 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Complexity Measurement as a Noisy Zero-Shot Proxy for Evaluating LLM Performance
Feb 17, 2025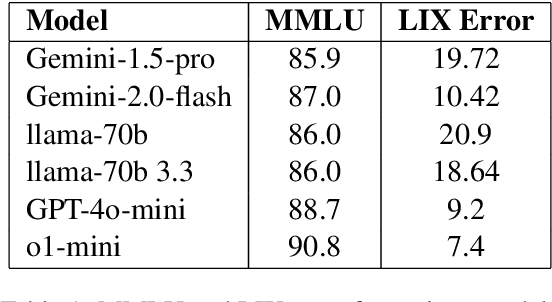
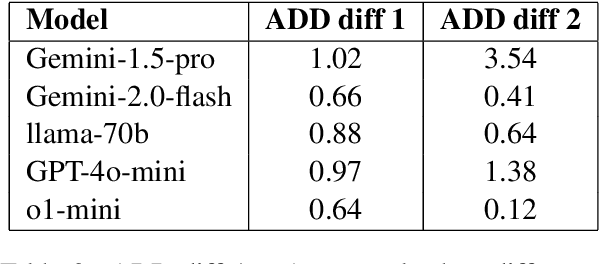
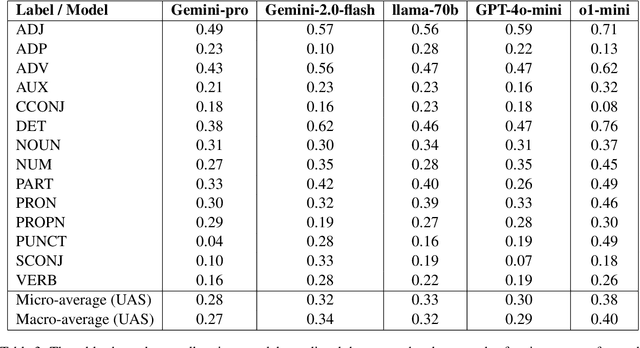
Large Language Models (LLMs) have made significant strides in natural language generation but often face challenges in tasks requiring precise calculations and structural analysis. This paper investigates the performance of state-of-the-art LLMs on language complexity measurement tasks, through the computation of the LIX readability metric and Average Dependency Distance (ADD). Using Swedish high school and university-level essays, we evaluate the models' abilities to compute LIX scores and perform dependency parsing, comparing their results to established ground truths. Our findings reveal that while all models demonstrate some capacity for these tasks, ChatGPT-o1-mini performs most consistently, achieving the highest accuracy in both LIX computation and dependency parsing. Additionally, we observe a strong significant correlation -0.875 p 0.026 (N=6) between the models' accuracy in computing LIX and their overall performance on the Massive Multitask Language Understanding (MMLU) benchmark. These results suggest that language complexity measurement abilities can serve as a noisy zero-shot proxies for assessing the general capabilities of LLMs, providing a practical method for model evaluation without the need for extensive benchmarking datasets.
