 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy People Skip Music? On Predicting Music Skips using Deep Reinforcement Learning
Jan 10, 2023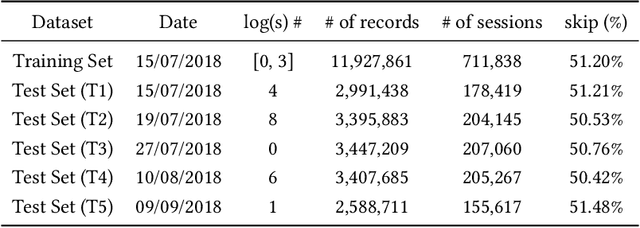
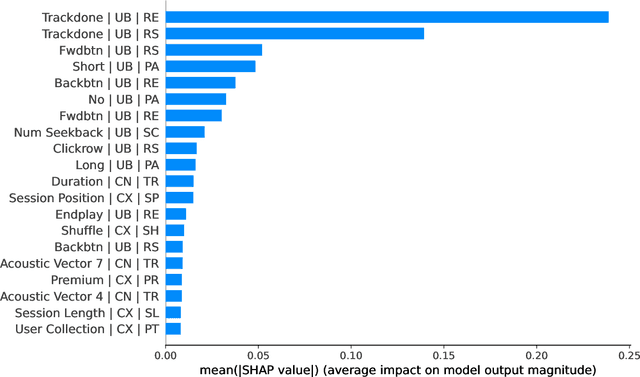
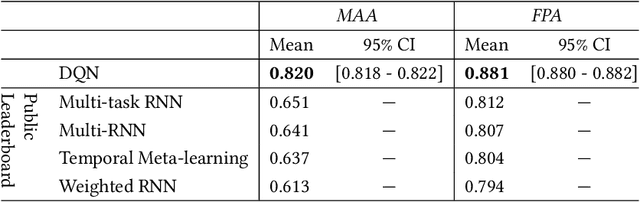
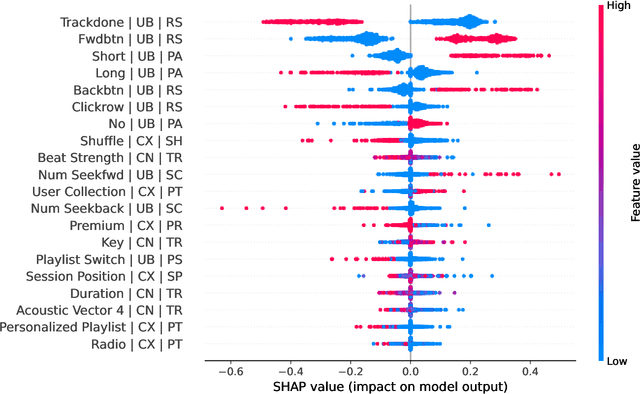
Music recommender systems are an integral part of our daily life. Recent research has seen a significant effort around black-box recommender based approaches such as Deep Reinforcement Learning (DRL). These advances have led, together with the increasing concerns around users' data collection and privacy, to a strong interest in building responsible recommender systems. A key element of a successful music recommender system is modelling how users interact with streamed content. By first understanding these interactions, insights can be drawn to enable the construction of more transparent and responsible systems. An example of these interactions is skipping behaviour, a signal that can measure users' satisfaction, dissatisfaction, or lack of interest. In this paper, we study the utility of users' historical data for the task of sequentially predicting users' skipping behaviour. To this end, we adapt DRL for this classification task, followed by a post-hoc explainability (SHAP) and ablation analysis of the input state representation. Experimental results from a real-world music streaming dataset (Spotify) demonstrate the effectiveness of our approach in this task by outperforming state-of-the-art models. A comprehensive analysis of our approach and of users' historical data reveals a temporal data leakage problem in the dataset. Our findings indicate that, overall, users' behaviour features are the most discriminative in how our proposed DRL model predicts music skips. Content and contextual features have a lesser effect. This suggests that a limited amount of user data should be collected and leveraged to predict skipping behaviour.
