 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximative Algorithms for Multi-Marginal Optimal Transport and Free-Support Wasserstein Barycenters
Feb 02, 2022
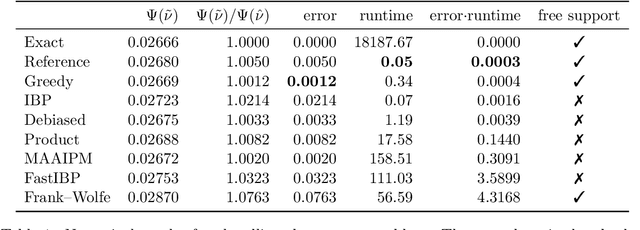
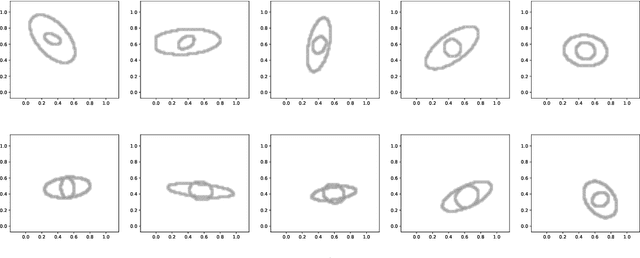
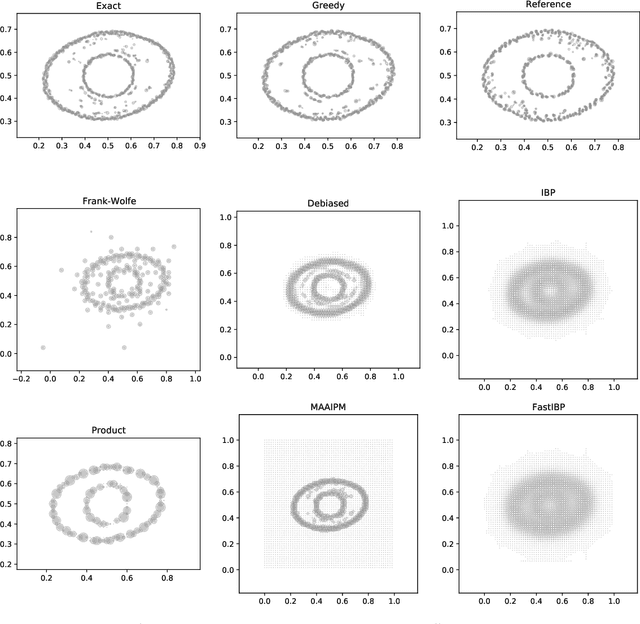
Computationally solving multi-marginal optimal transport (MOT) with squared Euclidean costs for $N$ discrete probability measures has recently attracted considerable attention, in part because of the correspondence of its solutions with Wasserstein-$2$ barycenters, which have many applications in data science. In general, this problem is NP-hard, calling for practical approximative algorithms. While entropic regularization has been successfully applied to approximate Wasserstein barycenters, this loses the sparsity of the optimal solution, making it difficult to solve the MOT problem directly in practice because of the curse of dimensionality. Thus, for obtaining barycenters, one usually resorts to fixed-support restrictions to a grid, which is, however, prohibitive in higher ambient dimensions $d$. In this paper, after analyzing the relationship between MOT and barycenters, we present two algorithms to approximate the solution of MOT directly, requiring mainly just $N-1$ standard two-marginal OT computations. Thus, they are fast, memory-efficient and easy to implement and can be used with any sparse OT solver as a black box. Moreover, they produce sparse solutions and show promising numerical results. We analyze these algorithms theoretically, proving upper and lower bounds for the relative approximation error.
The Oracle of DLphi
Jan 27, 2019We present a novel technique based on deep learning and set theory which yields exceptional classification and prediction results. Having access to a sufficiently large amount of labelled training data, our methodology is capable of predicting the labels of the test data almost always even if the training data is entirely unrelated to the test data. In other words, we prove in a specific setting that as long as one has access to enough data points, the quality of the data is irrelevant.
