 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironmental Sound Recognition using Masked Conditional Neural Networks
Paper and Code

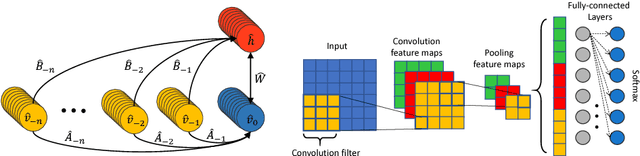
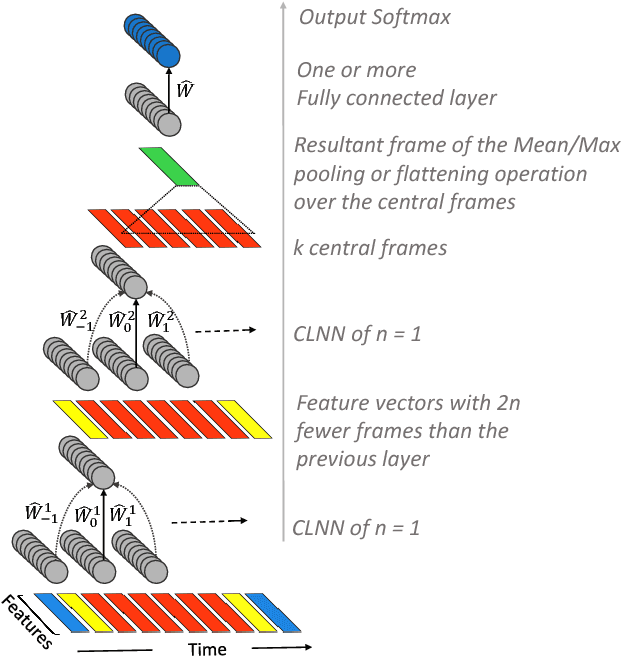
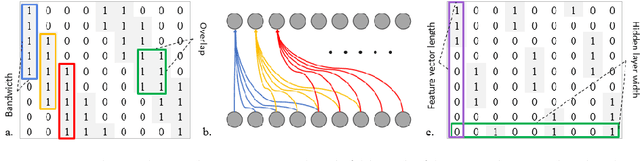
Neural network based architectures used for sound recognition are usually adapted from other application domains, which may not harness sound related properties. The ConditionaL Neural Network (CLNN) is designed to consider the relational properties across frames in a temporal signal, and its extension the Masked ConditionaL Neural Network (MCLNN) embeds a filterbank behavior within the network, which enforces the network to learn in frequency bands rather than bins. Additionally, it automates the exploration of different feature combinations analogous to handcrafting the optimum combination of features for a recognition task. We applied the MCLNN to the environmental sounds of the ESC-10 dataset. The MCLNN achieved competitive accuracies compared to state-of-the-art convolutional neural networks and hand-crafted attempts.