 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Trust-Region Algorithm for Noisy Equality Constrained Optimization
Nov 04, 2024This paper introduces a modified Byrd-Omojokun (BO) trust region algorithm to address the challenges posed by noisy function and gradient evaluations. The original BO method was designed to solve equality constrained problems and it forms the backbone of some interior point methods for general large-scale constrained optimization. A key strength of the BO method is its robustness in handling problems with rank-deficient constraint Jacobians. The algorithm proposed in this paper introduces a new criterion for accepting a step and for updating the trust region that makes use of an estimate in the noise in the problem. The analysis presented here gives conditions under which the iterates converge to regions of stationary points of the problem, determined by the level of noise. This analysis is more complex than for line search methods because the trust region carries (noisy) information from previous iterates. Numerical tests illustrate the practical performance of the algorithm.
Constrained and Composite Optimization via Adaptive Sampling Methods
Dec 31, 2020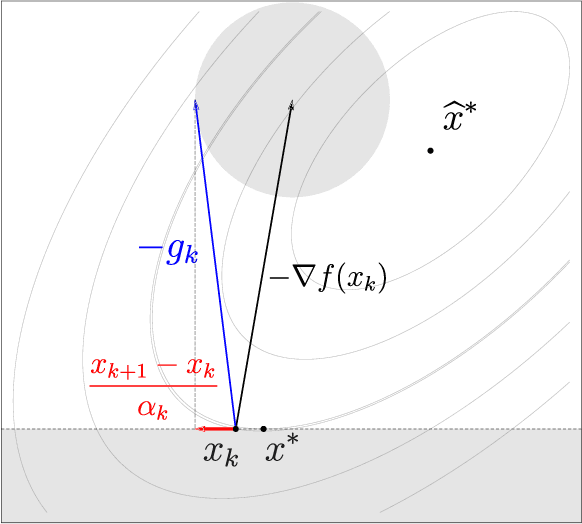
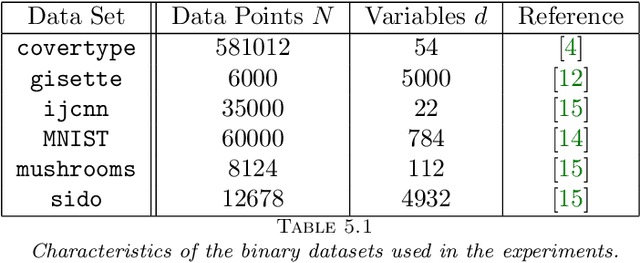
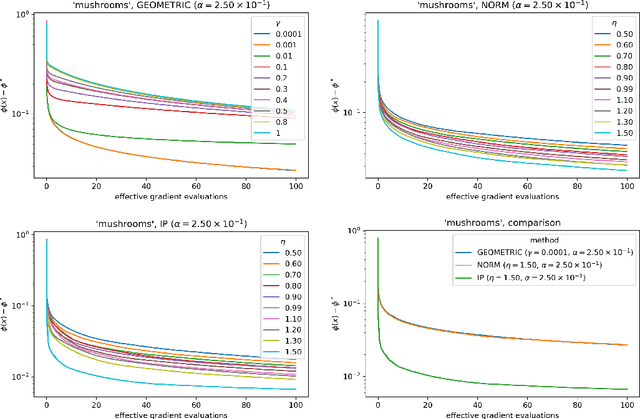
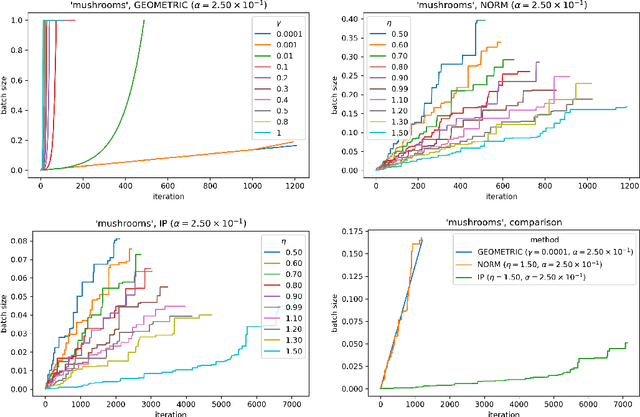
The motivation for this paper stems from the desire to develop an adaptive sampling method for solving constrained optimization problems in which the objective function is stochastic and the constraints are deterministic. The method proposed in this paper is a proximal gradient method that can also be applied to the composite optimization problem min f(x) + h(x), where f is stochastic and h is convex (but not necessarily differentiable). Adaptive sampling methods employ a mechanism for gradually improving the quality of the gradient approximation so as to keep computational cost to a minimum. The mechanism commonly employed in unconstrained optimization is no longer reliable in the constrained or composite optimization settings because it is based on pointwise decisions that cannot correctly predict the quality of the proximal gradient step. The method proposed in this paper measures the result of a complete step to determine if the gradient approximation is accurate enough; otherwise a more accurate gradient is generated and a new step is computed. Convergence results are established both for strongly convex and general convex f. Numerical experiments are presented to illustrate the practical behavior of the method.
