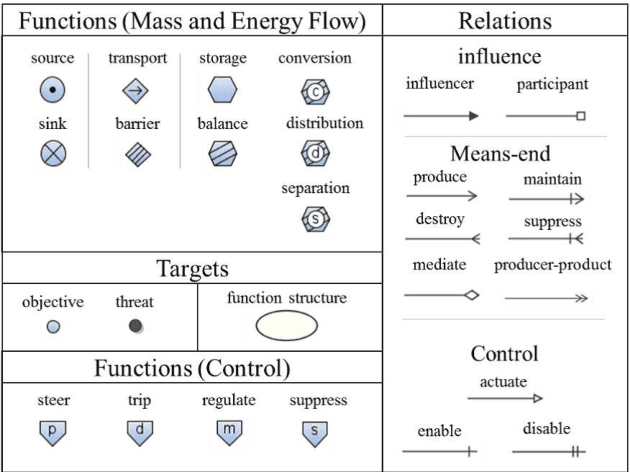
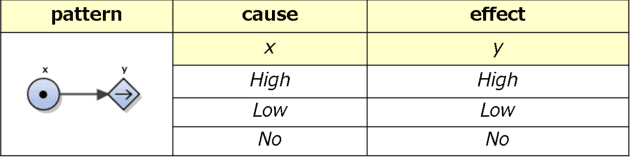
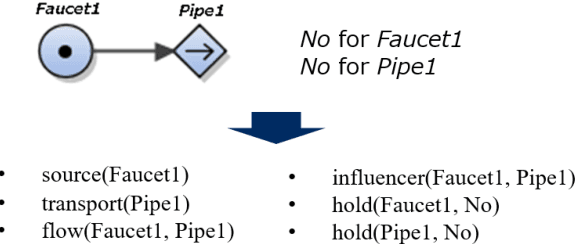
This paper proposes a method to translate multilevel flow modeling (MFM) into a first-order language (FOL), which enables the utilisation of logical techniques, such as inference engines and abductive reasoners. An example of this is a planning task for a toy plant that can be solved in FOL using abduction. In addition, owing to the expressivity of FOL, the language is capable of describing actions and their preconditions. This allows the derivation of procedures consisting of multiple actions.