 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Algorithms and Policies Using Adaptive and Machine Learning Approaches
May 27, 2021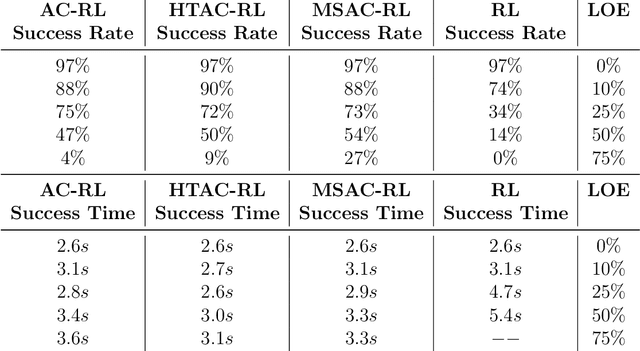
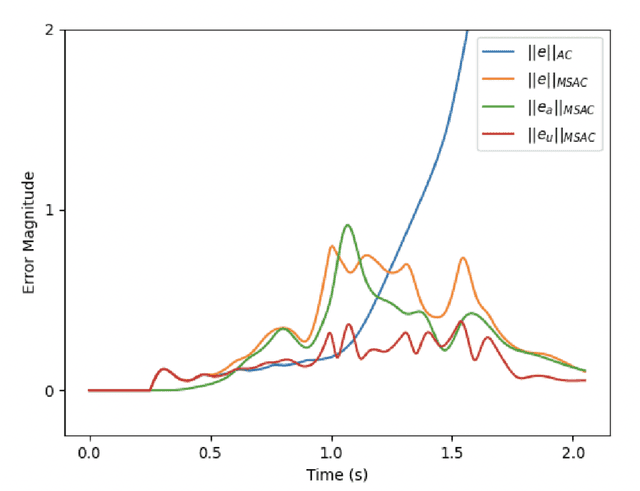
This paper considers the problem of real-time control and learning in dynamic systems subjected to uncertainties. Adaptive approaches are proposed to address the problem, which are combined to with methods and tools in Reinforcement Learning (RL) and Machine Learning (ML). Algorithms are proposed in continuous-time that combine adaptive approaches with RL leading to online control policies that guarantee stable behavior in the presence of parametric uncertainties that occur in real-time. Algorithms are proposed in discrete-time that combine adaptive approaches proposed for parameter and output estimation and ML approaches proposed for accelerated performance that guarantee stable estimation even in the presence of time-varying regressors, and for accelerated learning of the parameters with persistent excitation. Numerical validations of all algorithms are carried out using a quadrotor landing task on a moving platform and benchmark problems in ML. All results clearly point out the advantage of adaptive approaches for real-time control and learning.
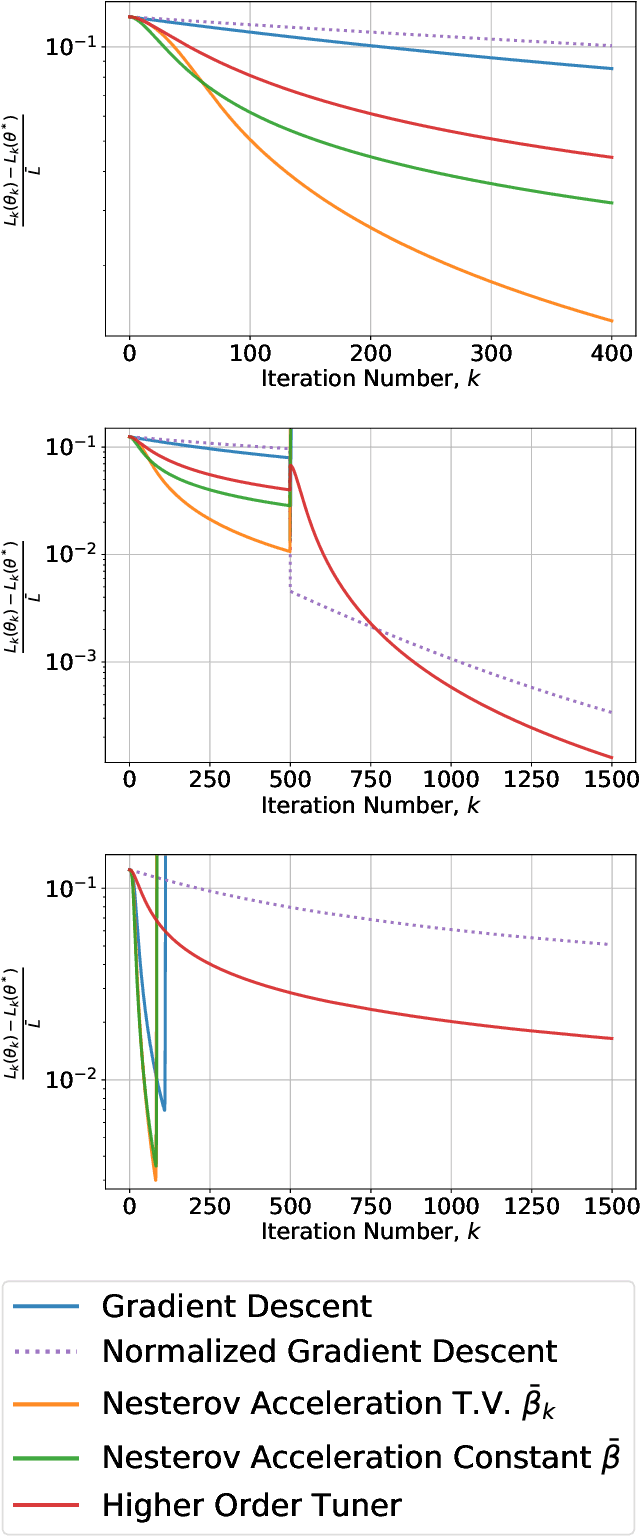
A Stable High-order Tuner for General Convex Functions
Nov 20, 2020

Iterative gradient-based algorithms have been increasingly applied for the training of a broad variety of machine learning models including large neural-nets. In particular, momentum-based methods, with accelerated learning guarantees, have received a lot of attention due to their provable guarantees of fast learning in certain classes of problems and multiple algorithms have been derived. However, properties for these methods hold true only for constant regressors. When time-varying regressors occur, which is commonplace in dynamic systems, many of these momentum-based methods cannot guarantee stability. Recently, a new High-order Tuner (HT) was developed and shown to have 1) stability and asymptotic convergence for time-varying