 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Safe Reinforcement Learning with Constraint-mismatched Policies
Paper and Code
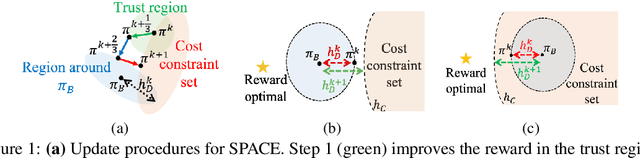
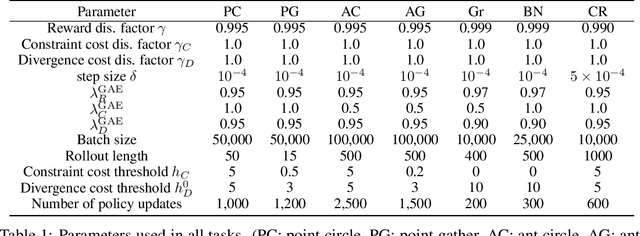
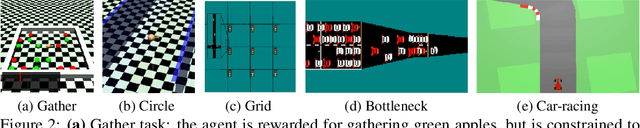
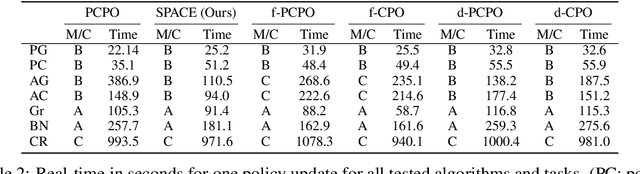
We consider the problem of reinforcement learning when provided with a baseline control policy and a set of constraints that the controlled system must satisfy. The baseline policy might arise from a heuristic, a prior application, a teacher or demonstrator data. The constraints might encode safety, fairness or some application-specific requirements. We want to efficiently use reinforcement learning to adapt the baseline policy to improve performance and satisfy the given constraints when it is applied to the new system. The key challenge is to effectively use the baseline policy (which need not satisfy the current constraints) to aid the learning of a constraint-satisfying policy in the new application. We propose an iterative algorithm for solving this problem. Each iteration is composed of three-steps. The first step performs a policy update to increase the expected reward, the second step performs a projection to minimize the distance between the current policy and the baseline policy, and the last step performs a projection onto the set of policies that satisfy the constraints. This procedure allows the learning process to leverage the baseline policy to achieve faster learning while improving reward performance and satisfying the constraints imposed on the current problem. We analyze the convergence of the proposed algorithm and provide a finite-sample guarantee. Empirical results demonstrate that the algorithm can achieve superior performance, with 10 times fewer constraint violations and around 40% higher reward compared to state-of-the-art methods.