 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA1: A Fully Transparent Open-Source, Adaptive and Efficient Truncated Vision-Language-Action Model
Apr 07, 2026Vision--Language--Action (VLA) models have emerged as a powerful paradigm for open-world robot manipulation, but their practical deployment is often constrained by \emph{cost}: billion-scale VLM backbones and iterative diffusion/flow-based action heads incur high latency and compute, making real-time control expensive on commodity hardware. We present A1, a fully open-source and transparent VLA framework designed for low-cost, high-throughput inference without sacrificing manipulation success; Our approach leverages pretrained VLMs that provide implicit affordance priors for action generation. We release the full training stack (training code, data/data-processing pipeline, intermediate checkpoints, and evaluation scripts) to enable end-to-end reproducibility. Beyond optimizing the VLM alone, A1 targets the full inference pipeline by introducing a budget-aware adaptive inference scheme that jointly accelerates the backbone and the \emph{action head}. Specifically, we monitor action consistency across intermediate VLM layers to trigger early termination, and propose Inter-Layer Truncated Flow Matching that warm-starts denoising across layers, enabling accurate actions with substantially fewer effective denoising iterations. Across simulation benchmarks (LIBERO, VLABench) and real robots (Franka, AgiBot), A1 achieves state-of-the-art success rates while significantly reducing inference cost (e.g., up to 72% lower per-episode latency for flow-matching inference and up to 76.6% backbone computation reduction with minor performance degradation). On RoboChallenge, A1 achieves an average success rate of 29.00%, outperforming baselines including pi0(28.33%), X-VLA (21.33%), and RDT-1B (15.00%).
OneMall: One Architecture, More Scenarios -- End-to-End Generative Recommender Family at Kuaishou E-Commerce
Feb 02, 2026In the wave of generative recommendation, we present OneMall, an end-to-end generative recommendation framework tailored for e-commerce services at Kuaishou. Our OneMall systematically unifies the e-commerce's multiple item distribution scenarios, such as Product-card, short-video and live-streaming. Specifically, it comprises three key components, aligning the entire model training pipeline to the LLM's pre-training/post-training: (1) E-commerce Semantic Tokenizer: we provide a tokenizer solution that captures both real-world semantics and business-specific item relations across different scenarios; (2) Transformer-based Architecture: we largely utilize Transformer as our model backbone, e.g., employing Query-Former for long sequence compression, Cross-Attention for multi-behavior sequence fusion, and Sparse MoE for scalable auto-regressive generation; (3) Reinforcement Learning Pipeline: we further connect retrieval and ranking models via RL, enabling the ranking model to serve as a reward signal for end-to-end policy retrieval model optimization. Extensive experiments demonstrate that OneMall achieves consistent improvements across all e-commerce scenarios: +13.01\% GMV in product-card, +15.32\% Orders in Short-Video, and +2.78\% Orders in Live-Streaming. OneMall has been deployed, serving over 400 million daily active users at Kuaishou.
OneMall: One Model, More Scenarios -- End-to-End Generative Recommender Family at Kuaishou E-Commerce
Jan 29, 2026In the wave of generative recommendation, we present OneMall, an end-to-end generative recommendation framework tailored for e-commerce services at Kuaishou. Our OneMall systematically unifies the e-commerce's multiple item distribution scenarios, such as Product-card, short-video and live-streaming. Specifically, it comprises three key components, aligning the entire model training pipeline to the LLM's pre-training/post-training: (1) E-commerce Semantic Tokenizer: we provide a tokenizer solution that captures both real-world semantics and business-specific item relations across different scenarios; (2) Transformer-based Architecture: we largely utilize Transformer as our model backbone, e.g., employing Query-Former for long sequence compression, Cross-Attention for multi-behavior sequence fusion, and Sparse MoE for scalable auto-regressive generation; (3) Reinforcement Learning Pipeline: we further connect retrieval and ranking models via RL, enabling the ranking model to serve as a reward signal for end-to-end policy retrieval model optimization. Extensive experiments demonstrate that OneMall achieves consistent improvements across all e-commerce scenarios: +13.01\% GMV in product-card, +15.32\% Orders in Short-Video, and +2.78\% