 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurface-based parcellation and vertex-wise analysis of ultra high-resolution ex vivo 7 tesla MRI in neurodegenerative diseases
Mar 28, 2024



Magnetic resonance imaging (MRI) is the standard modality to understand human brain structure and function in vivo (antemortem). Decades of research in human neuroimaging has led to the widespread development of methods and tools to provide automated volume-based segmentations and surface-based parcellations which help localize brain functions to specialized anatomical regions. Recently ex vivo (postmortem) imaging of the brain has opened-up avenues to study brain structure at sub-millimeter ultra high-resolution revealing details not possible to observe with in vivo MRI. Unfortunately, there has been limited methodological development in ex vivo MRI primarily due to lack of datasets and limited centers with such imaging resources. Therefore, in this work, we present one-of-its-kind dataset of 82 ex vivo T2w whole brain hemispheres MRI at 0.3 mm isotropic resolution spanning Alzheimer's disease and related dementias. We adapted and developed a fast and easy-to-use automated surface-based pipeline to parcellate, for the first time, ultra high-resolution ex vivo brain tissue at the native subject space resolution using the Desikan-Killiany-Tourville (DKT) brain atlas. This allows us to perform vertex-wise analysis in the template space and thereby link morphometry measures with pathology measurements derived from histology. We will open-source our dataset docker container, Jupyter notebooks for ready-to-use out-of-the-box set of tools and command line options to advance ex vivo MRI clinical brain imaging research on the project webpage.
Automated deep learning segmentation of high-resolution 7 T ex vivo MRI for quantitative analysis of structure-pathology correlations in neurodegenerative diseases
Mar 21, 2023



Ex vivo MRI of the brain provides remarkable advantages over in vivo MRI for visualizing and characterizing detailed neuroanatomy, and helps to link microscale histology studies with morphometric measurements. However, automated segmentation methods for brain mapping in ex vivo MRI are not well developed, primarily due to limited availability of labeled datasets, and heterogeneity in scanner hardware and acquisition protocols. In this work, we present a high resolution dataset of 37 ex vivo post-mortem human brain tissue specimens scanned on a 7T whole-body MRI scanner. We developed a deep learning pipeline to segment the cortical mantle by benchmarking the performance of nine deep neural architectures. We then segment the four subcortical structures: caudate, putamen, globus pallidus, and thalamus; white matter hyperintensities, and the normal appearing white matter. We show excellent generalizing capabilities across whole brain hemispheres in different specimens, and also on unseen images acquired at different magnetic field strengths and different imaging sequence. We then compute volumetric and localized cortical thickness measurements across key regions, and link them with semi-quantitative neuropathological ratings. Our code, containerized executables, and the processed datasets are publicly available at: https://github.com/Pulkit-Khandelwal/upenn-picsl-brain-ex-vivo.
