 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Conditional Neural Networks for Automatic Sound Events Recognition
Paper and Code



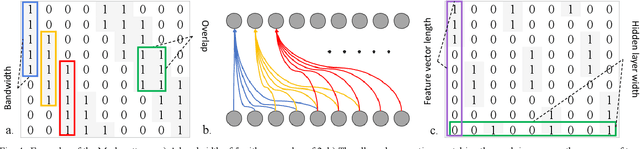
Deep neural network architectures designed for application domains other than sound, especially image recognition, may not optimally harness the time-frequency representation when adapted to the sound recognition problem. In this work, we explore the ConditionaL Neural Network (CLNN) and the Masked ConditionaL Neural Network (MCLNN) for multi-dimensional temporal signal recognition. The CLNN considers the inter-frame relationship, and the MCLNN enforces a systematic sparseness over the network's links to enable learning in frequency bands rather than bins allowing the network to be frequency shift invariant mimicking a filterbank. The mask also allows considering several combinations of features concurrently, which is usually handcrafted through exhaustive manual search. We applied the MCLNN to the environmental sound recognition problem using the ESC-10 and ESC-50 datasets. MCLNN achieved competitive performance, using 12% of the parameters and without augmentation, compared to state-of-the-art Convolutional Neural Networks.