 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognition of Acoustic Events Using Masked Conditional Neural Networks
Paper and Code
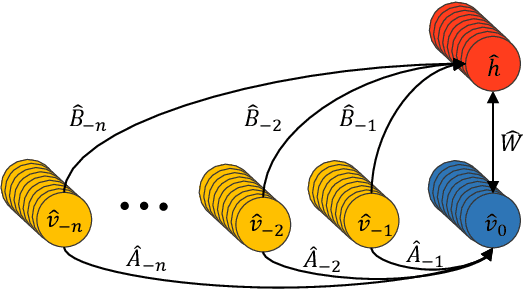
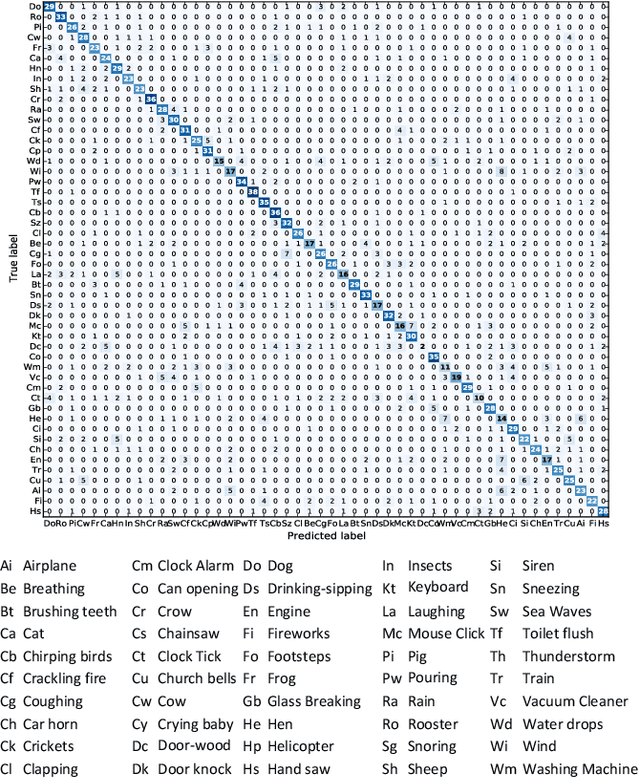


Automatic feature extraction using neural networks has accomplished remarkable success for images, but for sound recognition, these models are usually modified to fit the nature of the multi-dimensional temporal representation of the audio signal in spectrograms. This may not efficiently harness the time-frequency representation of the signal. The ConditionaL Neural Network (CLNN) takes into consideration the interrelation between the temporal frames, and the Masked ConditionaL Neural Network (MCLNN) extends upon the CLNN by forcing a systematic sparseness over the network's weights using a binary mask. The masking allows the network to learn about frequency bands rather than bins, mimicking a filterbank used in signal transformations such as MFCC. Additionally, the Mask is designed to consider various combinations of features, which automates the feature hand-crafting process. We applied the MCLNN for the Environmental Sound Recognition problem using the Urbansound8k, YorNoise, ESC-10 and ESC-50 datasets. The MCLNN have achieved competitive performance compared to state-of-the-art Convolutional Neural Networks and hand-crafted attempts.