Ensemble Decision Systems for General Video Game Playing
May 26, 2019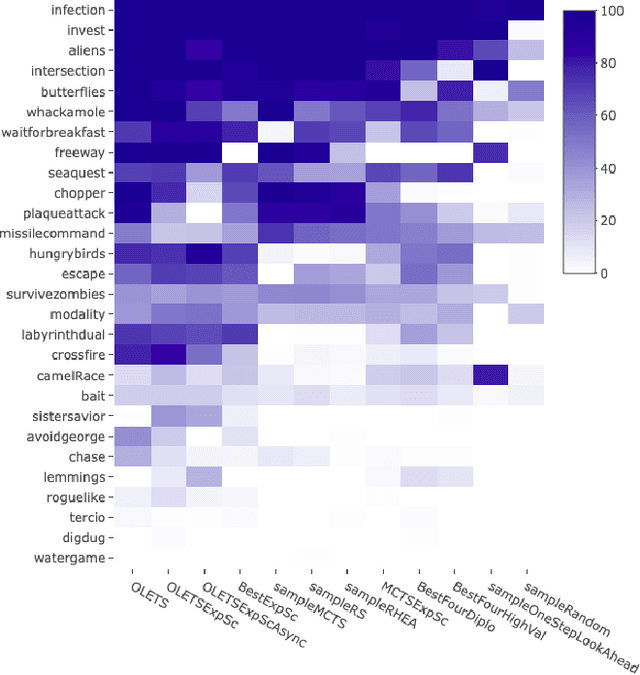
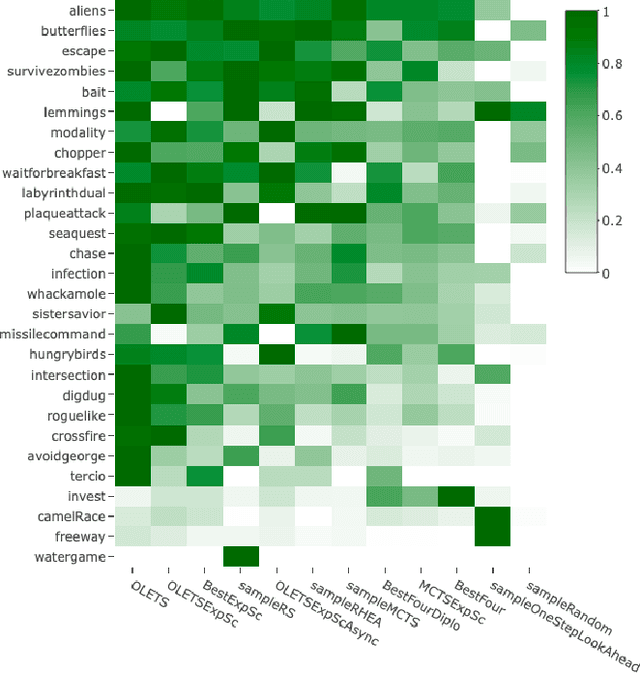
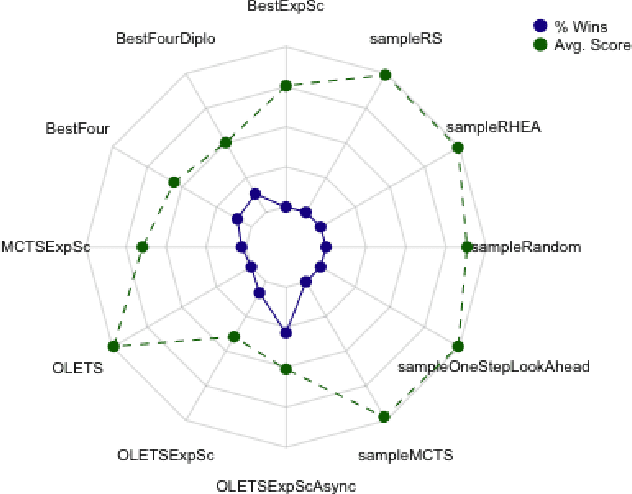
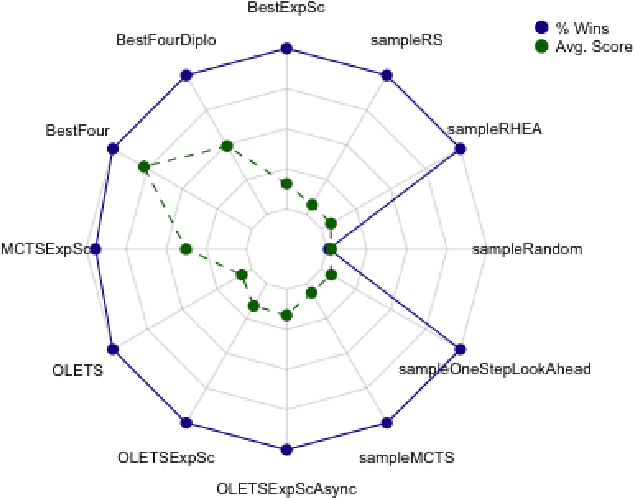
Ensemble Decision Systems offer a unique form of decision making that allows a collection of algorithms to reason together about a problem. Each individual algorithm has its own inherent strengths and weaknesses, and often it is difficult to overcome the weaknesses while retaining the strengths. Instead of altering the properties of the algorithm, the Ensemble Decision System augments the performance with other algorithms that have complementing strengths. This work outlines different options for building an Ensemble Decision System as well as providing analysis on its performance compared to the individual components of the system with interesting results, showing an increase in the generality of the algorithms without significantly impeding performance.
Solving zero-sum extensive-form games with arbitrary payoff uncertainty models
Apr 24, 2019Modeling strategic conflict from a game theoretical perspective involves dealing with epistemic uncertainty. Payoff uncertainty models are typically restricted to simple probability models due to computational restrictions. Recent breakthroughs Artificial Intelligence (AI) research