regressors and 2) non-asymptotic accelerated learning guarantees for constant regressors. These results were derived for a linear regression framework producing a quadratic loss function. In this paper, we extend and discuss the results of this same HT for general convex loss functions. Through the exploitation of convexity and smoothness definitions, we establish similar stability and asymptotic convergence guarantees. Additionally we conjecture that the HT has an accelerated convergence rate. Finally, we provide numerical simulations supporting the satisfactory behavior of the HT algorithm as well as the conjecture of accelerated learning.
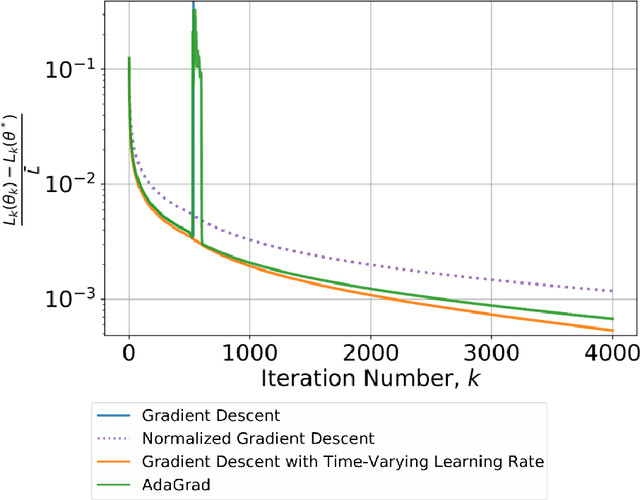
Accelerated Learning with Robustness to Adversarial Regressors
May 04, 2020


High order iterative momentum-based parameter update algorithms have seen widespread applications in training machine learning models. Recently, connections with variational approaches and continuous dynamics have led to the derivation of new classes of high order learning algorithms with accelerated learning guarantees. Such methods however, have only considered the case of static regressors. There is a significant need in continual/lifelong learning applications for parameter update algorithms which can be proven stable in the presence of adversarial time-varying regressors. In such settings, the learning algorithm must continually adapt to changes in the distribution of regressors. In this paper, we propose a new discrete time algorithm which: 1) provides stability and asymptotic convergence guarantees in the presence of adversarial regressors by leveraging insights from adaptive control theory and 2) provides non-asymptotic accelerated learning guarantees leveraging insights from convex optimization. In particular, our algorithm reaches an $\epsilon$ sub-optimal point in at most $\tilde{\mathcal{O}}(1/\sqrt{\epsilon})$ iterations when regressors are constant - matching lower bounds due to Nesterov of $\Omega(1/\sqrt{\epsilon})$, up to a $\log(1/\epsilon)$ factor and provides guaranteed bounds for stability when regressors are time-varying.