An Investigation of Newton-Sketch and Subsampled Newton Methods
Jul 24, 2018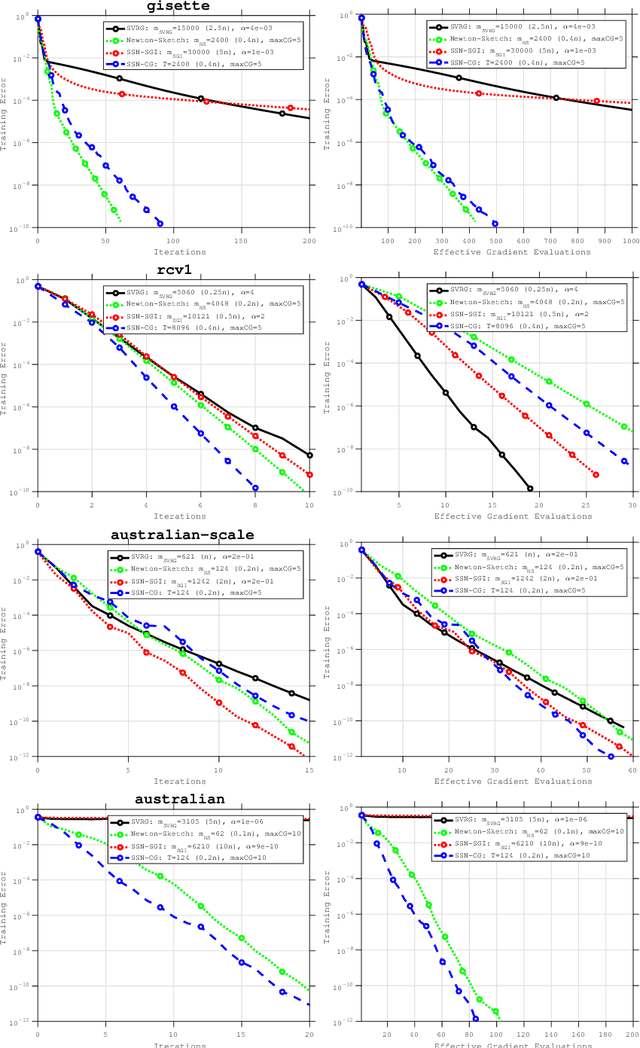
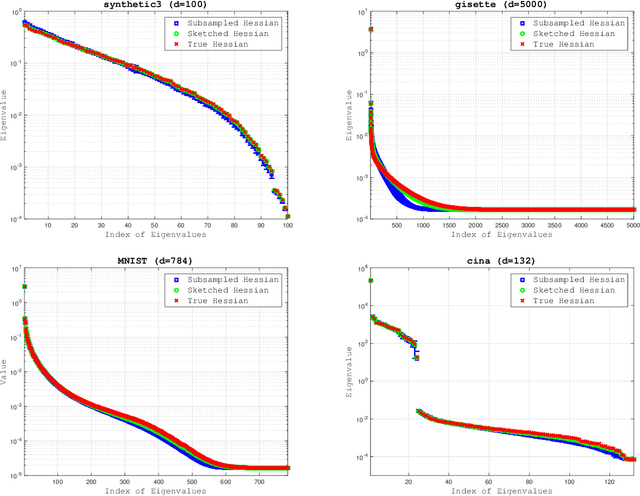
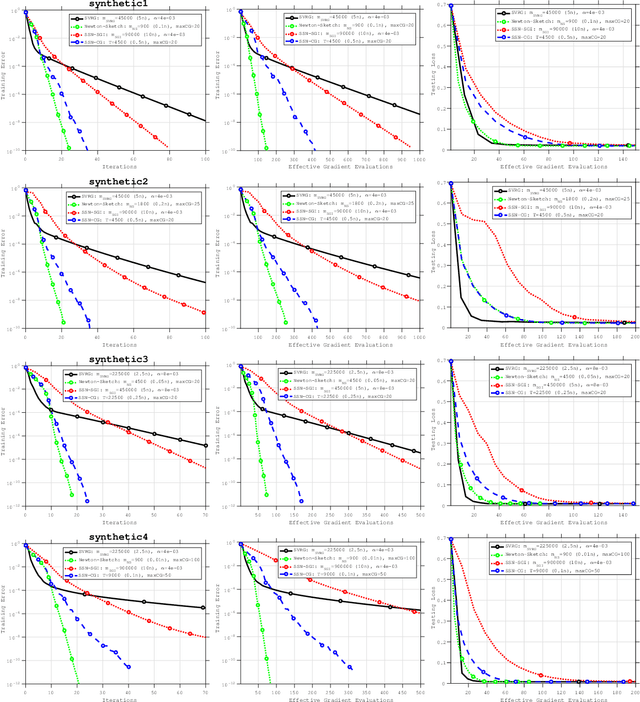
The concepts of sketching and subsampling have recently received much attention by the optimization and statistics communities. In this paper, we study Newton-Sketch and Subsampled Newton (SSN) methods for the finite-sum optimization problem. We consider practical versions of the two methods in which the Newton equations are solved approximately using the conjugate gradient (CG) method or a stochastic gradient iteration. We establish new complexity results for the SSN-CG method that exploit the spectral properties of CG. Controlled numerical experiments compare the relative strengths of Newton-Sketch and SSN methods and show that for many finite-sum problems, they are far more efficient than SVRG, a popular first-order method.
A Progressive Batching L-BFGS Method for Machine Learning
May 30, 2018
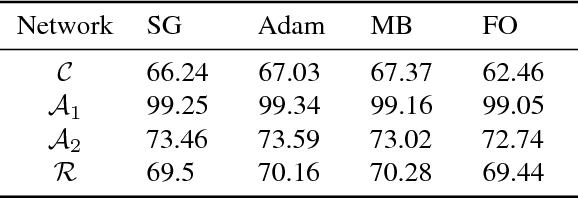

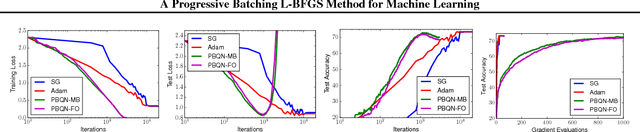
The standard L-BFGS method relies on gradient approximations that are not dominated by noise, so that search directions are descent directions, the line search is reliable, and quasi-Newton updating yields useful quadratic models of the objective function. All of this appears to call for a full batch approach, but since small batch sizes give rise to faster algorithms with better generalization properties, L-BFGS is currently not considered an algorithm of choice for large-scale machine learning applications. One need not, however, choose between the two extremes represented by the full batch or highly stochastic regimes, and may instead follow a progressive batching approach in which the sample size increases during the course of the optimization. In this paper, we present a new version of the L-BFGS algorithm that combines three basic components - progressive batching, a stochastic line search, and stable quasi-Newton updating - and that performs well on training logistic regression and deep neural networks. We provide supporting convergence theory for the method.
