Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuinductor: a multilingual data-driven method for generating reading-comprehension questions using Universal Dependencies
Paper and Code


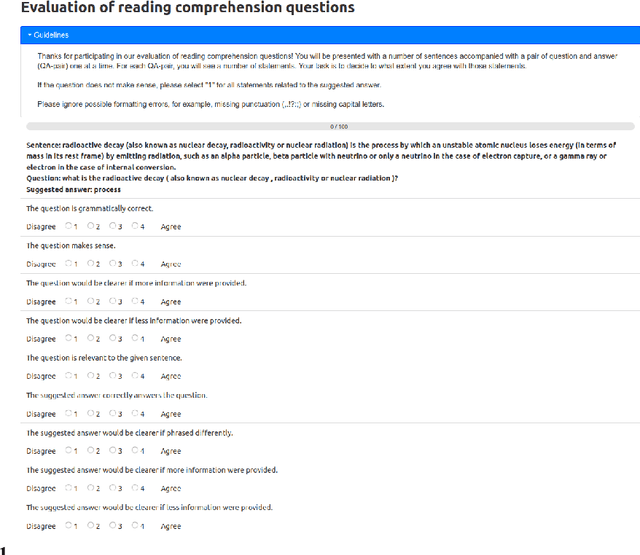
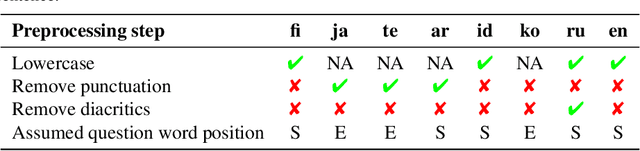
We propose a multilingual data-driven method for generating reading comprehension questions using dependency trees. Our method provides a strong, mostly deterministic, and inexpensive-to-train baseline for less-resourced languages. While a language-specific corpus is still required, its size is nowhere near those required by modern neural question generation (QG) architectures. Our method surpasses QG baselines previously reported in the literature and shows a good performance in terms of human evaluation.
View paper on