Gray Matter Segmentation in Ultra High Resolution 7 Tesla ex vivo T2w MRI of Human Brain Hemispheres
Oct 14, 2021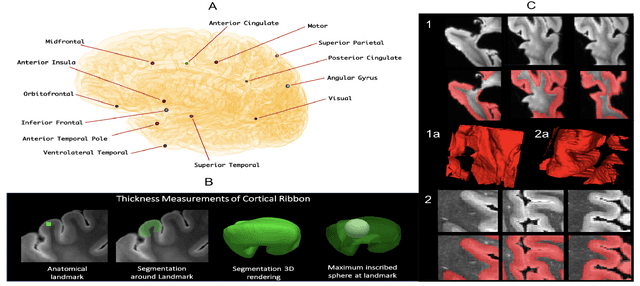
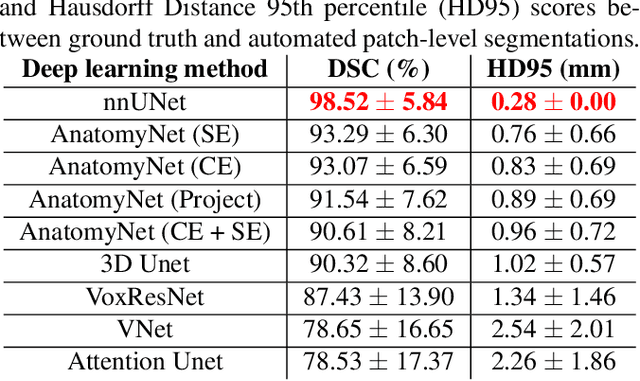
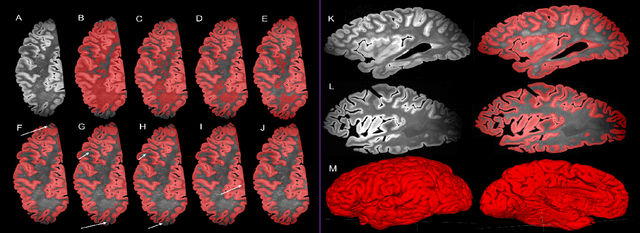
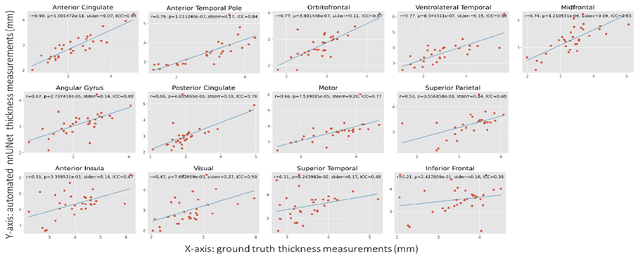
Ex vivo MRI of the brain provides remarkable advantages over in vivo MRI for visualizing and characterizing detailed neuroanatomy. However, automated cortical segmentation methods in ex vivo MRI are not well developed, primarily due to limited availability of labeled datasets, and heterogeneity in scanner hardware and acquisition protocols. In this work, we present a high resolution 7 Tesla dataset of 32 ex vivo human brain specimens. We benchmark the cortical mantle segmentation performance of nine neural network architectures, trained and evaluated using manually-segmented 3D patches sampled from specific cortical regions, and show excellent generalizing capabilities across whole brain hemispheres in different specimens, and also on unseen images acquired at different magnetic field strength and imaging sequences. Finally, we provide cortical thickness measurements across key regions in 3D ex vivo human brain images. Our code and processed datasets are publicly available at https://github.com/Pulkit-Khandelwal/picsl-ex-vivo-segmentation.
Masked Conditional Neural Networks for Environmental Sound Classification
May 25, 2018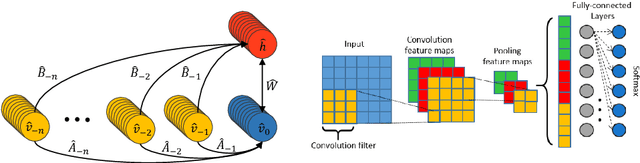



The ConditionaL Neural Network (CLNN) exploits the nature of the temporal sequencing of the sound signal represented in a spectrogram, and its variant the Masked ConditionaL Neural Network (MCLNN) induces the network to learn in frequency bands by embedding a filterbank-like sparseness over the network's links using a binary mask. Additionally, the masking automates the exploration of different feature combinations concurrently analogous to handcrafting the optimum combination of features for a recognition task. We have evaluated the MCLNN performance using the Urbansound8k dataset of environmental sounds. Additionally, we present a collection of manually recorded sounds for rail and road traffic, YorNoise, to investigate the confusion rates among machine generated sounds possessing low-frequency components. MCLNN has achieved competitive results without augmentation and using 12% of the trainable parameters utilized by an equivalent model based on state-of-the-art Convolutional Neural Networks on the Urbansound8k. We extended the Urbansound8k dataset with YorNoise, where experiments have shown that common tonal properties affect the classification performance.