Optimization Methods for Large-Scale Machine Learning
Feb 08, 2018
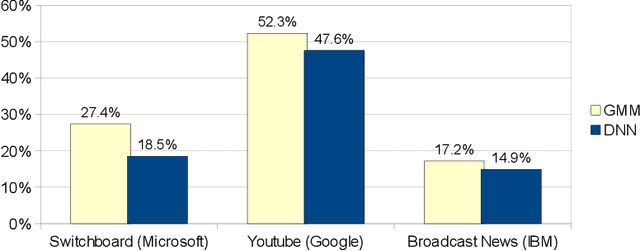
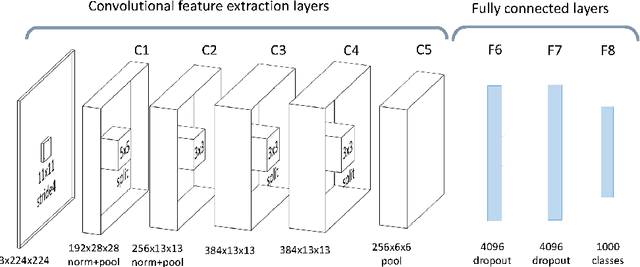
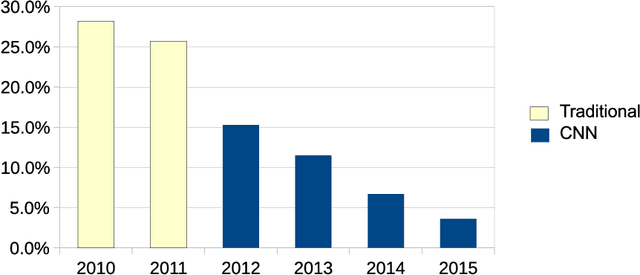
This paper provides a review and commentary on the past, present, and future of numerical optimization algorithms in the context of machine learning applications. Through case studies on text classification and the training of deep neural networks, we discuss how optimization problems arise in machine learning and what makes them challenging. A major theme of our study is that large-scale machine learning represents a distinctive setting in which the stochastic gradient (SG) method has traditionally played a central role while conventional gradient-based nonlinear optimization techniques typically falter. Based on this viewpoint, we present a comprehensive theory of a straightforward, yet versatile SG algorithm, discuss its practical behavior, and highlight opportunities for designing algorithms with improved performance. This leads to a discussion about the next generation of optimization methods for large-scale machine learning, including an investigation of two main streams of research on techniques that diminish noise in the stochastic directions and methods that make use of second-order derivative approximations.
Adaptive Sampling Strategies for Stochastic Optimization
Oct 30, 2017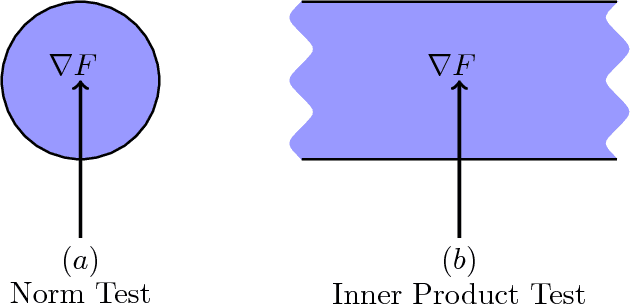
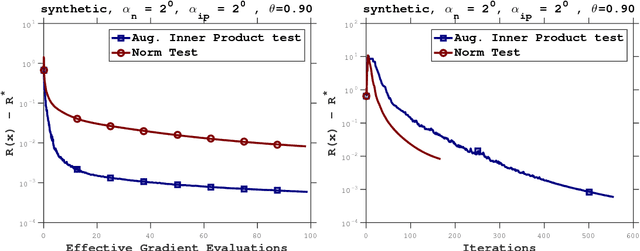
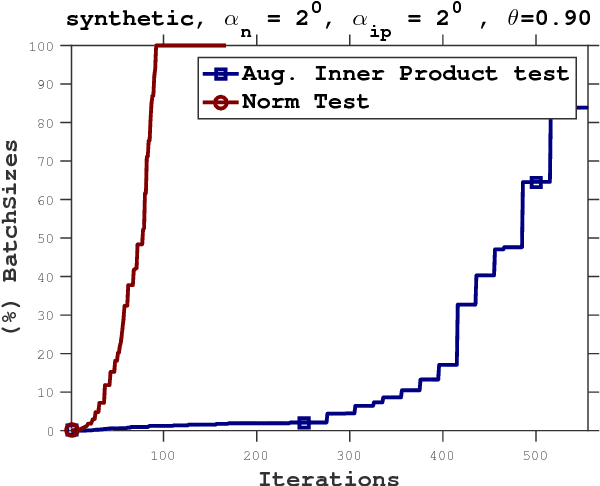
In this paper, we propose a stochastic optimization method that adaptively controls the sample size used in the computation of gradient approximations. Unlike other variance reduction techniques that either require additional storage or the regular computation of full gradients, the proposed method reduces variance by increasing the sample size as needed. The decision to increase the sample size is governed by an inner product test that ensures that search directions are descent directions with high probability. We show that the inner product test improves upon the well known norm test, and can be used as a basis for an algorithm that is globally convergent on nonconvex functions and enjoys a global linear rate of convergence on strongly convex functions. Numerical experiments on logistic regression problems illustrate the performance of the algorithm.
