 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpty Cities: a Dynamic-Object-Invariant Space for Visual SLAM
Oct 15, 2020

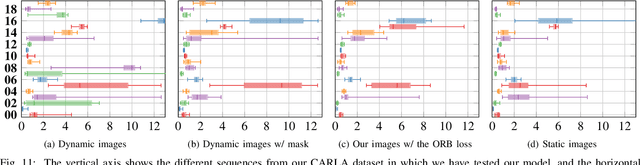
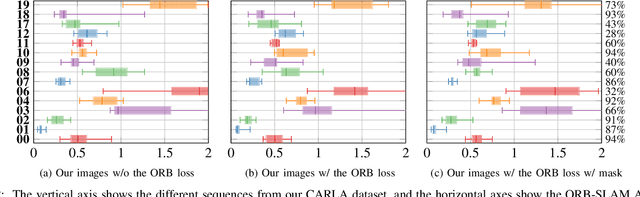
In this paper we present a data-driven approach to obtain the static image of a scene, eliminating dynamic objects that might have been present at the time of traversing the scene with a camera. The general objective is to improve vision-based localization and mapping tasks in dynamic environments, where the presence (or absence) of different dynamic objects in different moments makes these tasks less robust. We introduce an end-to-end deep learning framework to turn images of an urban environment that include dynamic content, such as vehicles or pedestrians, into realistic static frames suitable for localization and mapping. This objective faces two main challenges: detecting the dynamic objects, and inpainting the static occluded back-ground. The first challenge is addressed by the use of a convolutional network that learns a multi-class semantic segmentation of the image. The second challenge is approached with a generative adversarial model that, taking as input the original dynamic image and the computed dynamic/static binary mask, is capable of generating the final static image. This framework makes use of two new losses, one based on image steganalysis techniques, useful to improve the inpainting quality, and another one based on ORB features, designed to enhance feature matching between real and hallucinated image regions. To validate our approach, we perform an extensive evaluation on different tasks that are affected by dynamic entities, i.e., visual odometry, place recognition and multi-view stereo, with the hallucinated images. Code has been made available on https://github.com/bertabescos/EmptyCities_SLAM.
Sparse Optimization for Robust and Efficient Loop Closing
Jan 31, 2017
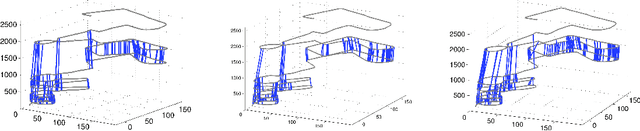

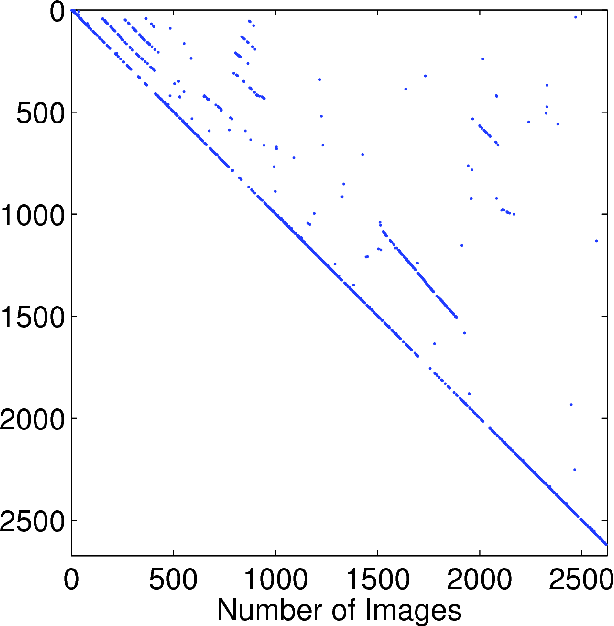
It is essential for a robot to be able to detect revisits or loop closures for long-term visual navigation.A key insight explored in this work is that the loop-closing event inherently occurs sparsely, that is, the image currently being taken matches with only a small subset (if any) of previous images. Based on this observation, we formulate the problem of loop-closure detection as a sparse, convex $\ell_1$-minimization problem. By leveraging fast convex optimization techniques, we are able to efficiently find loop closures, thus enabling real-time robot navigation. This novel formulation requires no offline dictionary learning, as required by most existing approaches, and thus allows online incremental operation. Our approach ensures a unique hypothesis by choosing only a single globally optimal match when making a loop-closure decision. Furthermore, the proposed formulation enjoys a flexible representation with no restriction imposed on how images should be represented, while requiring only that the representations are "close" to each other when the corresponding images are visually similar. The proposed algorithm is validated extensively using real-world datasets.
Past, Present, and Future of Simultaneous Localization And Mapping: Towards the Robust-Perception Age
Jan 30, 2017
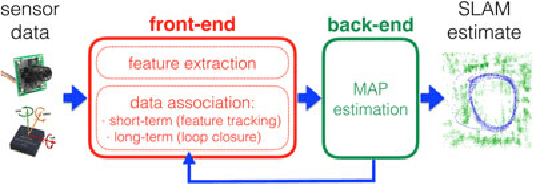
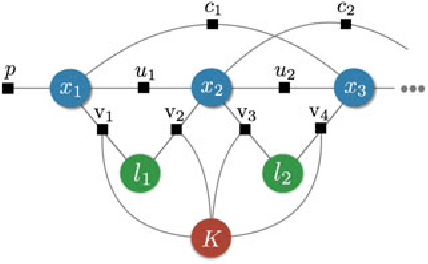
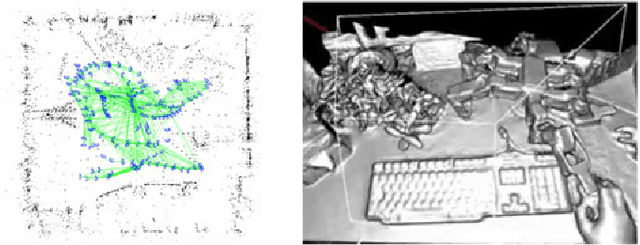
Simultaneous Localization and Mapping (SLAM)consists in the concurrent construction of a model of the environment (the map), and the estimation of the state of the robot moving within it. The SLAM community has made astonishing progress over the last 30 years, enabling large-scale real-world applications, and witnessing a steady transition of this technology to industry. We survey the current state of SLAM. We start by presenting what is now the de-facto standard formulation for SLAM. We then review related work, covering a broad set of topics including robustness and scalability in long-term mapping, metric and semantic representations for mapping, theoretical performance guarantees, active SLAM and exploration, and other new frontiers. This paper simultaneously serves as a position paper and tutorial to those who are users of SLAM. By looking at the published research with a critical eye, we delineate open challenges and new research issues, that still deserve careful scientific investigation. The paper also contains the authors' take on two questions that often animate discussions during robotics conferences: Do robots need SLAM? and Is SLAM solved?