* Conditional Neural Networks, CLNN, Masked Conditional Neural Networks, MCLNN, Restricted Boltzmann Machine, RBM, Conditional Restricted Boltz-mann Machine, CRBM, Deep Belief Nets, Environmental Sound Recognition, ESR, YorNoise
Environmental Sound Recognition using Masked Conditional Neural Networks
Apr 08, 2018
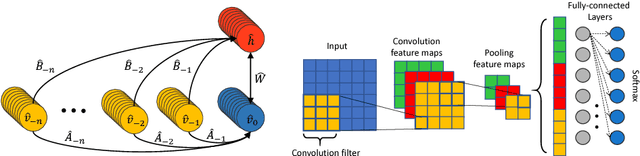
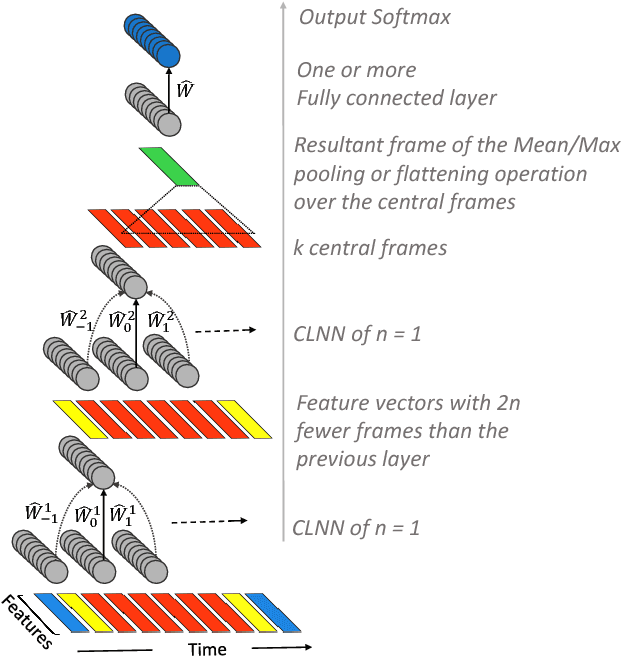
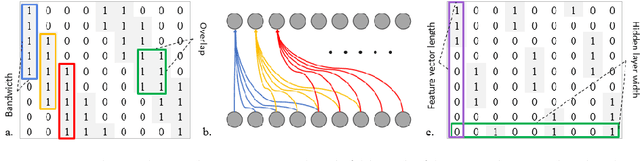
Neural network based architectures used for sound recognition are usually adapted from other application domains, which may not harness sound related properties. The ConditionaL Neural Network (CLNN) is designed to consider the relational properties across frames in a temporal signal, and its extension the Masked ConditionaL Neural Network (MCLNN) embeds a filterbank behavior within the network, which enforces the network to learn in frequency bands rather than bins. Additionally, it automates the exploration of different feature combinations analogous to handcrafting the optimum combination of features for a recognition task. We applied the MCLNN to the environmental sounds of the ESC-10 dataset. The MCLNN achieved competitive accuracies compared to state-of-the-art convolutional neural networks and hand-crafted attempts.
Masked Conditional Neural Networks for Audio Classification
Mar 06, 2018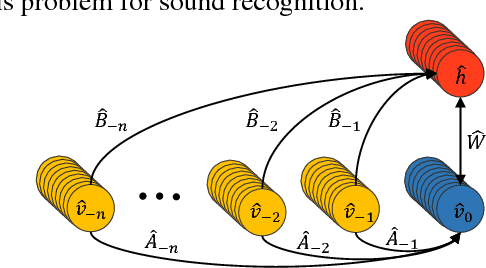
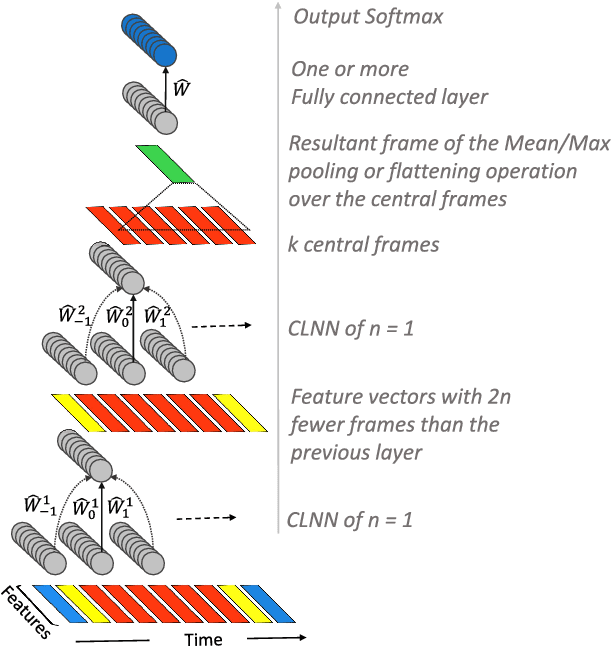
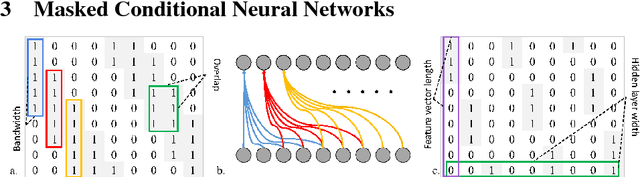
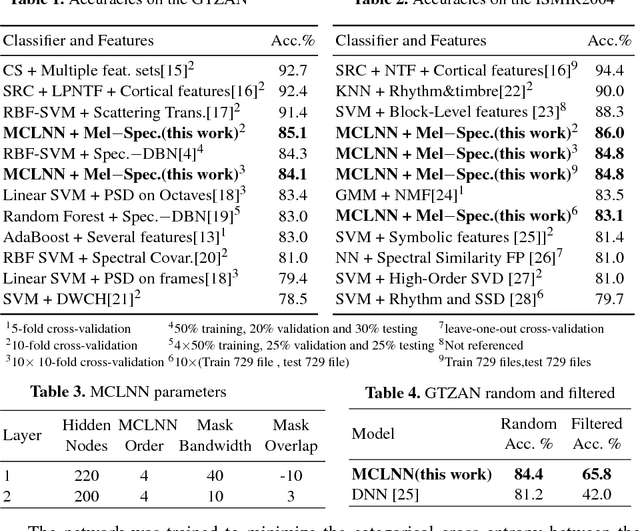
