 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Cloning for Dysarthric Speech Synthesis: Addressing Data Scarcity in Speech-Language Pathology
Mar 03, 2025This study explores voice cloning to generate synthetic speech replicating the unique patterns of individuals with dysarthria. Using the TORGO dataset, we address data scarcity and privacy challenges in speech-language pathology. Our contributions include demonstrating that voice cloning preserves dysarthric speech characteristics, analyzing differences between real and synthetic data, and discussing implications for diagnostics, rehabilitation, and communication. We cloned voices from dysarthric and control speakers using a commercial platform, ensuring gender-matched synthetic voices. A licensed speech-language pathologist (SLP) evaluated a subset for dysarthria, speaker gender, and synthetic indicators. The SLP correctly identified dysarthria in all cases and speaker gender in 95% but misclassified 30% of synthetic samples as real, indicating high realism. Our results suggest synthetic speech effectively captures disordered characteristics and that voice cloning has advanced to produce high-quality data resembling real speech, even to trained professionals. This has critical implications for healthcare, where synthetic data can mitigate data scarcity, protect privacy, and enhance AI-driven diagnostics. By enabling the creation of diverse, high-quality speech datasets, voice cloning can improve generalizable models, personalize therapy, and advance assistive technologies for dysarthria. We publicly release our synthetic dataset to foster further research and collaboration, aiming to develop robust models that improve patient outcomes in speech-language pathology.
Large Language Models and Mathematical Reasoning Failures
Feb 17, 2025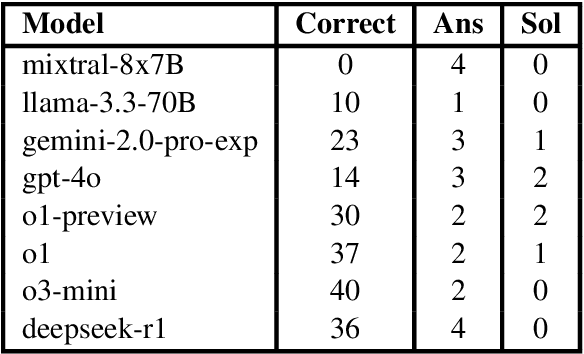
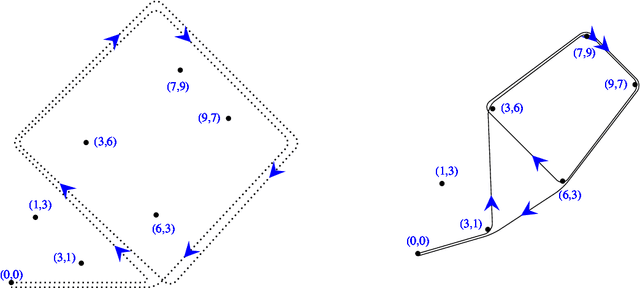
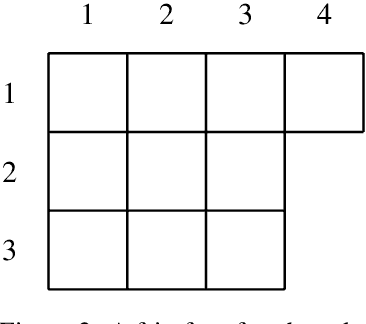
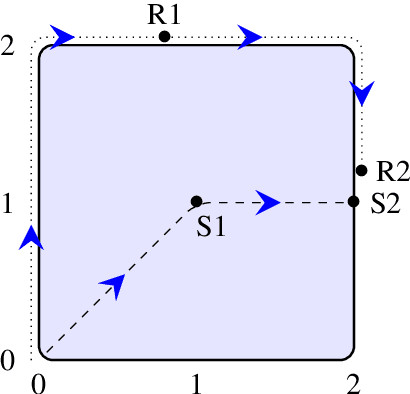
This paper investigates the mathematical reasoning capabilities of large language models (LLMs) using 50 newly constructed high-school-level word problems. Unlike prior studies that focus solely on answer correctness, we rigorously analyze both final answers and solution steps to identify reasoning failures. Evaluating eight state-of-the-art models - including Mixtral, Llama, Gemini, GPT-4o, and OpenAI's o1 variants - we find that while newer models (e.g., o3-mini, deepseek-r1) achieve higher accuracy, all models exhibit errors in spatial reasoning, strategic planning, and arithmetic, sometimes producing correct answers through flawed logic. Common failure modes include unwarranted assumptions, over-reliance on numerical patterns, and difficulty translating physical intuition into mathematical steps. Manual analysis reveals that models struggle with problems requiring multi-step deduction or real-world knowledge, despite possessing broad mathematical knowledge. Our results underscore the importance of evaluating reasoning processes, not just answers, and caution against overestimating LLMs' problem-solving proficiency. The study highlights persistent gaps in LLMs' generalization abilities, emphasizing the need for targeted improvements in structured reasoning and constraint handling.
