 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Reinforcement Learning with Abductive Planning
Paper and Code
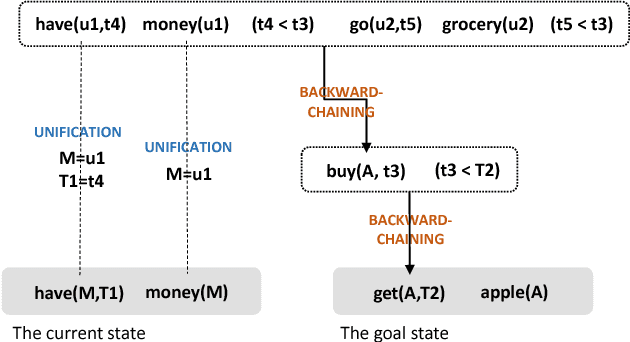
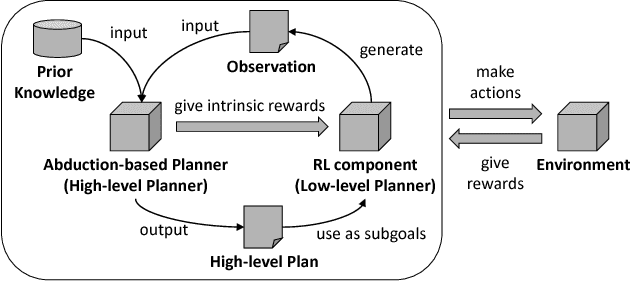


One of the key challenges in applying reinforcement learning to real-life problems is that the amount of train-and-error required to learn a good policy increases drastically as the task becomes complex. One potential solution to this problem is to combine reinforcement learning with automated symbol planning and utilize prior knowledge on the domain. However, existing methods have limitations in their applicability and expressiveness. In this paper we propose a hierarchical reinforcement learning method based on abductive symbolic planning. The planner can deal with user-defined evaluation functions and is not based on the Herbrand theorem. Therefore it can utilize prior knowledge of the rewards and can work in a domain where the state space is unknown. We demonstrate empirically that our architecture significantly improves learning efficiency with respect to the amount of training examples on the evaluation domain, in which the state space is unknown and there exist multiple goals.