 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Algorithms and Policies Using Adaptive and Machine Learning Approaches
May 27, 2021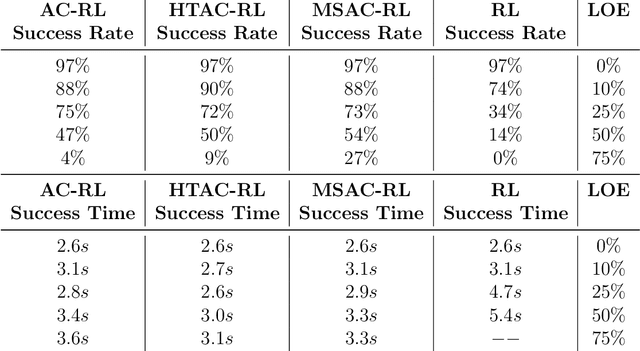
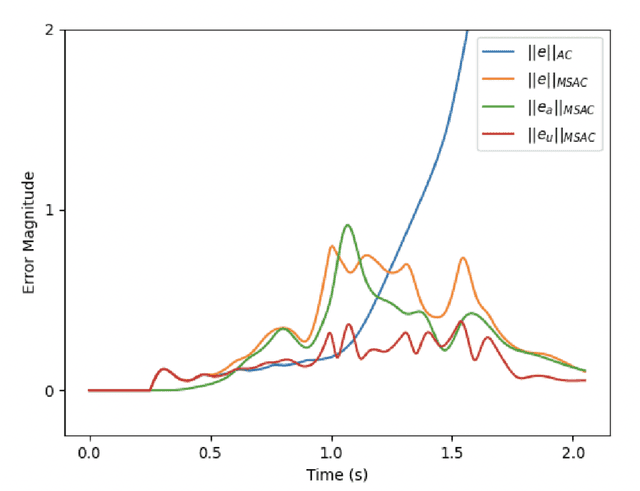
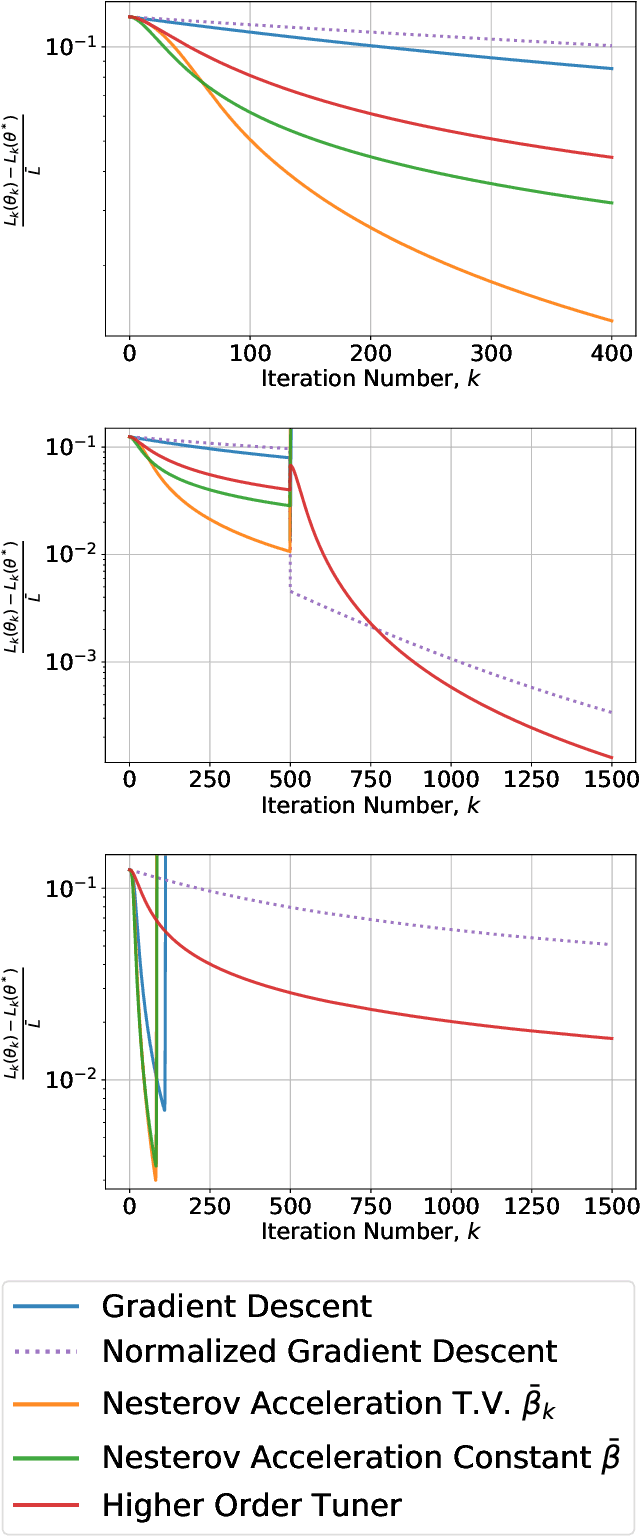
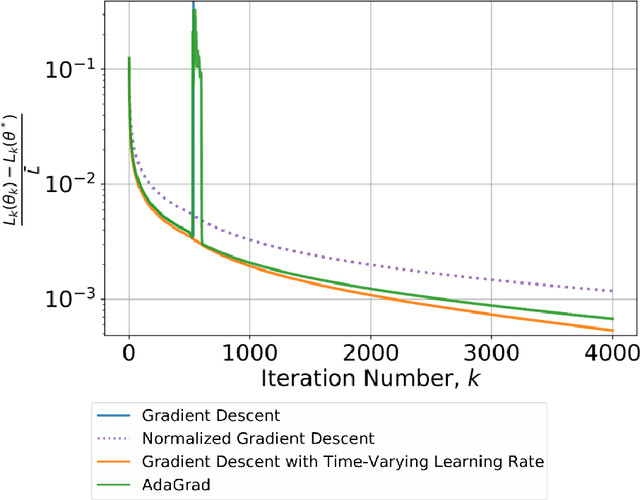
This paper considers the problem of real-time control and learning in dynamic systems subjected to uncertainties. Adaptive approaches are proposed to address the problem, which are combined to with methods and tools in Reinforcement Learning (RL) and Machine Learning (ML). Algorithms are proposed in continuous-time that combine adaptive approaches with RL leading to online control policies that guarantee stable behavior in the presence of parametric uncertainties that occur in real-time. Algorithms are proposed in discrete-time that combine adaptive approaches proposed for parameter and output estimation and ML approaches proposed for accelerated performance that guarantee stable estimation even in the presence of time-varying regressors, and for accelerated learning of the parameters with persistent excitation. Numerical validations of all algorithms are carried out using a quadrotor landing task on a moving platform and benchmark problems in ML. All results clearly point out the advantage of adaptive approaches for real-time control and learning.
MRAC-RL: A Framework for On-Line Policy Adaptation Under Parametric Model Uncertainty
Nov 20, 2020



Reinforcement learning (RL) algorithms have been successfully used to develop control policies for dynamical systems. For many such systems, these policies are trained in a simulated environment. Due to discrepancies between the simulated model and the true system dynamics, RL trained policies often fail to generalize and adapt appropriately when deployed in the real-world environment. Current research in bridging this sim-to-real gap has largely focused on improvements in simulation design and on the development of improved and specialized RL algorithms for robust control policy generation. In this paper we apply principles from adaptive control and system identification to develop the model-reference adaptive control & reinforcement learning (MRAC-RL) framework. We propose a set of novel MRAC algorithms applicable to a broad range of linear and nonlinear systems, and derive the associated control laws. The MRAC-RL framework utilizes an inner-loop adaptive controller that allows a simulation-trained outer-loop policy to adapt and operate effectively in a test environment, even when parametric model uncertainty exists. We demonstrate that the MRAC-RL approach improves upon state-of-the-art RL algorithms in developing control policies that can be applied to systems with modeling errors.