We present the ConditionaL Neural Network (CLNN) and the Masked ConditionaL Neural Network (MCLNN) designed for temporal signal recognition. The CLNN takes into consideration the temporal nature of the sound signal and the MCLNN extends upon the CLNN through a binary mask to preserve the spatial locality of the features and allows an automated exploration of the features combination analogous to hand-crafting the most relevant features for the recognition task. MCLNN has achieved competitive recognition accuracies on the GTZAN and the ISMIR2004 music datasets that surpass several state-of-the-art neural network based architectures and hand-crafted methods applied on both datasets.
* Restricted BoltzmannMachine, RBM, Conditional Restricted Boltzmann Machine, CRBM, Music Information Retrieval, MIR, Conditional Neural Network, CLNN, Masked Conditional Neural Network, MCLNN, Deep Neural Network
Music Genre Classification using Masked Conditional Neural Networks
Feb 18, 2018
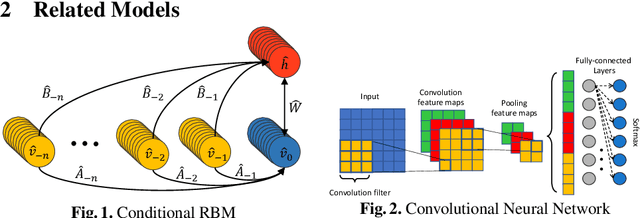
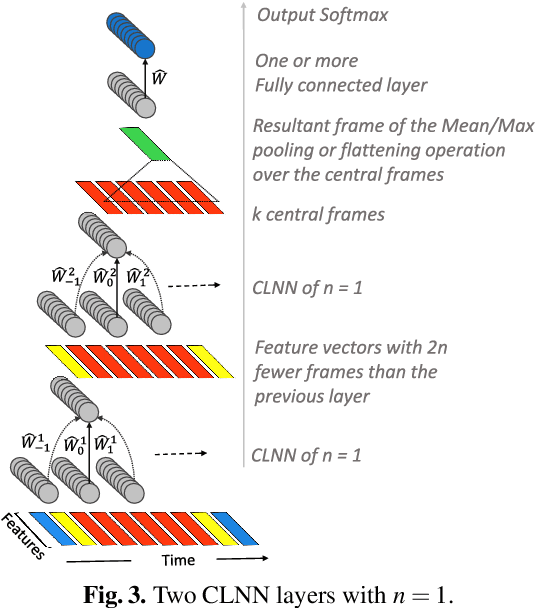

The ConditionaL Neural Networks (CLNN) and the Masked ConditionaL Neural Networks (MCLNN) exploit the nature of multi-dimensional temporal signals. The CLNN captures the conditional temporal influence between the frames in a window and the mask in the MCLNN enforces a systematic sparseness that follows a filterbank-like pattern over the network links. The mask induces the network to learn about time-frequency representations in bands, allowing the network to sustain frequency shifts. Additionally, the mask in the MCLNN automates the exploration of a range of feature combinations, usually done through an exhaustive manual search. We have evaluated the MCLNN performance using the Ballroom and Homburg datasets of music genres. MCLNN has achieved accuracies that are competitive to state-of-the-art handcrafted attempts in addition to models based on Convolutional Neural Networks.
