 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Contrastive Learning Requires Incorporating Inductive Biases
Paper and Code
Feb 28, 2022
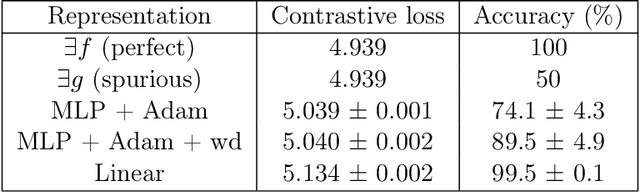

Contrastive learning is a popular form of self-supervised learning that encourages augmentations (views) of the same input to have more similar representations compared to augmentations of different inputs. Recent attempts to theoretically explain the success of contrastive learning on downstream classification tasks prove guarantees depending on properties of {\em augmentations} and the value of {\em contrastive loss} of representations. We demonstrate that such analyses, that ignore {\em inductive biases} of the function class and training algorithm, cannot adequately explain the success of contrastive learning, even {\em provably} leading to vacuous guarantees in some settings. Extensive experiments on image and text domains highlight the ubiquity of this problem -- different function classes and algorithms behave very differently on downstream tasks, despite having the same augmentations and contrastive losses. Theoretical analysis is presented for the class of linear representations, where incorporating inductive biases of the function class allows contrastive learning to work with less stringent conditions compared to prior analyses.