applied to Poker have resulted in novel approximation approaches such as counterfactual regret minimization, that can successfully deal with large-scale imperfect games. By drawing from these ideas, this work addresses the problem of arbitrary continuous payoff distributions. We propose a method, Harsanyi-Counterfactual Regret Minimization, to solve two-player zero-sum extensive-form games with arbitrary payoff distribution models. Given a game $\Gamma$, using a Harsanyi transformation we generate a new game $\Gamma^\#$ to which we later apply Counterfactual Regret Minimization to obtain $\varepsilon$-Nash equilibria. We include numerical experiments showing how the method can be applied to a previously published problem.
Seq2Seq Mimic Games: A Signaling Perspective
Nov 15, 2018

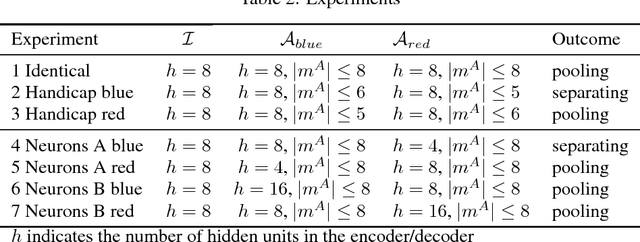
We study the emergence of communication in multiagent adversarial settings inspired by the classic Imitation game. A class of three player games is used to explore how agents based on sequence to sequence (Seq2Seq) models can learn to communicate information in adversarial settings. We propose a modeling approach, an initial set of experiments and use signaling theory to support our analysis. In addition, we describe how we operationalize the learning process of actor-critic Seq2Seq based agents in these communicational games.
