 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models and Mathematical Reasoning Failures
Paper and Code
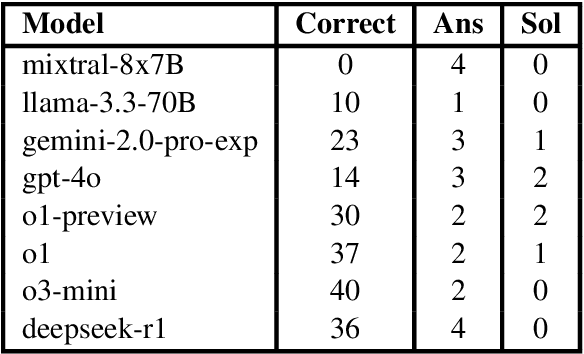
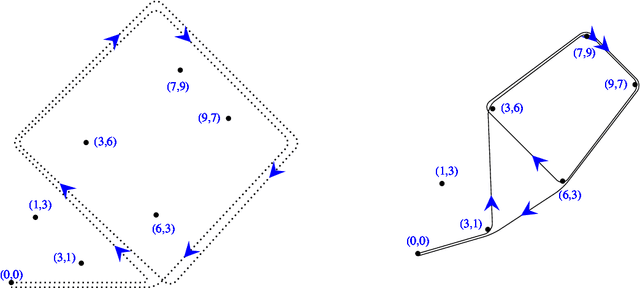
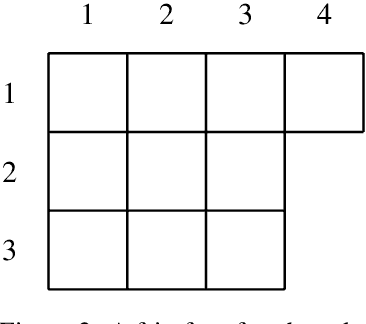
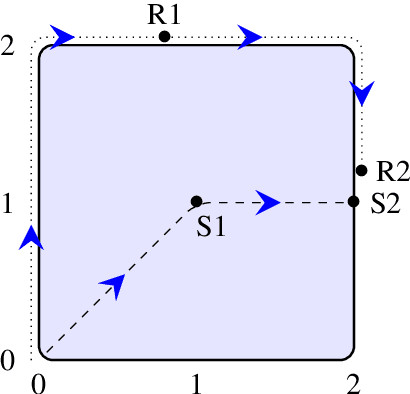
This paper investigates the mathematical reasoning capabilities of large language models (LLMs) using 50 newly constructed high-school-level word problems. Unlike prior studies that focus solely on answer correctness, we rigorously analyze both final answers and solution steps to identify reasoning failures. Evaluating eight state-of-the-art models - including Mixtral, Llama, Gemini, GPT-4o, and OpenAI's o1 variants - we find that while newer models (e.g., o3-mini, deepseek-r1) achieve higher accuracy, all models exhibit errors in spatial reasoning, strategic planning, and arithmetic, sometimes producing correct answers through flawed logic. Common failure modes include unwarranted assumptions, over-reliance on numerical patterns, and difficulty translating physical intuition into mathematical steps. Manual analysis reveals that models struggle with problems requiring multi-step deduction or real-world knowledge, despite possessing broad mathematical knowledge. Our results underscore the importance of evaluating reasoning processes, not just answers, and caution against overestimating LLMs' problem-solving proficiency. The study highlights persistent gaps in LLMs' generalization abilities, emphasizing the need for targeted improvements in structured reasoning and constraint handling.