Large Language Models and Mathematical Reasoning Failures
Feb 17, 2025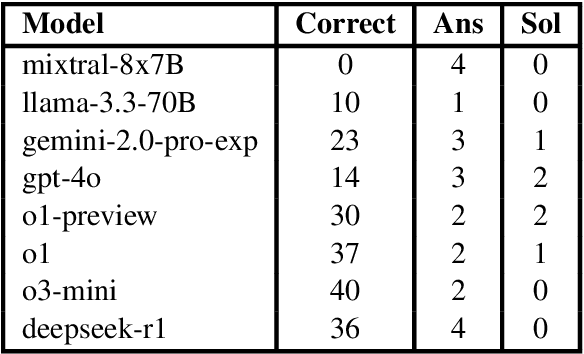
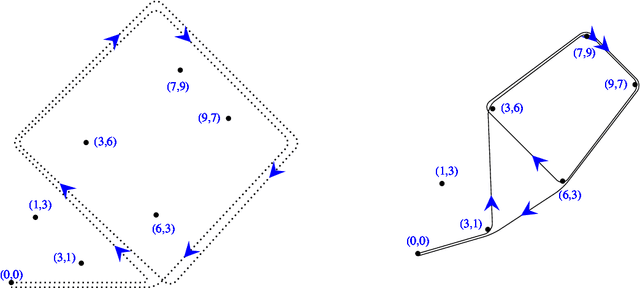
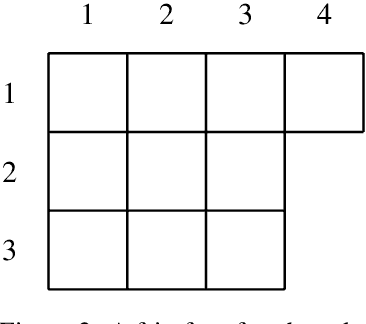
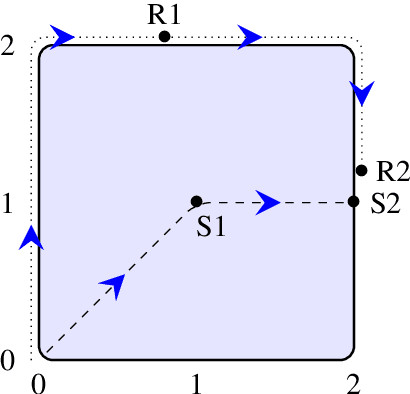
This paper investigates the mathematical reasoning capabilities of large language models (LLMs) using 50 newly constructed high-school-level word problems. Unlike prior studies that focus solely on answer correctness, we rigorously analyze both final answers and solution steps to identify reasoning failures. Evaluating eight state-of-the-art models - including Mixtral, Llama, Gemini, GPT-4o, and OpenAI's o1 variants - we find that while newer models (e.g., o3-mini, deepseek-r1) achieve higher accuracy, all models exhibit errors in spatial reasoning, strategic planning, and arithmetic, sometimes producing correct answers through flawed logic. Common failure modes include unwarranted assumptions, over-reliance on numerical patterns, and difficulty translating physical intuition into mathematical steps. Manual analysis reveals that models struggle with problems requiring multi-step deduction or real-world knowledge, despite possessing broad mathematical knowledge. Our results underscore the importance of evaluating reasoning processes, not just answers, and caution against overestimating LLMs' problem-solving proficiency. The study highlights persistent gaps in LLMs' generalization abilities, emphasizing the need for targeted improvements in structured reasoning and constraint handling.
EMBRACE: Evaluation and Modifications for Boosting RACE
May 15, 2023
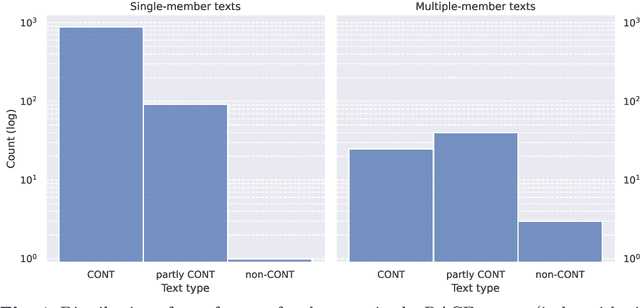


When training and evaluating machine reading comprehension models, it is very important to work with high-quality datasets that are also representative of real-world reading comprehension tasks. This requirement includes, for instance, having questions that are based on texts of different genres and require generating inferences or reflecting on the reading material. In this article we turn our attention to RACE, a dataset of English texts and corresponding multiple-choice questions (MCQs). Each MCQ consists of a question and four alternatives (of which one is the correct answer). RACE was constructed by Chinese teachers of English for human reading comprehension and is widely used as training material for machine reading comprehension models. By construction, RACE should satisfy the aforementioned quality requirements and the purpose of this article is to check whether they are indeed satisfied. We provide a detailed analysis of the test set of RACE for high-school students (1045 texts and 3498 corresponding MCQs) including (1) an evaluation of the difficulty of each MCQ and (2) annotations for the relevant pieces of the texts (called "bases") that are used to justify the plausibility of each alternative. A considerable number of MCQs appear not to fulfill basic requirements for this type of reading comprehension tasks, so we additionally identify the high-quality subset of the evaluated RACE corpus. We also demonstrate that the distribution of the positions of the bases for the alternatives is biased towards certain parts of texts, which is not necessarily desirable when evaluating MCQ answering and generation models.