* Conditional Neural Networks (CLNN), Masked Conditional Neural Networks (MCLNN), Conditional Restricted Boltzmann Machine (CRBM), Deep Belief Nets (DBN), Music Information Retrieval (MIR)
Masked Conditional Neural Networks for Automatic Sound Events Recognition
Feb 15, 2018


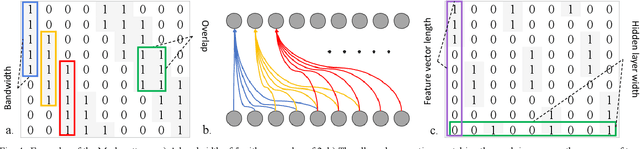
Deep neural network architectures designed for application domains other than sound, especially image recognition, may not optimally harness the time-frequency representation when adapted to the sound recognition problem. In this work, we explore the ConditionaL Neural Network (CLNN) and the Masked ConditionaL Neural Network (MCLNN) for multi-dimensional temporal signal recognition. The CLNN considers the inter-frame relationship, and the MCLNN enforces a systematic sparseness over the network's links to enable learning in frequency bands rather than bins allowing the network to be frequency shift invariant mimicking a filterbank. The mask also allows considering several combinations of features concurrently, which is usually handcrafted through exhaustive manual search. We applied the MCLNN to the environmental sound recognition problem using the ESC-10 and ESC-50 datasets. MCLNN achieved competitive performance, using 12% of the parameters and without augmentation, compared to state-of-the-art Convolutional Neural Networks.
* Restricted Boltzmann Machine, RBM, Conditional RBM, CRBM, Deep Belief Net, DBN, Conditional Neural Network, CLNN, Masked Conditional Neural Network, MCLNN, Environmental Sound Recognition, ESR
Recognition of Acoustic Events Using Masked Conditional Neural Networks
Feb 07, 2018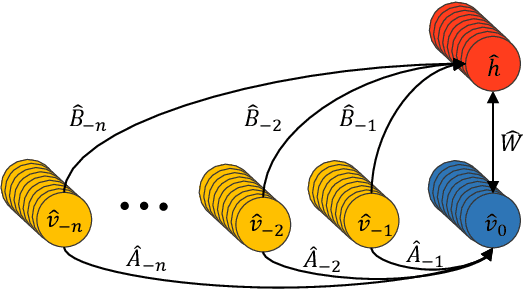
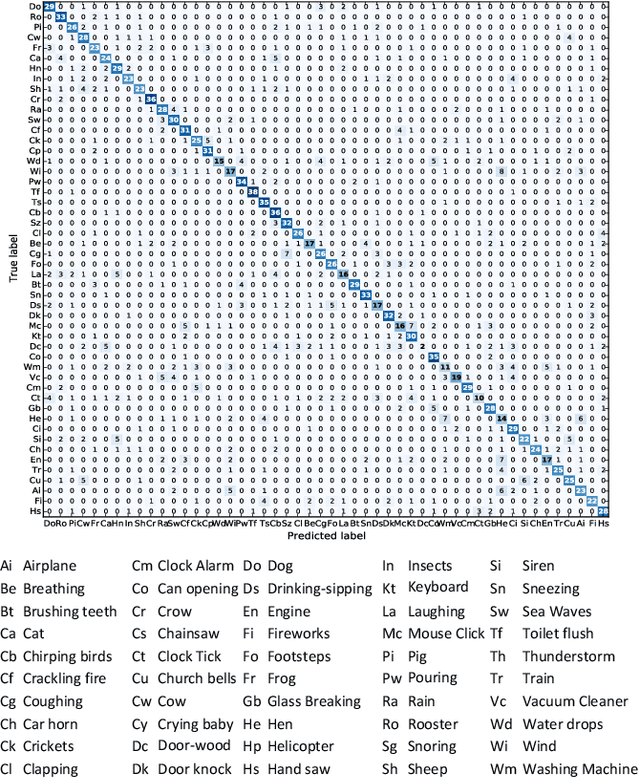


Automatic feature extraction using neural networks has accomplished remarkable success for images, but for sound recognition, these models are usually modified to fit the nature of the multi-dimensional temporal representation of the audio signal in spectrograms. This may not efficiently harness the time-frequency representation of the signal. The ConditionaL Neural Network (CLNN) takes into consideration the interrelation between the temporal frames, and the Masked ConditionaL Neural Network (MCLNN) extends upon the CLNN by forcing a systematic sparseness over the network's weights using a binary mask. The masking allows the network to learn about frequency bands rather than bins, mimicking a filterbank used in signal transformations such as MFCC. Additionally, the Mask is designed to consider various combinations of features, which automates the feature hand-crafting process. We applied the MCLNN for the Environmental Sound Recognition problem using the Urbansound8k, YorNoise, ESC-10 and ESC-50 datasets. The MCLNN have achieved competitive performance compared to state-of-the-art Convolutional Neural Networks and hand-crafted attempts.