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Feb 09, 2017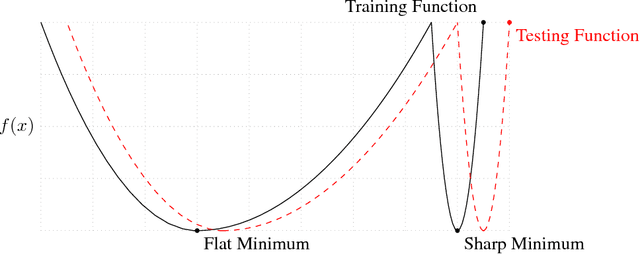
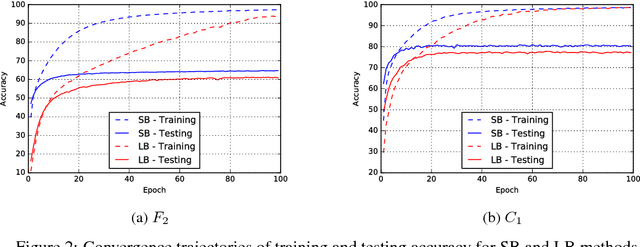
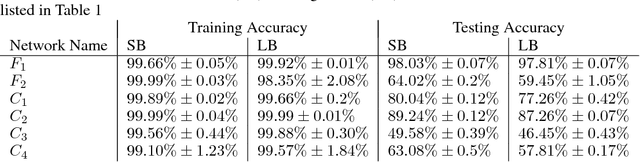
The stochastic gradient descent (SGD) method and its variants are algorithms of choice for many Deep Learning tasks. These methods operate in a small-batch regime wherein a fraction of the training data, say $32$-$512$ data points, is sampled to compute an approximation to the gradient. It has been observed in practice that when using a larger batch there is a degradation in the quality of the model, as measured by its ability to generalize. We investigate the cause for this generalization drop in the large-batch regime and present numerical evidence that supports the view that large-batch methods tend to converge to sharp minimizers of the training and testing functions - and as is well known, sharp minima lead to poorer generalization. In contrast, small-batch methods consistently converge to flat minimizers, and our experiments support a commonly held view that this is due to the inherent noise in the gradient estimation. We discuss several strategies to attempt to help large-batch methods eliminate this generalization gap.
A Multi-Batch L-BFGS Method for Machine Learning
Oct 23, 2016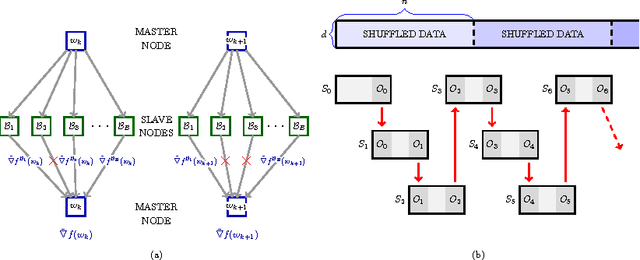
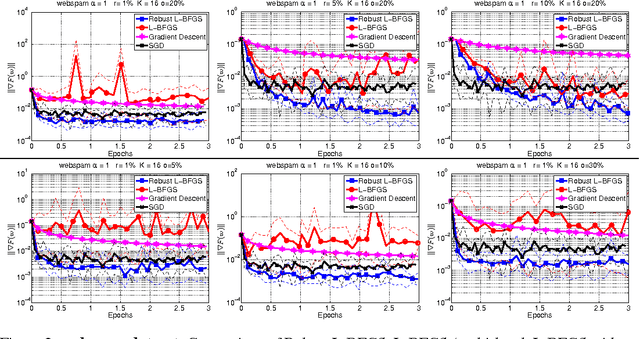
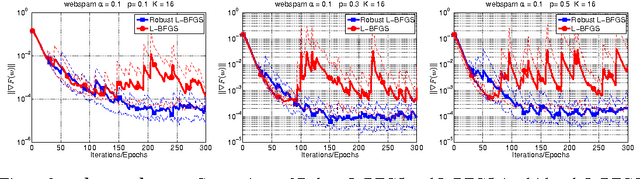
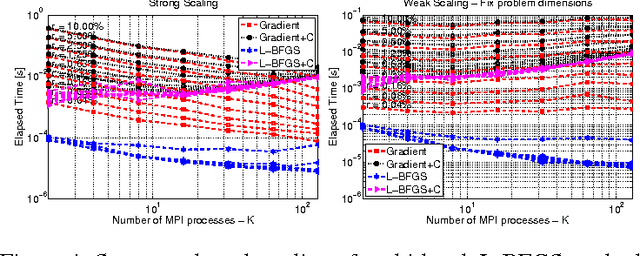
The question of how to parallelize the stochastic gradient descent (SGD) method has received much attention in the literature. In this paper, we focus instead on batch methods that use a sizeable fraction of the training set at each iteration to facilitate parallelism, and that employ second-order information. In