 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying clinical machine learning? Consider the following...
Sep 14, 2021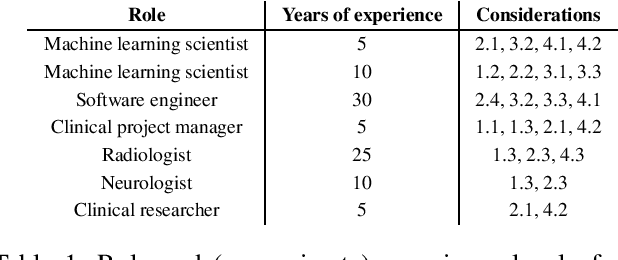
Despite the intense attention and investment into clinical machine learning (CML) research, relatively few applications convert to clinical practice. While research is important in advancing the state-of-the-art, translation is equally important in bringing these technologies into a position to ultimately impact patient care and live up to extensive expectations surrounding AI in healthcare. To better characterize a holistic perspective among researchers and practitioners, we survey several participants with experience in developing CML for clinical deployment about their learned experiences. We collate these insights and identify several main categories of barriers and pitfalls in order to better design and develop clinical machine learning applications.
Semi-Supervised Natural Language Approach for Fine-Grained Classification of Medical Reports
Nov 14, 2019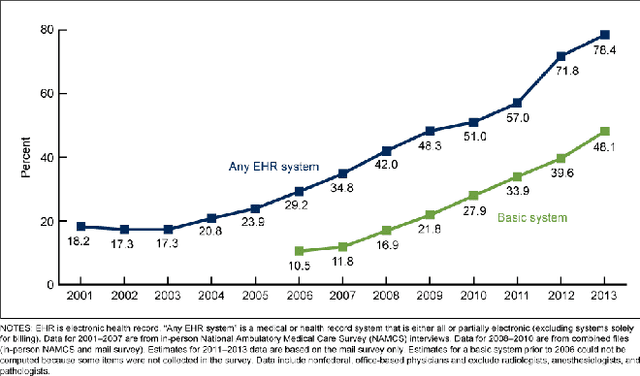
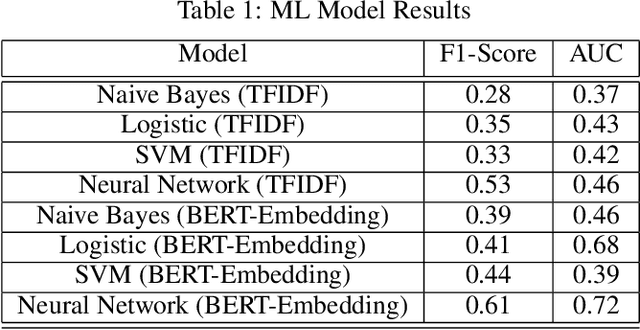
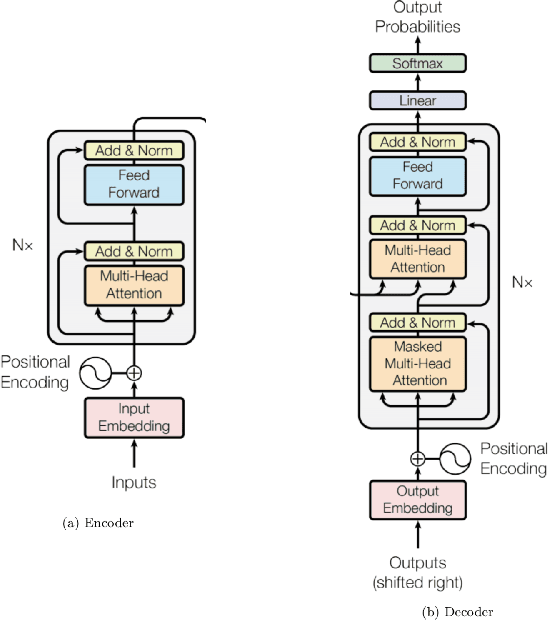
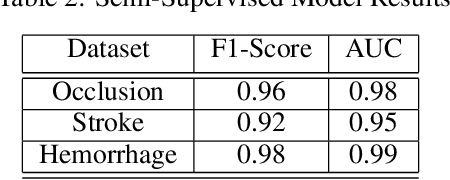
Although machine learning has become a powerful tool to augment doctors in clinical analysis, the immense amount of labeled data that is necessary to train supervised learning approaches burdens each development task as time and resource intensive. The vast majority of dense clinical information is stored in written reports, detailing pertinent patient information. The challenge with utilizing natural language data for standard model development is due to the complex nature of the modality. In this research, a model pipeline was developed to utilize an unsupervised approach to train an encoder-language model, a recurrent network, to generate document encodings; which then can be used as features passed into a decoder-classifier model that requires magnitudes less labeled data than previous approaches to differentiate between fine-grained disease classes accurately. The language model was trained on unlabeled radiology reports from the Massachusetts General Hospital Radiology Department (n=218,159) and terminated with a loss of 1.62. The classification models were trained on three labeled datasets of head CT studies of reported patients, presenting large vessel occlusion (n=1403), acute ischemic strokes (n=331), and intracranial hemorrhage (n=4350), to identify a variety of different findings directly from the radiology report data; resulting in AUCs of 0.98, 0.95, and 0.99, respectively, for the large vessel occlusion, acute ischemic stroke, and intracranial hemorrhage datasets. The output encodings are able to be used in conjunction with imaging data, to create models that can process a multitude of different modalities. The ability to automatically extract relevant features from textual data allows for faster model development and integration of textual modality, overall, allowing clinical reports to become a more viable input for more encompassing and accurate deep learning models.