* Restricted Boltzmann Machine, RBM, Conditional Restricted Boltzmann Machine, CRBM, Conditional Neural Networks, CLNN, Masked Conditional Neural Networks, MCLNN, Deep Neural Network, Environmental Sound Recognition, ESR
Automatic Classification of Music Genre using Masked Conditional Neural Networks
Jan 16, 2018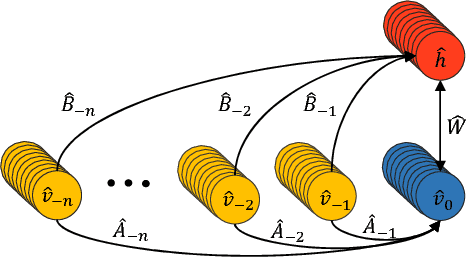
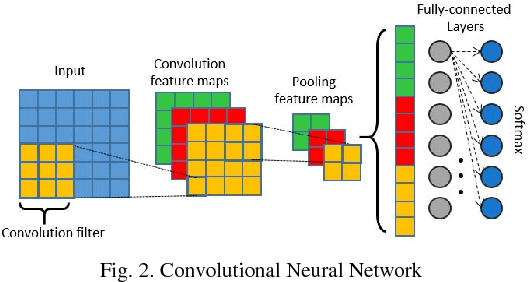
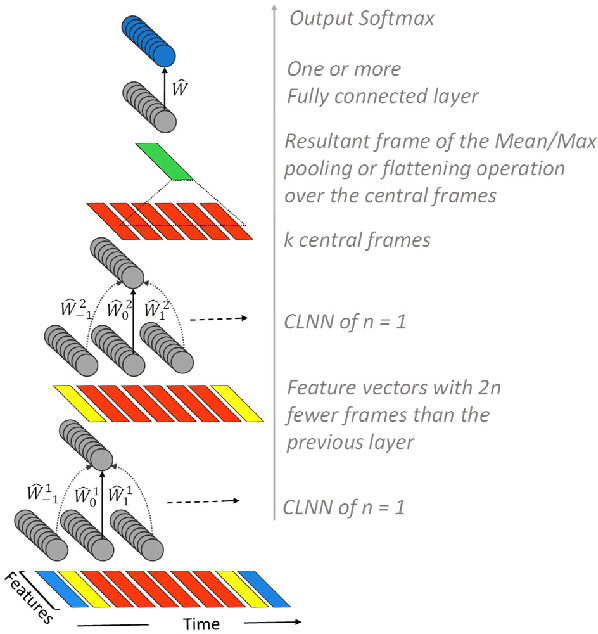
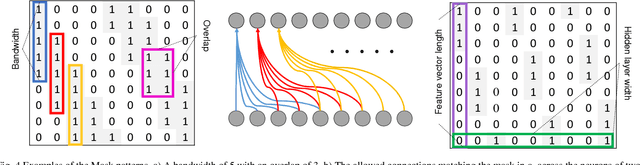
Neural network based architectures used for sound recognition are usually adapted from other application domains such as image recognition, which may not harness the time-frequency representation of a signal. The ConditionaL Neural Networks (CLNN) and its extension the Masked ConditionaL Neural Networks (MCLNN) are designed for multidimensional temporal signal recognition. The CLNN is trained over a window of frames to preserve the inter-frame relation, and the MCLNN enforces a systematic sparseness over the network's links that mimics a filterbank-like behavior. The masking operation induces the network to learn in frequency bands, which decreases the network susceptibility to frequency-shifts in time-frequency representations. Additionally, the mask allows an exploration of a range of feature combinations concurrently analogous to the manual handcrafting of the optimum collection of features for a recognition task. MCLNN have achieved competitive performance on the Ballroom music dataset compared to several hand-crafted attempts and outperformed models based on state-of-the-art Convolutional Neural Networks.
* Restricted Boltzmann Machine; RBM; Conditional RBM; CRBM; Deep Belief Net; DBN; Conditional Neural Network; CLNN; Masked Conditional Neural Network; MCLNN; Music Information Retrieval; MIR. IEEE International Conference on Data Mining (ICDM), 2017