Language Complexity Measurement as a Noisy Zero-Shot Proxy for Evaluating LLM Performance
Feb 17, 2025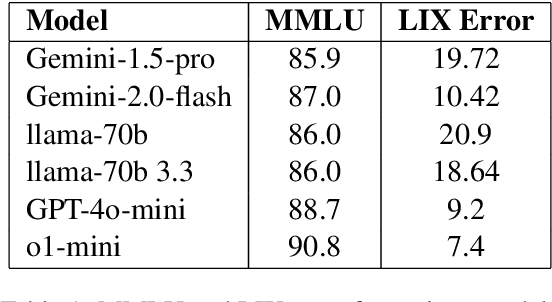
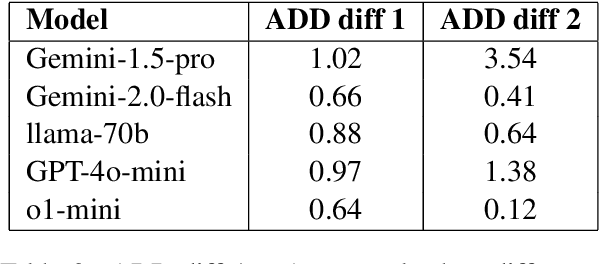
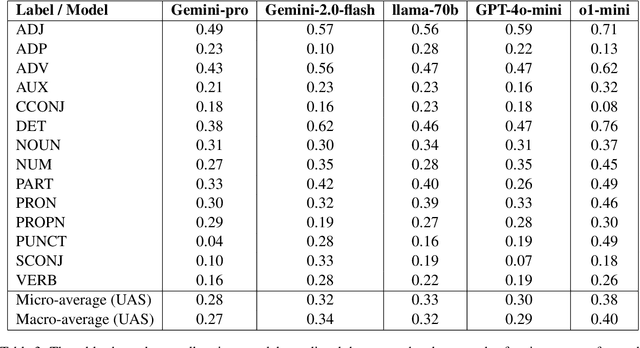
Large Language Models (LLMs) have made significant strides in natural language generation but often face challenges in tasks requiring precise calculations and structural analysis. This paper investigates the performance of state-of-the-art LLMs on language complexity measurement tasks, through the computation of the LIX readability metric and Average Dependency Distance (ADD). Using Swedish high school and university-level essays, we evaluate the models' abilities to compute LIX scores and perform dependency parsing, comparing their results to established ground truths. Our findings reveal that while all models demonstrate some capacity for these tasks, ChatGPT-o1-mini performs most consistently, achieving the highest accuracy in both LIX computation and dependency parsing. Additionally, we observe a strong significant correlation -0.875 p 0.026 (N=6) between the models' accuracy in computing LIX and their overall performance on the Massive Multitask Language Understanding (MMLU) benchmark. These results suggest that language complexity measurement abilities can serve as a noisy zero-shot proxies for assessing the general capabilities of LLMs, providing a practical method for model evaluation without the need for extensive benchmarking datasets.
You don't understand me!: Comparing ASR results for L1 and L2 speakers of Swedish
May 22, 2024The performance of Automatic Speech Recognition (ASR) systems has constantly increased in state-of-the-art development. However, performance tends to decrease considerably in more challenging conditions (e.g., background noise, multiple speaker social conversations) and with more atypical speakers (e.g., children, non-native speakers or people with speech disorders), which signifies that general improvements do not necessarily transfer to applications that rely on ASR, e.g., educational software for younger students or language learners. In this study, we focus on the gap in performance between recognition results for native and non-native, read and spontaneous, Swedish utterances transcribed by different ASR services. We compare the recognition results using Word Error Rate and analyze the linguistic factors that may generate the observed transcription errors.