A Continuous Information Gain Measure to Find the Most Discriminatory Problems for AI Benchmarking
Sep 11, 2018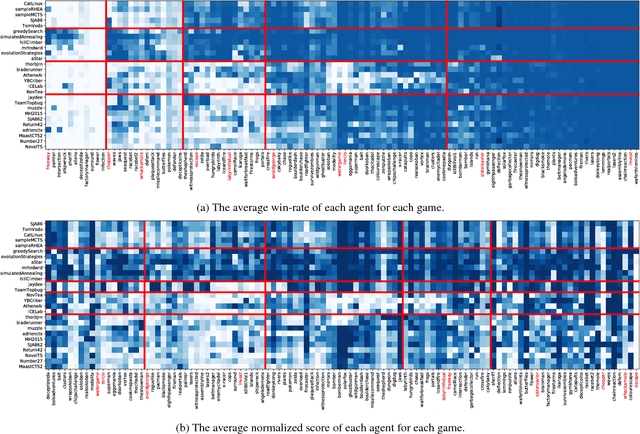

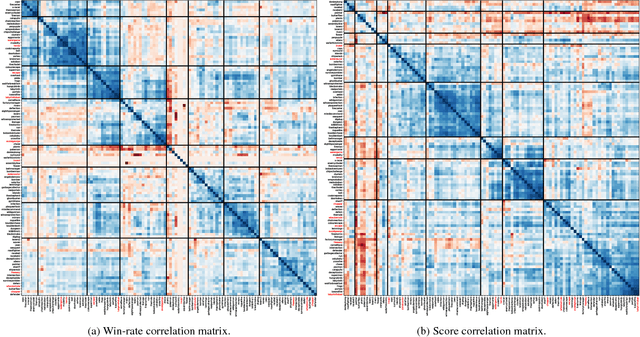
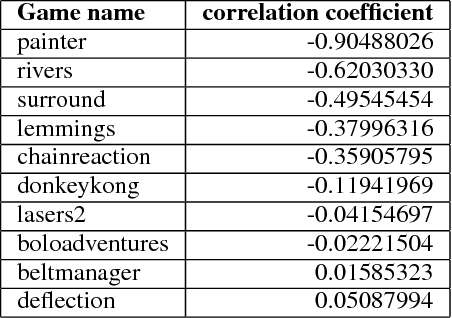
This paper introduces an information-theoretic method for selecting a small subset of problems which gives us the most information about a group of problem-solving algorithms. This method was tested on the games in the General Video Game AI (GVGAI) framework, allowing us to identify a smaller set of games that still gives a large amount of information about the game-playing agents. This approach can be used to make agent testing more efficient in the future. We can achieve almost as good discriminatory accuracy when testing on only a handful of games as when testing on more than a hundred games, something which is often computationally infeasible. Furthermore, this method can be extended to study the dimensions of effective variance in game design between these games, allowing us to identify which games differentiate between agents in the most complementary ways. As a side effect of this investigation, we provide an up-to-date comparison on agent performance for all GVGAI games, and an analysis of correlations between scores and win-rates across both games and agents.
Deceptive Games
Feb 04, 2018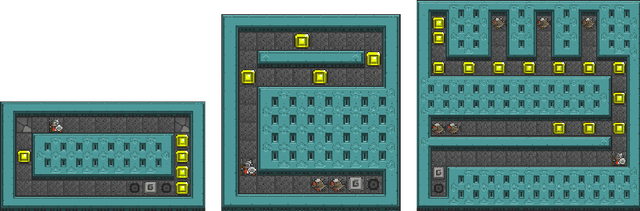


Deceptive games are games where the reward structure or other aspects of the game are designed to lead the agent away from a globally optimal policy. While many games are already deceptive to some extent, we designed a series of games in the Video Game Description Language (VGDL) implementing specific types of deception, classified by the cognitive biases they exploit. VGDL games can be run in the General Video Game Artificial Intelligence (GVGAI) Framework, making it possible to test a variety of existing AI agents that have been submitted to the GVGAI Competition on these deceptive games. Our results show that all tested agents are vulnerable to several kinds of deception, but that different agents have different weaknesses. This suggests that we can use deception to understand the capabilities of a game-playing algorithm, and game-playing algorithms to characterize the deception displayed by a game.
