 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSNA Large Language Model Benchmark Dataset for Chest Radiographs of Cardiothoracic Disease: Radiologist Evaluation and Validation Enhanced by AI Labels (REVEAL-CXR)
Jan 21, 2026Multimodal large language models have demonstrated comparable performance to that of radiology trainees on multiple-choice board-style exams. However, to develop clinically useful multimodal LLM tools, high-quality benchmarks curated by domain experts are essential. To curate released and holdout datasets of 100 chest radiographic studies each and propose an artificial intelligence (AI)-assisted expert labeling procedure to allow radiologists to label studies more efficiently. A total of 13,735 deidentified chest radiographs and their corresponding reports from the MIDRC were used. GPT-4o extracted abnormal findings from the reports, which were then mapped to 12 benchmark labels with a locally hosted LLM (Phi-4-Reasoning). From these studies, 1,000 were sampled on the basis of the AI-suggested benchmark labels for expert review; the sampling algorithm ensured that the selected studies were clinically relevant and captured a range of difficulty levels. Seventeen chest radiologists participated, and they marked "Agree all", "Agree mostly" or "Disagree" to indicate their assessment of the correctness of the LLM suggested labels. Each chest radiograph was evaluated by three experts. Of these, at least two radiologists selected "Agree All" for 381 radiographs. From this set, 200 were selected, prioritizing those with less common or multiple finding labels, and divided into 100 released radiographs and 100 reserved as the holdout dataset. The holdout dataset is used exclusively by RSNA to independently evaluate different models. A benchmark of 200 chest radiographic studies with 12 benchmark labels was created and made publicly available https://imaging.rsna.org, with each chest radiograph verified by three radiologists. In addition, an AI-assisted labeling procedure was developed to help radiologists label at scale, minimize unnecessary omissions, and support a semicollaborative environment.
Report of the Medical Image De-Identification Task Group -- Best Practices and Recommendations
Apr 01, 2023This report addresses the technical aspects of de-identification of medical images of human subjects and biospecimens, such that re-identification risk of ethical, moral, and legal concern is sufficiently reduced to allow unrestricted public sharing for any purpose, regardless of the jurisdiction of the source and distribution sites. All medical images, regardless of the mode of acquisition, are considered, though the primary emphasis is on those with accompanying data elements, especially those encoded in formats in which the data elements are embedded, particularly Digital Imaging and Communications in Medicine (DICOM). These images include image-like objects such as Segmentations, Parametric Maps, and Radiotherapy (RT) Dose objects. The scope also includes related non-image objects, such as RT Structure Sets, Plans and Dose Volume Histograms, Structured Reports, and Presentation States. Only de-identification of publicly released data is considered, and alternative approaches to privacy preservation, such as federated learning for artificial intelligence (AI) model development, are out of scope, as are issues of privacy leakage from AI model sharing. Only technical issues of public sharing are addressed.
An Overview and Case Study of the Clinical AI Model Development Life Cycle for Healthcare Systems
Mar 26, 2020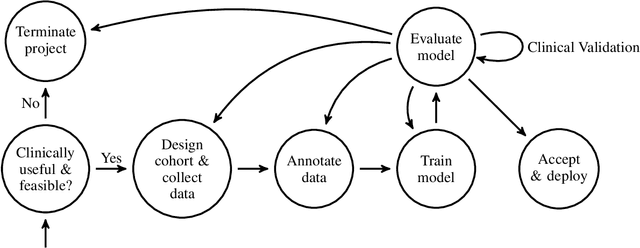
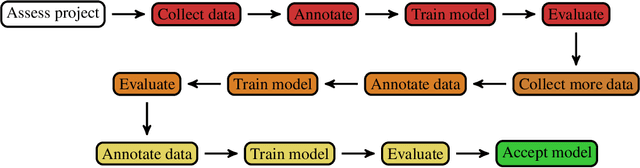
Healthcare is one of the most promising areas for machine learning models to make a positive impact. However, successful adoption of AI-based systems in healthcare depends on engaging and educating stakeholders from diverse backgrounds about the development process of AI models. We present a broadly accessible overview of the development life cycle of clinical AI models that is general enough to be adapted to most machine learning projects, and then give an in-depth case study of the development process of a deep learning based system to detect aortic aneurysms in Computed Tomography (CT) exams. We hope other healthcare institutions and clinical practitioners find the insights we share about the development process useful in informing their own model development efforts and to increase the likelihood of successful deployment and integration of AI in healthcare.
