 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDBench: A Synthetic Multi-Document Reasoning Benchmark Generated with Knowledge Guidance
Jun 17, 2025

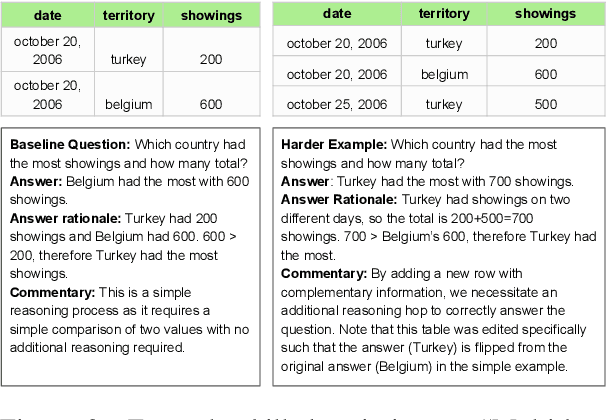

Natural language processing evaluation has made significant progress, largely driven by the proliferation of powerful large language mod-els (LLMs). New evaluation benchmarks are of increasing priority as the reasoning capabilities of LLMs are expanding at a rapid pace. In particular, while multi-document (MD) reasoning is an area of extreme relevance given LLM capabilities in handling longer-context inputs, few benchmarks exist to rigorously examine model behavior in this setting. Moreover, the multi-document setting is historically challenging for benchmark creation due to the expensive cost of annotating long inputs. In this work, we introduce MDBench, a new dataset for evaluating LLMs on the task of multi-document reasoning. Notably, MDBench is created through a novel synthetic generation process, allowing us to controllably and efficiently generate challenging document sets and the corresponding question-answer (QA) examples. Our novel technique operates on condensed structured seed knowledge, modifying it through LLM-assisted edits to induce MD-specific reasoning challenges. We then convert this structured knowledge into a natural text surface form, generating a document set and corresponding QA example. We analyze the behavior of popular LLMs and prompting techniques, finding that MDBENCH poses significant challenges for all methods, even with relatively short document sets. We also see our knowledge-guided generation technique (1) allows us to readily perform targeted analysis of MD-specific reasoning capabilities and (2) can be adapted quickly to account for new challenges and future modeling improvements.
PELMS: Pre-training for Effective Low-Shot Multi-Document Summarization
Nov 16, 2023



We investigate pre-training techniques for abstractive multi-document summarization (MDS), which is much less studied than summarizing single documents. Though recent work has demonstrated the effectiveness of highlighting information salience for pre-training strategy design, it struggles to generate abstractive and reflective summaries, which are critical properties for MDS. To this end, we present PELMS, a pre-trained model that uses objectives based on semantic coherence heuristics and faithfulness constraints with un-labeled multi-document inputs, to promote the generation of concise, fluent, and faithful summaries. To support the training of PELMS, we compile MultiPT, a multi-document pre-training corpus containing over 93 million documents to form more than 3 million unlabeled topic-centric document clusters, covering diverse genres such as product reviews, news, and general knowledge. We perform extensive evaluation of PELMS in low-shot settings on a wide range of MDS datasets. Our approach consistently outperforms competitive comparisons with respect to overall informativeness, abstractiveness, coherence, and faithfulness.
Generative Aspect-Based Sentiment Analysis with Contrastive Learning and Expressive Structure
Nov 14, 2022



Generative models have demonstrated impressive results on Aspect-based Sentiment Analysis (ABSA) tasks, particularly for the emerging task of extracting Aspect-Category-Opinion-Sentiment (ACOS) quadruples. However, these models struggle with implicit sentiment expressions, which are commonly observed in opinionated content such as online reviews. In this work, we introduce GEN-SCL-NAT, which consists of two techniques for improved structured generation for ACOS quadruple extraction. First, we propose GEN-SCL, a supervised contrastive learning objective that aids quadruple prediction by encouraging the model to produce input representations that are discriminable across key input attributes, such as sentiment polarity and the existence of implicit opinions and aspects. Second, we introduce GEN-NAT, a new structured generation format that better adapts autoregressive encoder-decoder models to extract quadruples in a generative fashion. Experimental results show that GEN-SCL-NAT achieves top performance across three ACOS datasets, averaging 1.48% F1 improvement, with a maximum 1.73% increase on the LAPTOP-L1 dataset. Additionally, we see significant gains on implicit aspect and opinion splits that have been shown as challenging for existing ACOS approaches.
An Evaluation Dataset for Intent Classification and Out-of-Scope Prediction
Sep 04, 2019
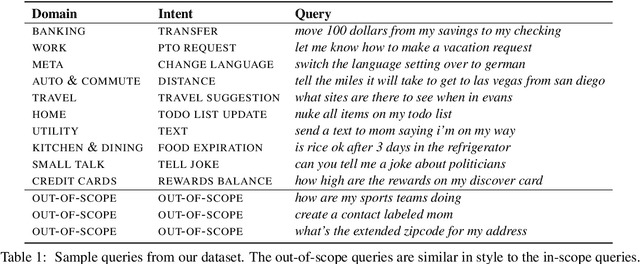
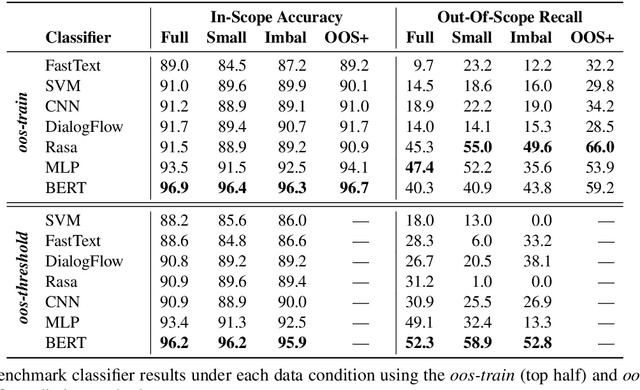
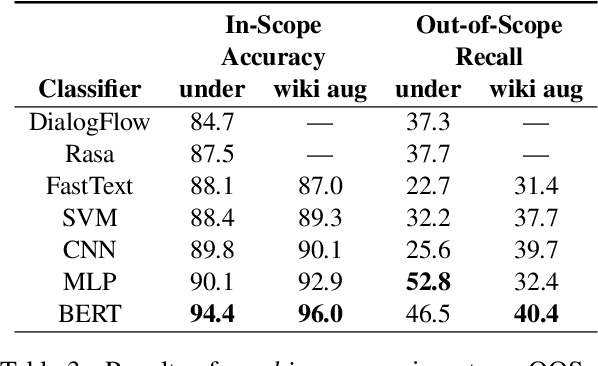
Task-oriented dialog systems need to know when a query falls outside their range of supported intents, but current text classification corpora only define label sets that cover every example. We introduce a new dataset that includes queries that are out-of-scope---i.e., queries that do not fall into any of the system's supported intents. This poses a new challenge because models cannot assume that every query at inference time belongs to a system-supported intent class. Our dataset also covers 150 intent classes over 10 domains, capturing the breadth that a production task-oriented agent must handle. We evaluate a range of benchmark classifiers on our dataset along with several different out-of-scope identification schemes. We find that while the classifiers perform well on in-scope intent classification, they struggle to identify out-of-scope queries. Our dataset and evaluation fill an important gap in the field, offering a way of more rigorously and realistically benchmarking text classification in task-driven dialog systems.