Ensemble Framework for Real-time Decision Making
Jun 21, 2017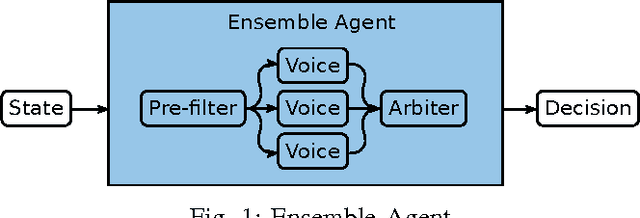

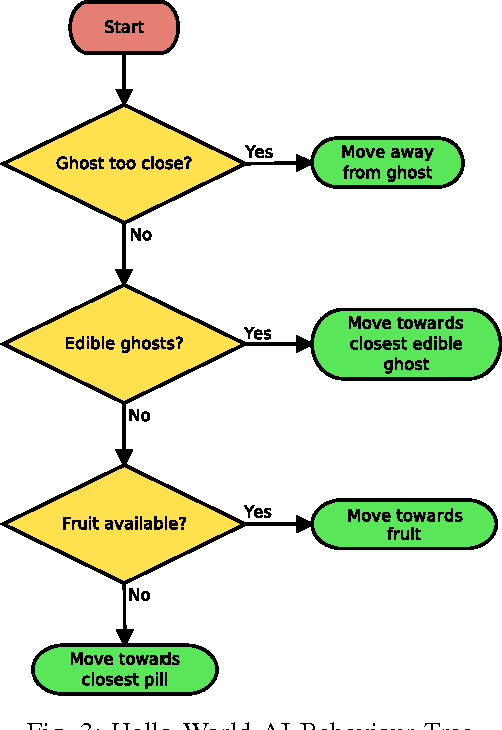
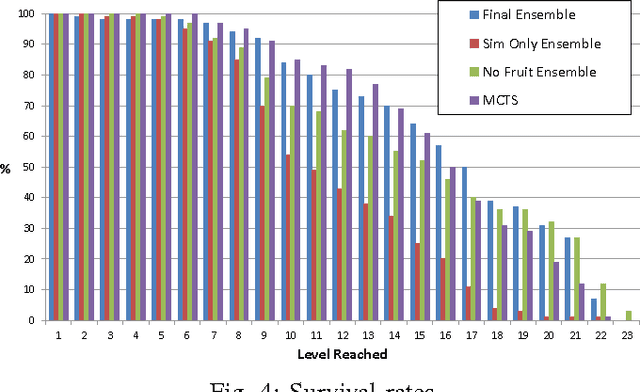
This paper introduces a new framework for real-time decision making in video games. An Ensemble agent is a compound agent composed of multiple agents, each with its own tasks or goals to achieve. Usually when dealing with real-time decision making, reactive agents are used; that is agents that return a decision based on the current state. While reactive agents are very fast, most games require more than just a rule-based agent to achieve good results. Deliberative agents---agents that use a forward model to search future states---are very useful in games with no hard time limit, such as Go or Backgammon, but generally take too long for real-time games. The Ensemble framework addresses this issue by allowing the agent to be both deliberative and reactive at the same time. This is achieved by breaking up the game-play into logical roles and having highly focused components for each role, with each component disregarding anything outwith its own role. Reactive agents can be used where a reactive agent is suited to the role, and where a deliberative approach is required, branching is kept to a minimum by the removal of all extraneous factors, enabling an informed decision to be made within a much smaller time-frame. An Arbiter is used to combine the component results, allowing high performing agents to be created from simple, efficient components.
Automatic Generation of Technical Documentation
Nov 30, 1994Natural-language generation (NLG) techniques can be used to automatically produce technical documentation from a domain knowledge base and linguistic and contextual models. We discuss this application of NLG technology from both a technical and a usefulness (costs and benefits) perspective. This discussion is based largely on our experiences with the IDAS documentation-generation project, and the reactions various interested people from industry have had to IDAS. We hope that this summary of our experiences with IDAS and the lessons we have learned from it will be beneficial for other researchers who wish to build technical-documentation generation systems.