SweCTRL-Mini: a data-transparent Transformer-based large language model for controllable text generation in Swedish
May 13, 2023



We present SweCTRL-Mini, a large Swedish language model that can be used for inference and fine-tuning on a single consumer-grade GPU. The model is based on the CTRL architecture by Keskar, McCann, Varshney, Xiong, and Socher (2019), which means that users of the SweCTRL-Mini model can control the genre of the generated text by inserting special tokens in the generation prompts. SweCTRL-Mini is trained on a subset of the Swedish part of the mC4 corpus and a set of Swedish novels. In this article, we provide (1) a detailed account of the utilized training data and text pre-processing steps, to the extent that it is possible to check whether a specific phrase/source was a part of the training data, and (2) an evaluation of the model on both discriminative tasks, using automatic evaluation methods, and generative tasks, using human referees. We also compare the generative capabilities of the model with those of GPT-3. SweCTRL-Mini is fully open and available for download.
Automatically generating question-answer pairs for assessing basic reading comprehension in Swedish
Nov 28, 2022

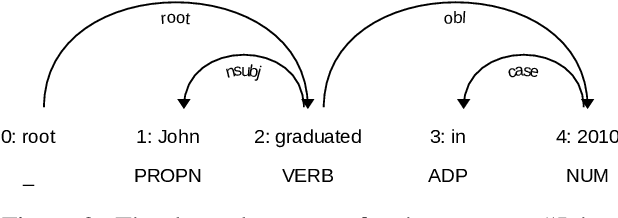
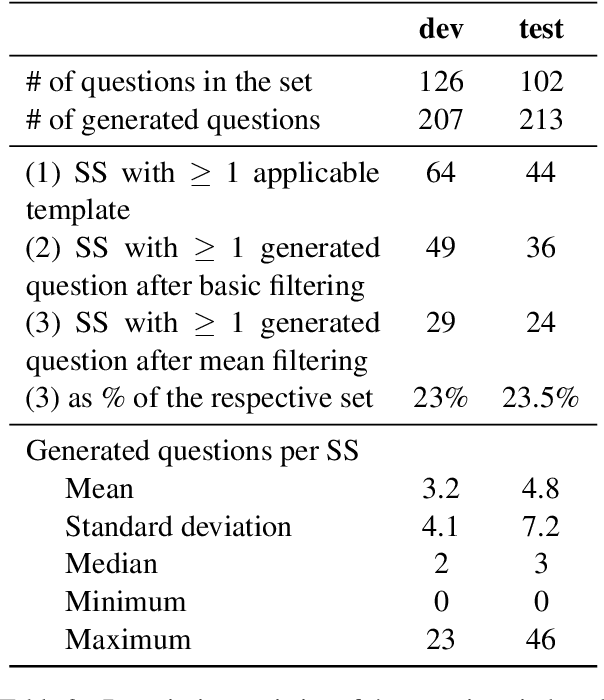
This paper presents an evaluation of the quality of automatically generated reading comprehension questions from Swedish text, using the Quinductor method. This method is a light-weight, data-driven but non-neural method for automatic question generation (QG). The evaluation shows that Quinductor is a viable QG method that can provide a strong baseline for neural-network-based QG methods.
