 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT-based distractor generation for Swedish reading comprehension questions using a small-scale dataset
Paper and Code
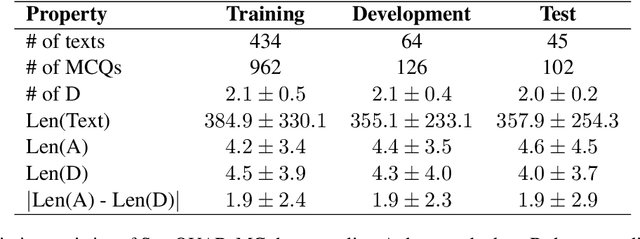
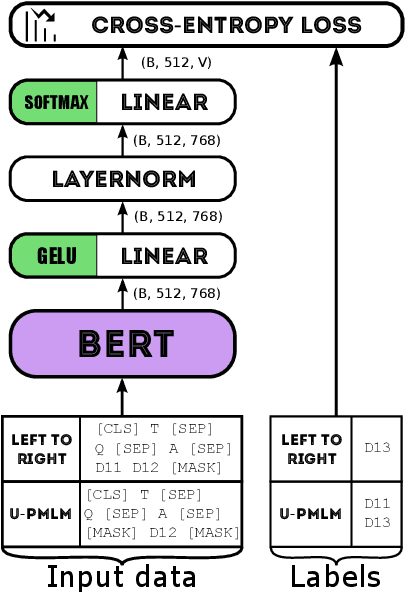

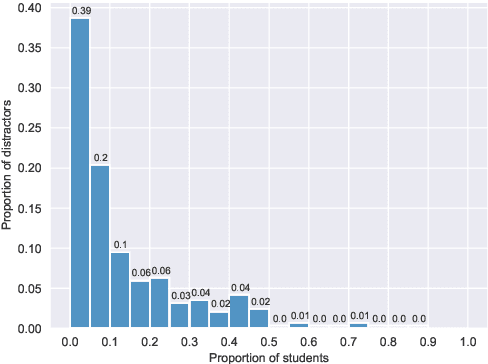
An important part when constructing multiple-choice questions (MCQs) for reading comprehension assessment are the distractors, the incorrect but preferably plausible answer options. In this paper, we present a new BERT-based method for automatically generating distractors using only a small-scale dataset. We also release a new such dataset of Swedish MCQs (used for training the model), and propose a methodology for assessing the generated distractors. Evaluation shows that from a student's perspective, our method generated one or more plausible distractors for more than 50% of the MCQs in our test set. From a teacher's perspective, about 50% of the generated distractors were deemed appropriate. We also do a thorough analysis of the results.