Semi-Supervised Natural Language Approach for Fine-Grained Classification of Medical Reports
Nov 14, 2019
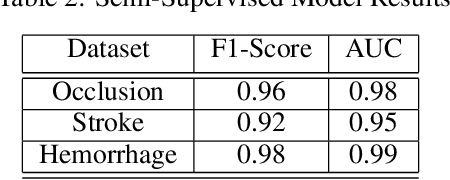
Although machine learning has become a powerful tool to augment doctors in clinical analysis, the immense amount of labeled data that is necessary to train supervised learning approaches burdens each development task as time and resource intensive. The vast majority of dense clinical information is stored in written reports, detailing pertinent patient information. The challenge with utilizing natural language data for standard model development is due to the complex nature of the modality. In this research, a model pipeline was developed to utilize an unsupervised approach to train an encoder-language model, a recurrent network, to generate document encodings; which then can be used as features passed into a decoder-classifier model that requires magnitudes less labeled data than previous approaches to differentiate between fine-grained disease classes accurately. The language model was trained on unlabeled radiology reports from the Massachusetts General Hospital Radiology Department (n=218,159) and terminated with a loss of 1.62. The classification models were trained on three labeled datasets of head CT studies of reported patients, presenting large vessel occlusion (n=1403), acute ischemic strokes (n=331), and intracranial hemorrhage (n=4350), to identify a variety of different findings directly from the radiology report data; resulting in AUCs of 0.98, 0.95, and 0.99, respectively, for the large vessel occlusion, acute ischemic stroke, and intracranial hemorrhage datasets. The output encodings are able to be used in conjunction with imaging data, to create models that can process a multitude of different modalities. The ability to automatically extract relevant features from textual data allows for faster model development and integration of textual modality, overall, allowing clinical reports to become a more viable input for more encompassing and accurate deep learning models.
Medical Image Synthesis for Data Augmentation and Anonymization using Generative Adversarial Networks
Sep 13, 2018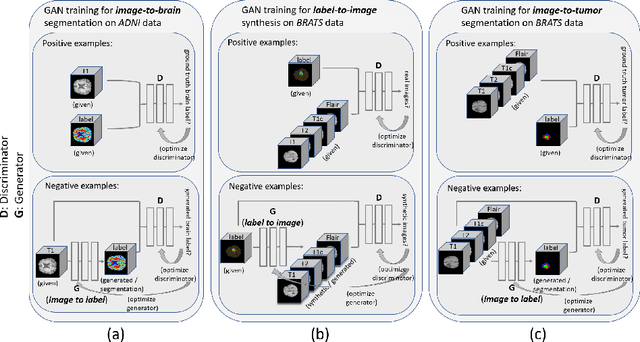
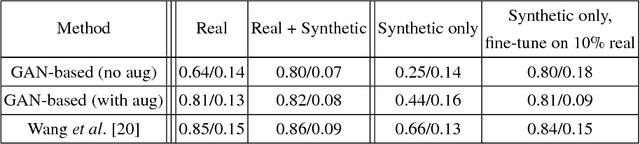
