 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Defect Inspection with Visual and Tactile Perception for Large-scale Components
Sep 08, 2023



In manufacturing processes, surface inspection is a key requirement for quality assessment and damage localization. Due to this, automated surface anomaly detection has become a promising area of research in various industrial inspection systems. A particular challenge in industries with large-scale components, like aircraft and heavy machinery, is inspecting large parts with very small defect dimensions. Moreover, these parts can be of curved shapes. To address this challenge, we present a 2-stage multi-modal inspection pipeline with visual and tactile sensing. Our approach combines the best of both visual and tactile sensing by identifying and localizing defects using a global view (vision) and using the localized area for tactile scanning for identifying remaining defects. To benchmark our approach, we propose a novel real-world dataset with multiple metallic defect types per image, collected in the production environments on real aerospace manufacturing parts, as well as online robot experiments in two environments. Our approach is able to identify 85% defects using Stage I and identify 100% defects after Stage II. The dataset is publicly available at https://zenodo.org/record/8327713
Projection-Based Constrained Policy Optimization
Oct 07, 2020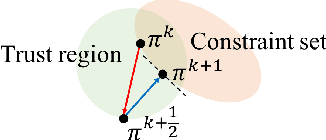
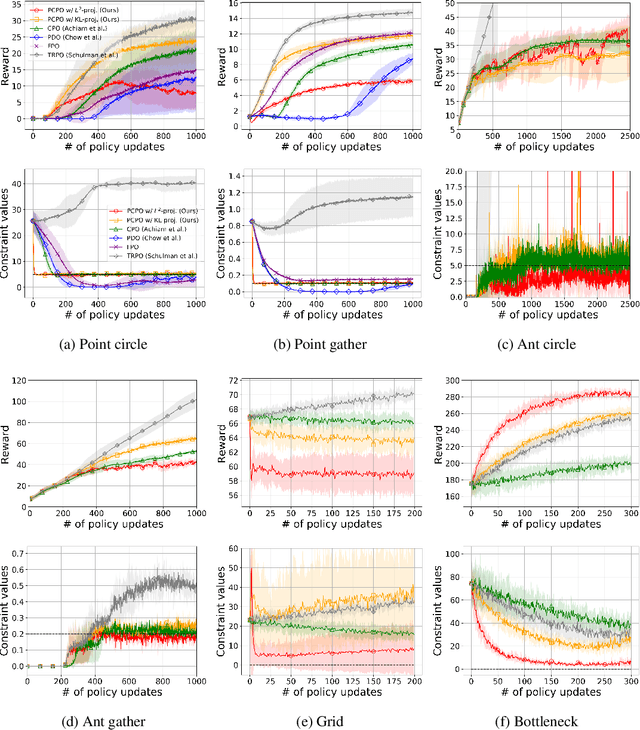
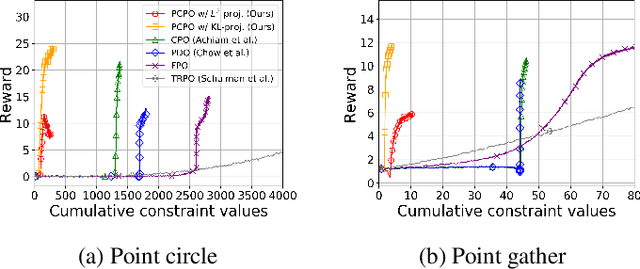
We consider the problem of learning control policies that optimize a reward function while satisfying constraints due to considerations of safety, fairness, or other costs. We propose a new algorithm, Projection-Based Constrained Policy Optimization (PCPO). This is an iterative method for optimizing policies in a two-step process: the first step performs a local reward improvement update, while the second step reconciles any constraint violation by projecting the policy back onto the constraint set. We theoretically analyze PCPO and provide a lower bound on reward improvement, and an upper bound on constraint violation, for each policy update. We further characterize the convergence of PCPO based on two different metrics: $\normltwo$ norm and Kullback-Leibler divergence. Our empirical results over several control tasks demonstrate that PCPO achieves superior performance, averaging more than 3.5 times less constraint violation and around 15\% higher reward compared to state-of-the-art methods.
Accelerating Safe Reinforcement Learning with Constraint-mismatched Policies
Jun 20, 2020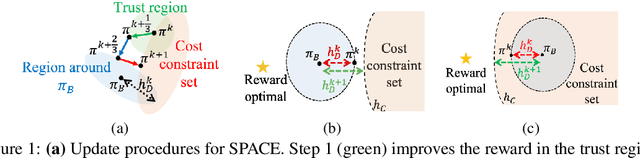
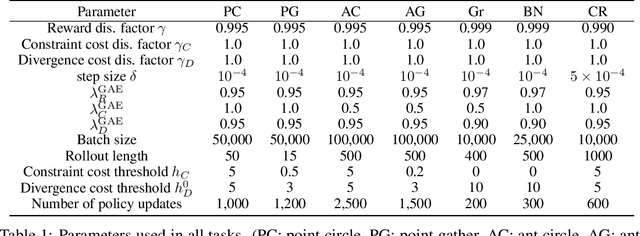
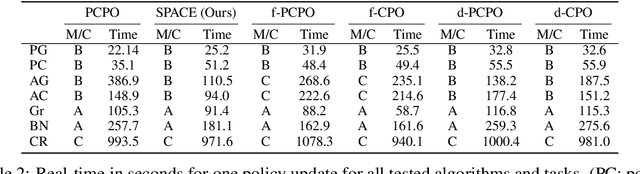
We consider the problem of reinforcement learning when provided with a baseline control policy and a set of constraints that the controlled system must satisfy. The baseline policy might arise from a heuristic, a prior application, a teacher or demonstrator data. The constraints might encode safety, fairness or some application-specific requirements. We want to efficiently use reinforcement learning to adapt the baseline policy to improve performance and satisfy the given constraints when it is applied to the new system. The key challenge is to effectively use the baseline policy (which need not satisfy the current constraints) to aid the learning of a constraint-satisfying policy in the new application. We propose an iterative algorithm for solving this problem. Each iteration is composed of three-steps. The first step performs a policy update to increase the expected reward, the second step performs a projection to minimize the distance between the current policy and the baseline policy, and the last step performs a projection onto the set of policies that satisfy the constraints. This procedure allows the learning process to leverage the baseline policy to achieve faster learning while improving reward performance and satisfying the constraints imposed on the current problem. We analyze the convergence of the proposed algorithm and provide a finite-sample guarantee. Empirical results demonstrate that the algorithm can achieve superior performance, with 10 times fewer constraint violations and around 40% higher reward compared to state-of-the-art methods.