 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Genre Classification using Masked Conditional Neural Networks
Paper and Code

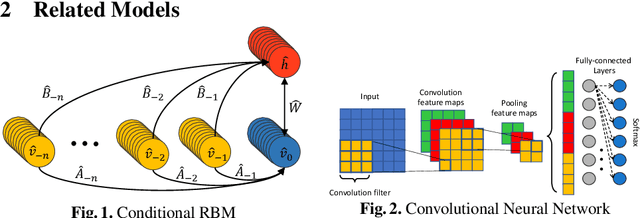
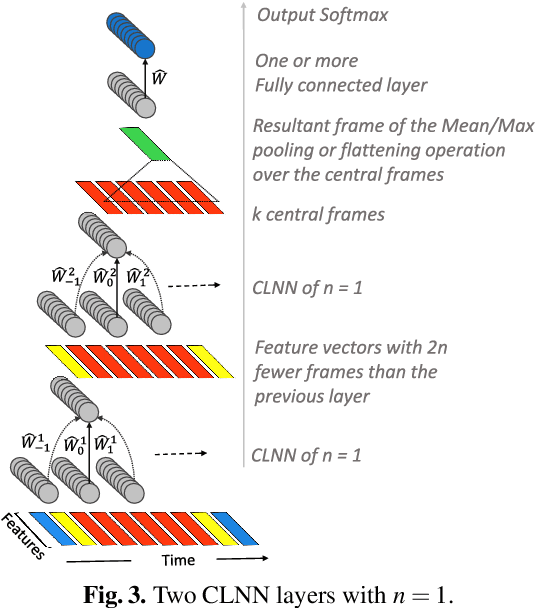

The ConditionaL Neural Networks (CLNN) and the Masked ConditionaL Neural Networks (MCLNN) exploit the nature of multi-dimensional temporal signals. The CLNN captures the conditional temporal influence between the frames in a window and the mask in the MCLNN enforces a systematic sparseness that follows a filterbank-like pattern over the network links. The mask induces the network to learn about time-frequency representations in bands, allowing the network to sustain frequency shifts. Additionally, the mask in the MCLNN automates the exploration of a range of feature combinations, usually done through an exhaustive manual search. We have evaluated the MCLNN performance using the Ballroom and Homburg datasets of music genres. MCLNN has achieved accuracies that are competitive to state-of-the-art handcrafted attempts in addition to models based on Convolutional Neural Networks.