Minor changes make a difference: a case study on the consistency of UD-based dependency parsers
Nov 30, 2021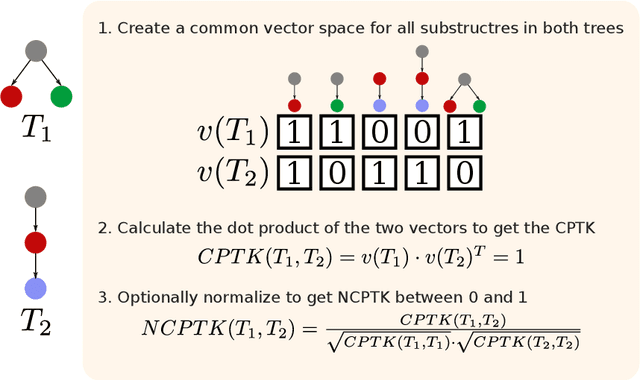
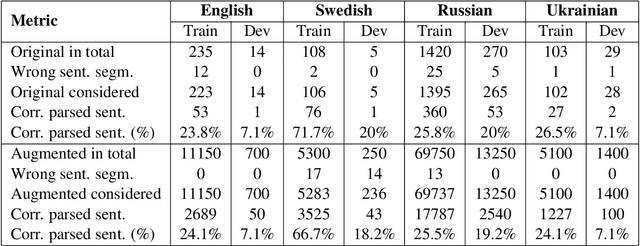
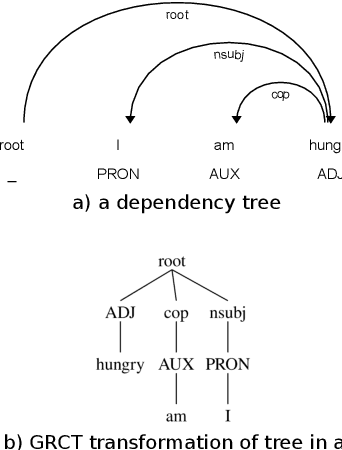
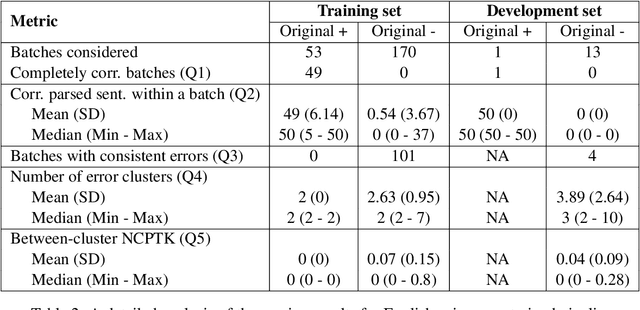
Many downstream applications are using dependency trees, and are thus relying on dependency parsers producing correct, or at least consistent, output. However, dependency parsers are trained using machine learning, and are therefore susceptible to unwanted inconsistencies due to biases in the training data. This paper explores the effects of such biases in four languages - English, Swedish, Russian, and Ukrainian - though an experiment where we study the effect of replacing numerals in sentences. We show that such seemingly insignificant changes in the input can cause large differences in the output, and suggest that data augmentation can remedy the problems.