On Hyperparameter Search in Cluster Ensembles
Mar 29, 2018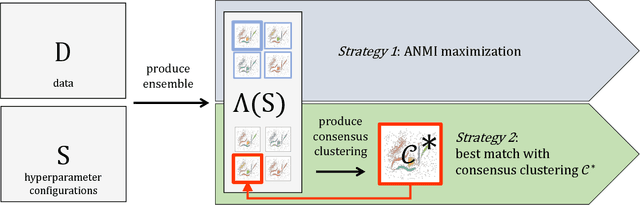
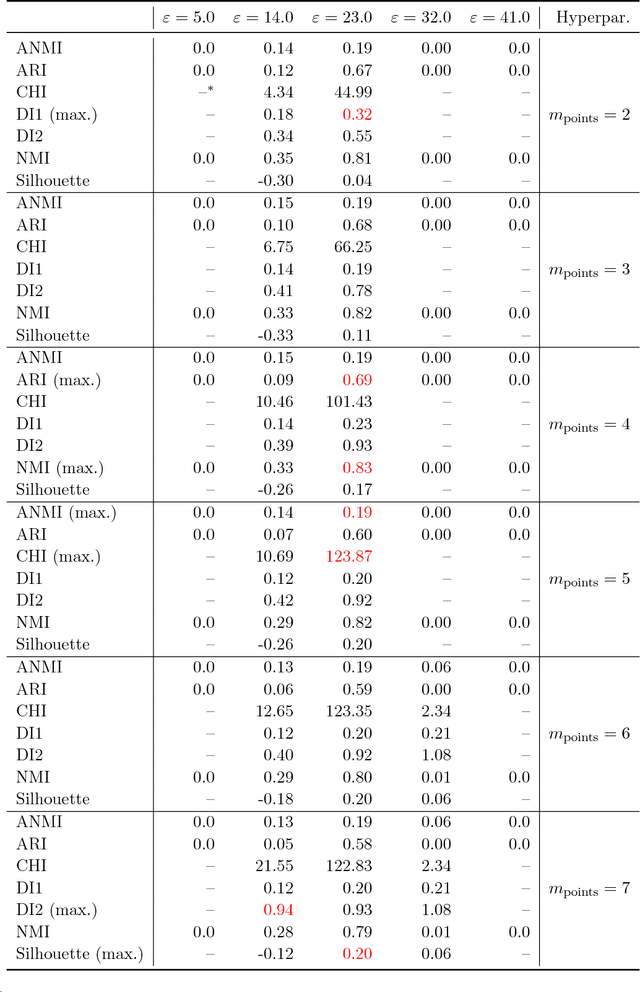

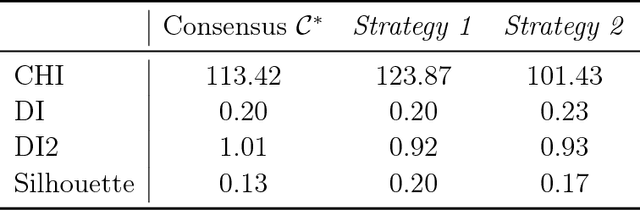
Quality assessments of models in unsupervised learning and clustering verification in particular have been a long-standing problem in the machine learning research. The lack of robust and universally applicable cluster validity scores often makes the algorithm selection and hyperparameter evaluation a tough guess. In this paper, we show that cluster ensemble aggregation techniques such as consensus clustering may be used to evaluate clusterings and their hyperparameter configurations. We use normalized mutual information to compare individual objects of a clustering ensemble to the constructed consensus of the whole ensemble and show, that the resulting score can serve as an overall quality measure for clustering problems. This method is capable of highlighting the standout clustering and hyperparameter configuration in the ensemble even in the case of a distorted consensus. We apply this very general framework to various data sets and give possible directions for future research.