 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Coralscapes Dataset: Semantic Scene Understanding in Coral Reefs
Mar 25, 2025



Coral reefs are declining worldwide due to climate change and local stressors. To inform effective conservation or restoration, monitoring at the highest possible spatial and temporal resolution is necessary. Conventional coral reef surveying methods are limited in scalability due to their reliance on expert labor time, motivating the use of computer vision tools to automate the identification and abundance estimation of live corals from images. However, the design and evaluation of such tools has been impeded by the lack of large high quality datasets. We release the Coralscapes dataset, the first general-purpose dense semantic segmentation dataset for coral reefs, covering 2075 images, 39 benthic classes, and 174k segmentation masks annotated by experts. Coralscapes has a similar scope and the same structure as the widely used Cityscapes dataset for urban scene segmentation, allowing benchmarking of semantic segmentation models in a new challenging domain which requires expert knowledge to annotate. We benchmark a wide range of semantic segmentation models, and find that transfer learning from Coralscapes to existing smaller datasets consistently leads to state-of-the-art performance. Coralscapes will catalyze research on efficient, scalable, and standardized coral reef surveying methods based on computer vision, and holds the potential to streamline the development of underwater ecological robotics.
Scalable Semantic 3D Mapping of Coral Reefs with Deep Learning
Sep 22, 2023Coral reefs are among the most diverse ecosystems on our planet, and are depended on by hundreds of millions of people. Unfortunately, most coral reefs are existentially threatened by global climate change and local anthropogenic pressures. To better understand the dynamics underlying deterioration of reefs, monitoring at high spatial and temporal resolution is key. However, conventional monitoring methods for quantifying coral cover and species abundance are limited in scale due to the extensive manual labor required. Although computer vision tools have been employed to aid in this process, in particular SfM photogrammetry for 3D mapping and deep neural networks for image segmentation, analysis of the data products creates a bottleneck, effectively limiting their scalability. This paper presents a new paradigm for mapping underwater environments from ego-motion video, unifying 3D mapping systems that use machine learning to adapt to challenging conditions under water, combined with a modern approach for semantic segmentation of images. The method is exemplified on coral reefs in the northern Gulf of Aqaba, Red Sea, demonstrating high-precision 3D semantic mapping at unprecedented scale with significantly reduced required labor costs: a 100 m video transect acquired within 5 minutes of diving with a cheap consumer-grade camera can be fully automatically analyzed within 5 minutes. Our approach significantly scales up coral reef monitoring by taking a leap towards fully automatic analysis of video transects. The method democratizes coral reef transects by reducing the labor, equipment, logistics, and computing cost. This can help to inform conservation policies more efficiently. The underlying computational method of learning-based Structure-from-Motion has broad implications for fast low-cost mapping of underwater environments other than coral reefs.
Gradient-Based Learning of Discrete Structured Measurement Operators for Signal Recovery
Feb 07, 2022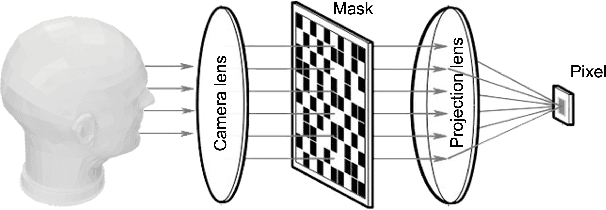
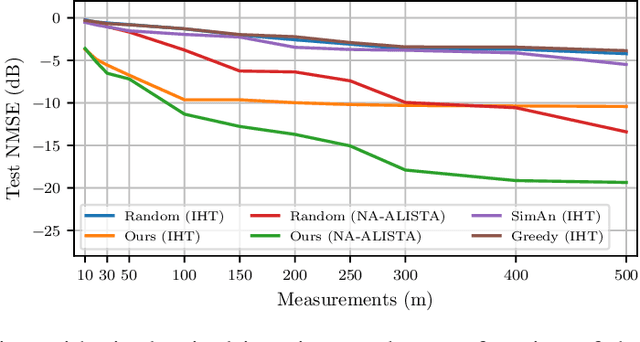
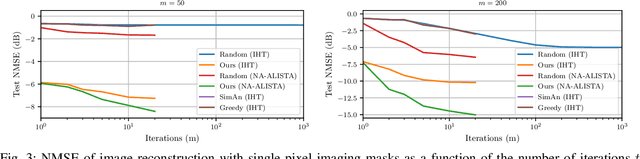