BERT-based distractor generation for Swedish reading comprehension questions using a small-scale dataset
Aug 09, 2021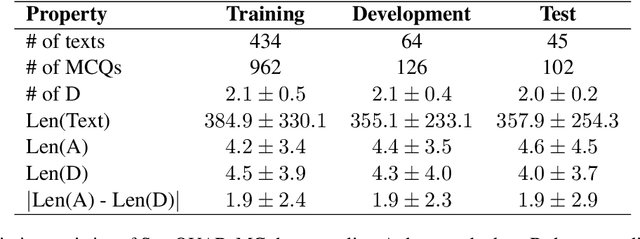
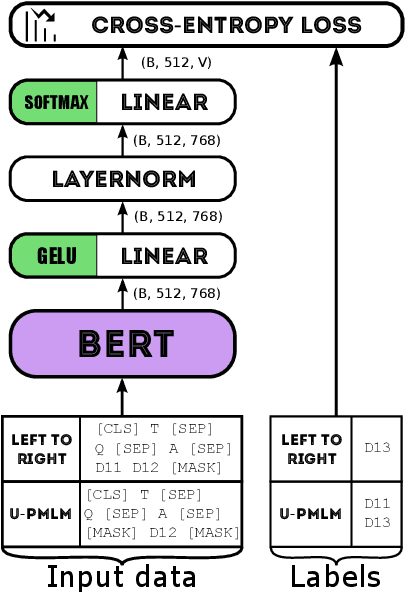

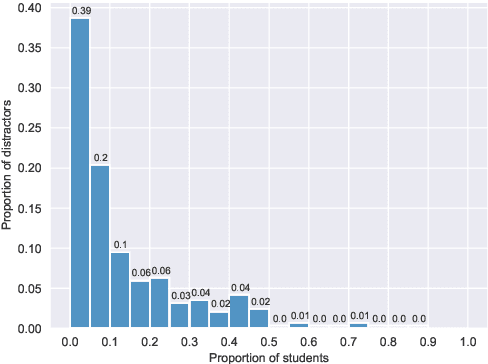
An important part when constructing multiple-choice questions (MCQs) for reading comprehension assessment are the distractors, the incorrect but preferably plausible answer options. In this paper, we present a new BERT-based method for automatically generating distractors using only a small-scale dataset. We also release a new such dataset of Swedish MCQs (used for training the model), and propose a methodology for assessing the generated distractors. Evaluation shows that from a student's perspective, our method generated one or more plausible distractors for more than 50% of the MCQs in our test set. From a teacher's perspective, about 50% of the generated distractors were deemed appropriate. We also do a thorough analysis of the results.
Quinductor: a multilingual data-driven method for generating reading-comprehension questions using Universal Dependencies
Mar 18, 2021

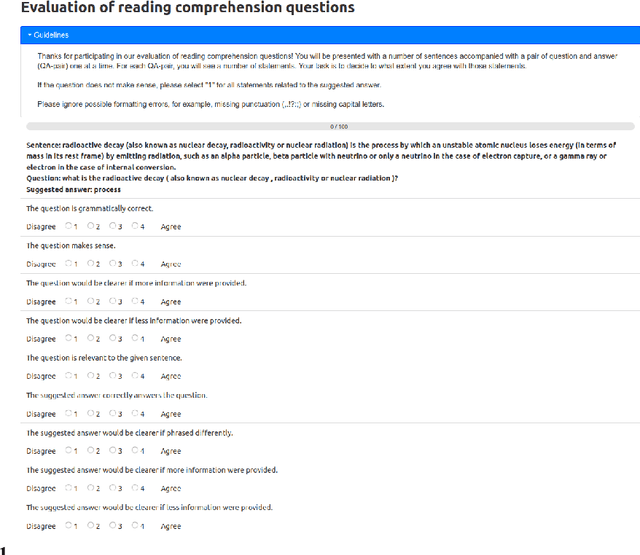
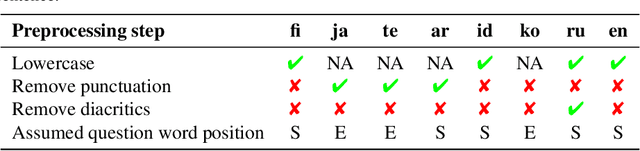
We propose a multilingual data-driven method for generating reading comprehension questions using dependency trees. Our method provides a strong, mostly deterministic, and inexpensive-to-train baseline for less-resourced languages. While a language-specific corpus is still required, its size is nowhere near those required by modern neural question generation (QG) architectures. Our method surpasses QG baselines previously reported in the literature and shows a good performance in terms of human evaluation.