 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Conditional Neural Networks for Environmental Sound Classification
Paper and Code
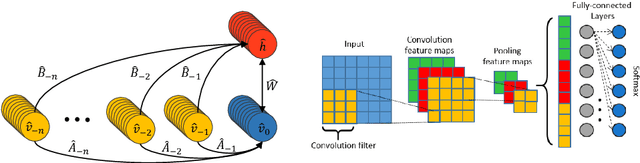



The ConditionaL Neural Network (CLNN) exploits the nature of the temporal sequencing of the sound signal represented in a spectrogram, and its variant the Masked ConditionaL Neural Network (MCLNN) induces the network to learn in frequency bands by embedding a filterbank-like sparseness over the network's links using a binary mask. Additionally, the masking automates the exploration of different feature combinations concurrently analogous to handcrafting the optimum combination of features for a recognition task. We have evaluated the MCLNN performance using the Urbansound8k dataset of environmental sounds. Additionally, we present a collection of manually recorded sounds for rail and road traffic, YorNoise, to investigate the confusion rates among machine generated sounds possessing low-frequency components. MCLNN has achieved competitive results without augmentation and using 12% of the trainable parameters utilized by an equivalent model based on state-of-the-art Convolutional Neural Networks on the Urbansound8k. We extended the Urbansound8k dataset with YorNoise, where experiments have shown that common tonal properties affect the classification performance.