Countless signal processing applications include the reconstruction of signals from few indirect linear measurements. The design of effective measurement operators is typically constrained by the underlying hardware and physics, posing a challenging and often even discrete optimization task. While the potential of gradient-based learning via the unrolling of iterative recovery algorithms has been demonstrated, it has remained unclear how to leverage this technique when the set of admissible measurement operators is structured and discrete. We tackle this problem by combining unrolled optimization with Gumbel reparametrizations, which enable the computation of low-variance gradient estimates of categorical random variables. Our approach is formalized by GLODISMO (Gradient-based Learning of DIscrete Structured Measurement Operators). This novel method is easy-to-implement, computationally efficient, and extendable due to its compatibility with automatic differentiation. We empirically demonstrate the performance and flexibility of GLODISMO in several prototypical signal recovery applications, verifying that the learned measurement matrices outperform conventional designs based on randomization as well as discrete optimization baselines.
Neurally Augmented ALISTA
Oct 05, 2020
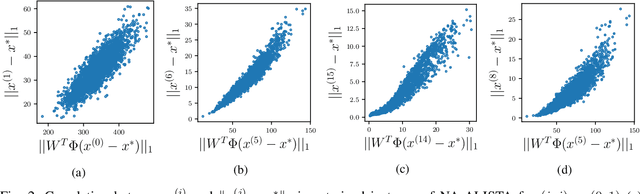
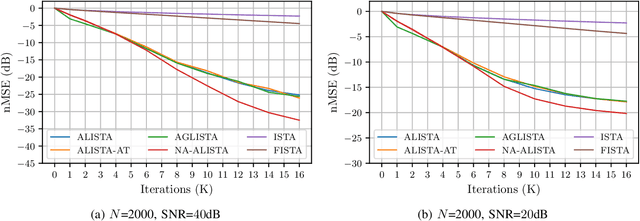
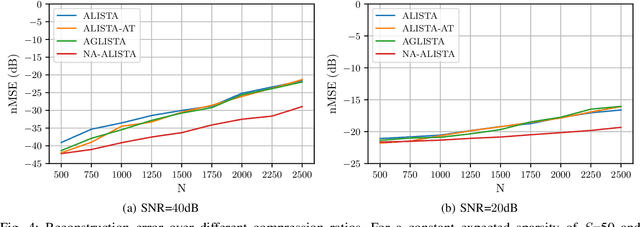
It is well-established that many iterative sparse reconstruction algorithms can be unrolled to yield a learnable neural network for improved empirical performance. A prime example is learned ISTA (LISTA) where weights, step sizes and thresholds are learned from training data. Recently, Analytic LISTA (ALISTA) has been introduced, combining the strong empirical performance of a fully learned approach like LISTA, while retaining theoretical guarantees of classical compressed sensing algorithms and significantly reducing the number of parameters to learn. However, these parameters are trained to work in expectation, often leading to suboptimal reconstruction of individual targets. In this work we therefore introduce Neurally Augmented ALISTA, in which an LSTM network is used to compute step sizes and thresholds individually for each target vector during reconstruction. This adaptive approach is theoretically motivated by revisiting the recovery guarantees of ALISTA. We show that our approach further improves empirical performance in sparse reconstruction, in particular outperforming existing algorithms by an increasing margin as the compression ratio becomes more challenging.
Context Prediction for Unsupervised Deep Learning on Point Clouds
Jan 24, 2019
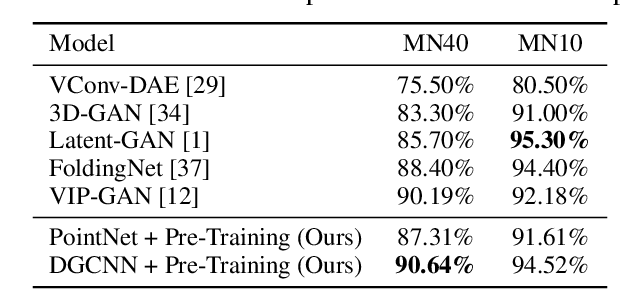
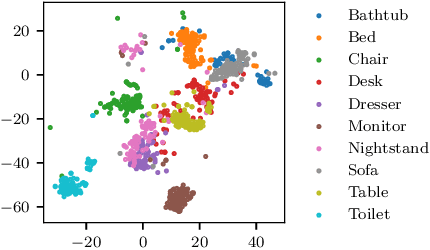

Point clouds provide a flexible and natural representation usable in countless applications such as robotics or self-driving cars. Recently, deep neural networks operating on raw point cloud data have shown promising results on supervised learning tasks such as object classification and semantic segmentation. While massive point cloud datasets can be captured using modern scanning technology, manually labelling such large 3D point clouds for supervised learning tasks is a cumbersome process. This necessitates effective unsupervised learning methods that can produce representations such that downstream tasks require significantly fewer annotated samples. We propose a novel method for unsupervised learning on raw point cloud data in which a neural network is trained to predict the spatial relationship between two point cloud segments. While solving this task, representations that capture semantic properties of the point cloud are learned. Our method outperforms previous unsupervised learning approaches in downstream object classification and segmentation tasks and performs on par with fully supervised methods.