order to improve the learning process, we follow a multi-batch approach in which the batch changes at each iteration. This can cause difficulties because L-BFGS employs gradient differences to update the Hessian approximations, and when these gradients are computed using different data points the process can be unstable. This paper shows how to perform stable quasi-Newton updating in the multi-batch setting, illustrates the behavior of the algorithm in a distributed computing platform, and studies its convergence properties for both the convex and nonconvex cases.
Exact and Inexact Subsampled Newton Methods for Optimization
Sep 27, 2016
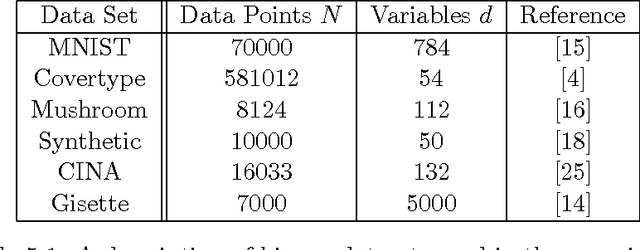
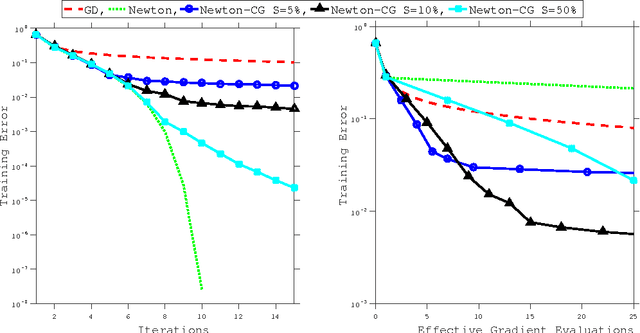
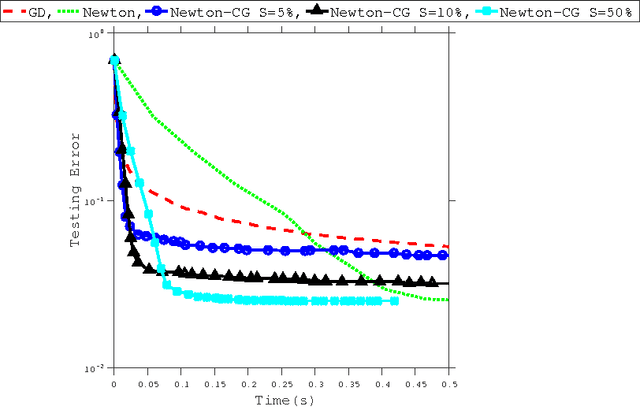
The paper studies the solution of stochastic optimization problems in which approximations to the gradient and Hessian are obtained through subsampling. We first consider Newton-like methods that employ these approximations and discuss how to coordinate the accuracy in the gradient and Hessian to yield a superlinear rate of convergence in expectation. The second part of the paper analyzes an inexact Newton method that solves linear systems approximately using the conjugate gradient (CG) method, and that samples the Hessian and not the gradient (the gradient is assumed to be exact). We provide a complexity analysis for this method based on the properties of the CG iteration and the quality of the Hessian approximation, and compare it with a method that employs a stochastic gradient iteration instead of the CG method. We report preliminary numerical results that illustrate the performance of inexact subsampled Newton methods on machine learning applications based on logistic regression.