Evaluating Large Language Models with Human Feedback: Establishing a Swedish Benchmark
May 22, 2024
In the rapidly evolving field of artificial intelligence, large language models (LLMs) have demonstrated significant capabilities across numerous applications. However, the performance of these models in languages with fewer resources, such as Swedish, remains under-explored. This study introduces a comprehensive human benchmark to assess the efficacy of prominent LLMs in understanding and generating Swedish language texts using forced choice ranking. We employ a modified version of the ChatbotArena benchmark, incorporating human feedback to evaluate eleven different models, including GPT-4, GPT-3.5, various Claude and Llama models, and bespoke models like Dolphin-2.9-llama3b-8b-flashback and BeagleCatMunin. These models were chosen based on their performance on LMSYS chatbot arena and the Scandeval benchmarks. We release the chatbotarena.se benchmark as a tool to improve our understanding of language model performance in Swedish with the hopes that it will be widely used. We aim to create a leaderboard once sufficient data has been collected and analysed.
Comparing the Efficacy of GPT-4 and Chat-GPT in Mental Health Care: A Blind Assessment of Large Language Models for Psychological Support
May 15, 2024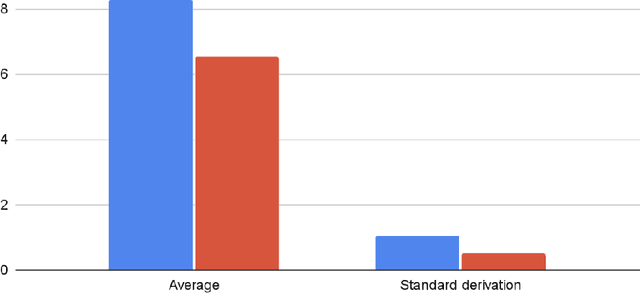



Background: Rapid advancements in natural language processing have led to the development of large language models with the potential to revolutionize mental health care. These models have shown promise in assisting clinicians and providing support to individuals experiencing various psychological challenges. Objective: This study aims to compare the performance of two large language models, GPT-4 and Chat-GPT, in responding to a set of 18 psychological prompts, to assess their potential applicability in mental health care settings. Methods: A blind methodology was employed, with a clinical psychologist evaluating the models' responses without knowledge of their origins. The prompts encompassed a diverse range of mental health topics, including depression, anxiety, and trauma, to ensure a comprehensive assessment. Results: The results demonstrated a significant difference in performance between the two models (p > 0.05). GPT-4 achieved an average rating of 8.29 out of 10, while Chat-GPT received an average rating of 6.52. The clinical psychologist's evaluation suggested that GPT-4 was more effective at generating clinically relevant and empathetic responses, thereby providing better support and guidance to potential users. Conclusions: This study contributes to the growing body of literature on the applicability of large language models in mental health care settings. The findings underscore the importance of continued research and development in the field to optimize these models for clinical use. Further investigation is necessary to understand the specific factors underlying the performance differences between the two models and to explore their generalizability across various populations and mental health conditions.
A Framework for Integrating Gesture Generation Models into Interactive Conversational Agents
Feb 24, 2021Embodied conversational agents (ECAs) benefit from non-verbal behavior for natural and efficient interaction with users. Gesticulation - hand and arm movements accompanying speech - is an essential part of non-verbal behavior. Gesture generation models have been developed for several decades: starting with rule-based and ending with mainly data-driven methods. To date, recent end-to-end gesture generation methods have not been evaluated in a real-time interaction with users. We present a proof-of-concept framework, which is intended to facilitate evaluation of modern gesture generation models in interaction. We demonstrate an extensible open-source framework that contains three components: 1) a 3D interactive agent; 2) a chatbot backend; 3) a gesticulating system. Each component can be replaced, making the proposed framework applicable for investigating the effect of different gesturing models in real-time interactions with different communication modalities, chatbot backends, or different agent appearances. The code and video are available at the project page https://nagyrajmund.github.io/project/gesturebot.