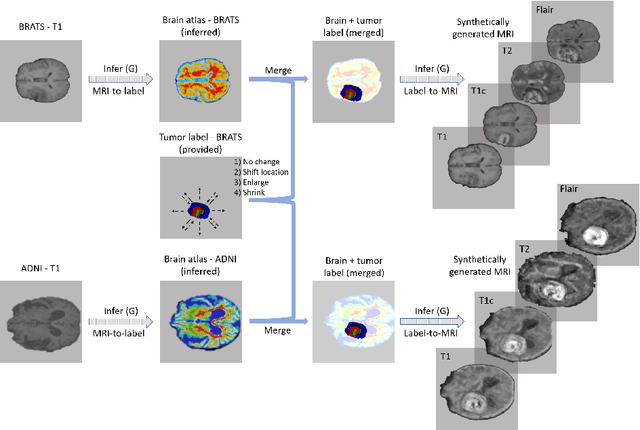
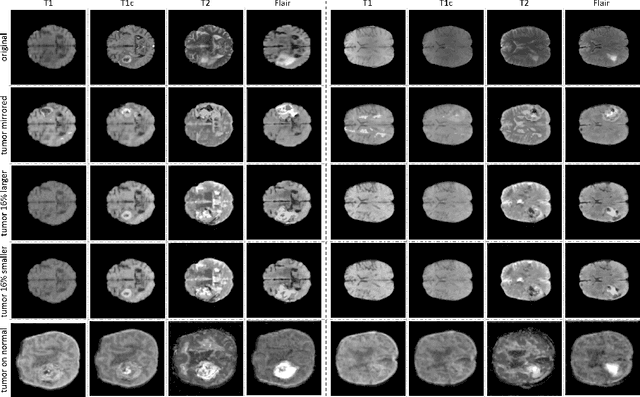
Data diversity is critical to success when training deep learning models. Medical imaging data sets are often imbalanced as pathologic findings are generally rare, which introduces significant challenges when training deep learning models. In this work, we propose a method to generate synthetic abnormal MRI images with brain tumors by training a generative adversarial network using two publicly available data sets of brain MRI. We demonstrate two unique benefits that the synthetic images provide. First, we illustrate improved performance on tumor segmentation by leveraging the synthetic images as a form of data augmentation. Second, we demonstrate the value of generative models as an anonymization tool, achieving comparable tumor segmentation results when trained on the synthetic data versus when trained on real subject data. Together, these results offer a potential solution to two of the largest challenges facing machine learning in medical imaging, namely the small incidence of pathological findings, and the restrictions around sharing of patient data.
Fully-Automated Analysis of Body Composition from CT in Cancer Patients Using Convolutional Neural Networks
Aug 11, 2018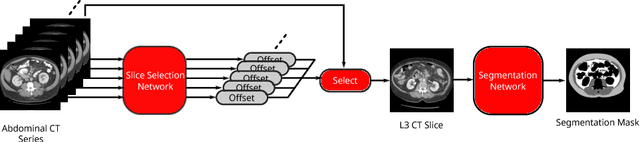
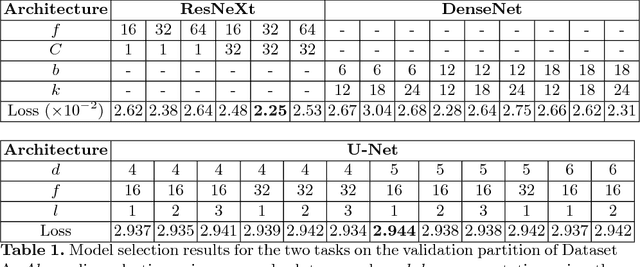
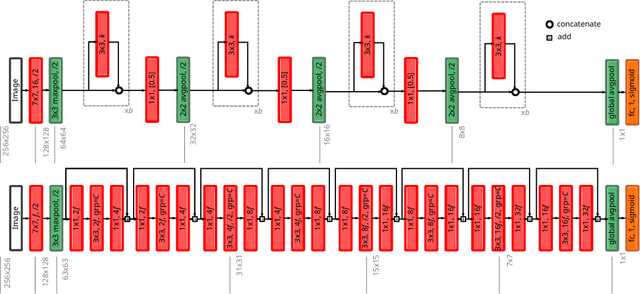
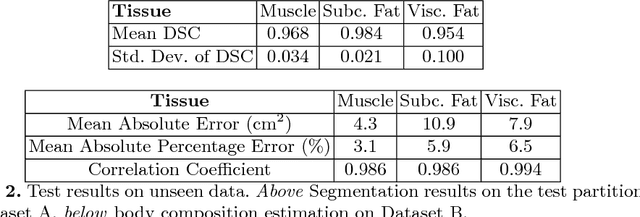
The amounts of muscle and fat in a person's body, known as body composition, are correlated with cancer risks, cancer survival, and cardiovascular risk. The current gold standard for measuring body composition requires time-consuming manual segmentation of CT images by an expert reader. In this work, we describe a two-step process to fully automate the analysis of CT body composition using a DenseNet to select the CT slice and U-Net to perform segmentation. We train and test our methods on independent cohorts. Our results show Dice scores (0.95-0.98) and correlation coefficients (R=0.99) that are favorable compared to human readers. These results suggest that fully automated body composition analysis is feasible, which could enable both clinical use and large-scale population studies.