 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning autoencoders for few-shot prediction
Jul 26, 2018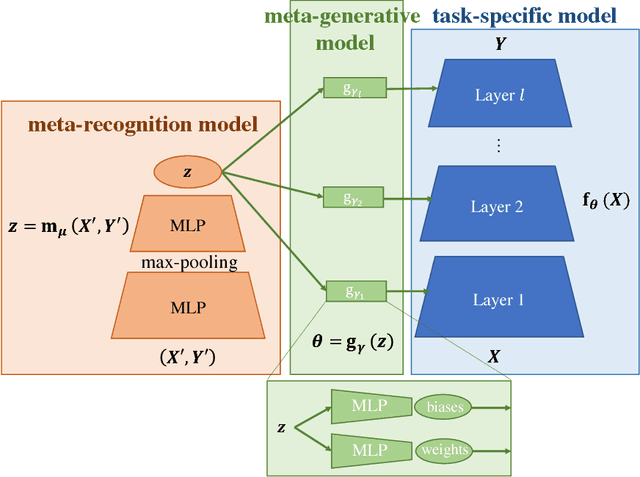

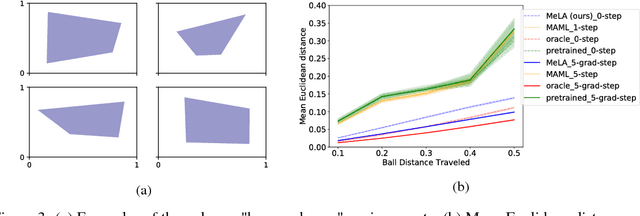

Compared to humans, machine learning models generally require significantly more training examples and fail to extrapolate from experience to solve previously unseen challenges. To help close this performance gap, we augment single-task neural networks with a meta-recognition model which learns a succinct model code via its autoencoder structure, using just a few informative examples. The model code is then employed by a meta-generative model to construct parameters for the task-specific model. We demonstrate that for previously unseen tasks, without additional training, this Meta-Learning Autoencoder (MeLA) framework can build models that closely match the true underlying models, with loss significantly lower than given by fine-tuned baseline networks, and performance that compares favorably with state-of-the-art meta-learning algorithms. MeLA also adds the ability to identify influential training examples and predict which additional data will be most valuable to acquire to improve model prediction.
Gated Orthogonal Recurrent Units: On Learning to Forget
Oct 25, 2017We present a novel recurrent neural network (RNN) based model that combines the remembering ability of unitary RNNs with the ability of gated RNNs to effectively forget redundant/irrelevant information in its memory. We achieve this by extending unitary RNNs with a gating mechanism. Our model is able to outperform LSTMs, GRUs and Unitary RNNs on several long-term dependency benchmark tasks. We empirically both show the orthogonal/unitary RNNs lack the ability to forget and also the ability of GORU to simultaneously remember long term dependencies while forgetting irrelevant information. This plays an important role in recurrent neural networks. We provide competitive results along with an analysis of our model on many natural sequential tasks including the bAbI Question Answering, TIMIT speech spectrum prediction, Penn TreeBank, and synthetic tasks that involve long-term dependencies such as algorithmic, parenthesis, denoising and copying tasks.
Tunable Efficient Unitary Neural Networks (EUNN) and their application to RNNs
Apr 03, 2017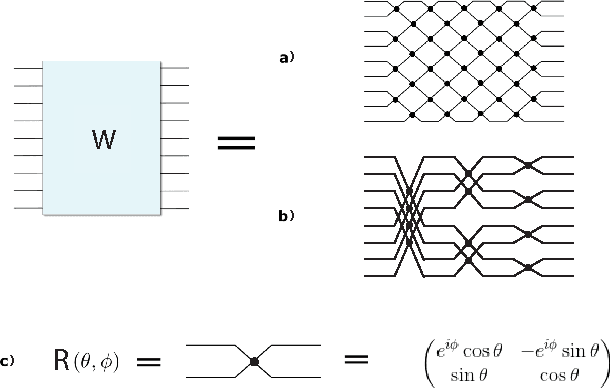
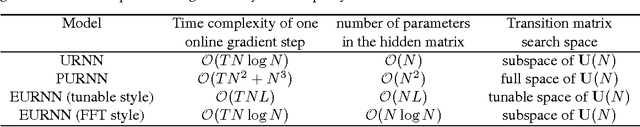
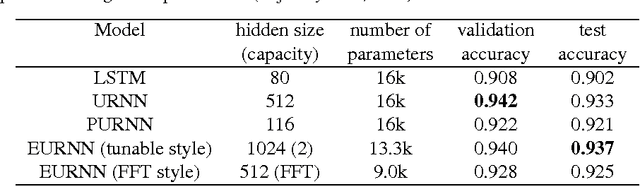
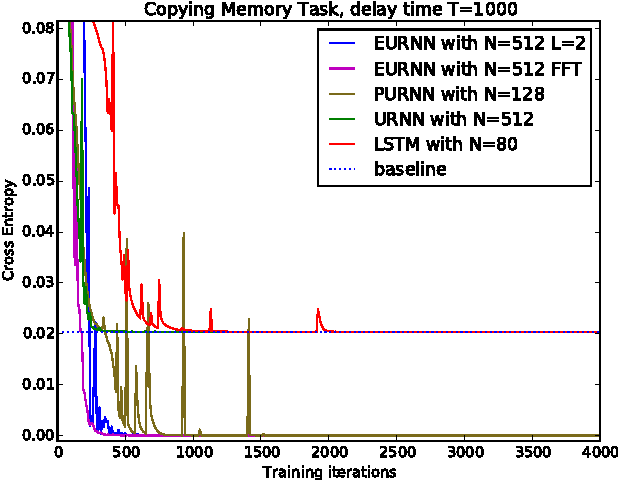
Using unitary (instead of general) matrices in artificial neural networks (ANNs) is a promising way to solve the gradient explosion/vanishing problem, as well as to enable ANNs to learn long-term correlations in the data. This approach appears particularly promising for Recurrent Neural Networks (RNNs). In this work, we present a new architecture for implementing an Efficient Unitary Neural Network (EUNNs); its main advantages can be summarized as follows. Firstly, the representation capacity of the unitary space in an EUNN is fully tunable, ranging from a subspace of SU(N) to the entire unitary space. Secondly, the computational complexity for training an EUNN is merely $\mathcal{O}(1)$ per parameter. Finally, we test the performance of EUNNs on the standard copying task, the pixel-permuted MNIST digit recognition benchmark as well as the Speech Prediction Test (TIMIT). We find that our architecture significantly outperforms both other state-of-the-art unitary RNNs and the LSTM architecture, in terms of the final performance and/or the wall-clock training speed. EUNNs are thus promising alternatives to RNNs and LSTMs for a wide variety of applications.