 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Contrastive Learning Requires Incorporating Inductive Biases
Feb 28, 2022
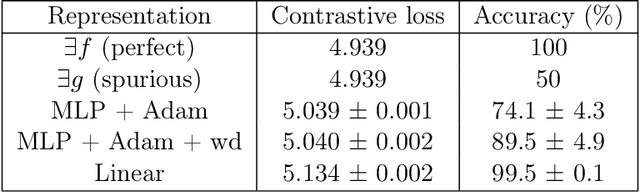

Contrastive learning is a popular form of self-supervised learning that encourages augmentations (views) of the same input to have more similar representations compared to augmentations of different inputs. Recent attempts to theoretically explain the success of contrastive learning on downstream classification tasks prove guarantees depending on properties of {\em augmentations} and the value of {\em contrastive loss} of representations. We demonstrate that such analyses, that ignore {\em inductive biases} of the function class and training algorithm, cannot adequately explain the success of contrastive learning, even {\em provably} leading to vacuous guarantees in some settings. Extensive experiments on image and text domains highlight the ubiquity of this problem -- different function classes and algorithms behave very differently on downstream tasks, despite having the same augmentations and contrastive losses. Theoretical analysis is presented for the class of linear representations, where incorporating inductive biases of the function class allows contrastive learning to work with less stringent conditions compared to prior analyses.
Learning Deep ResNet Blocks Sequentially using Boosting Theory
Jun 14, 2018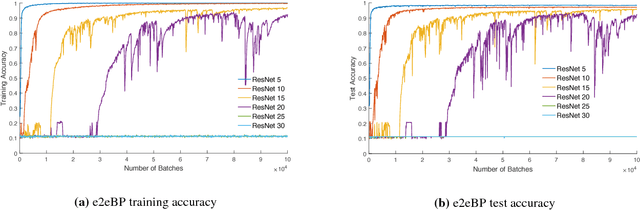
Deep neural networks are known to be difficult to train due to the instability of back-propagation. A deep \emph{residual network} (ResNet) with identity loops remedies this by stabilizing gradient computations. We prove a boosting theory for the ResNet architecture. We construct $T$ weak module classifiers, each contains two of the $T$ layers, such that the combined strong learner is a ResNet. Therefore, we introduce an alternative Deep ResNet training algorithm, \emph{BoostResNet}, which is particularly suitable in non-differentiable architectures. Our proposed algorithm merely requires a sequential training of $T$ "shallow ResNets" which are inexpensive. We prove that the training error decays exponentially with the depth $T$ if the \emph{weak module classifiers} that we train perform slightly better than some weak baseline. In other words, we propose a weak learning condition and prove a boosting theory for ResNet under the weak learning condition. Our results apply to general multi-class ResNets. A generalization error bound based on margin theory is proved and suggests ResNet's resistant to overfitting under network with $l_1$ norm bounded weights.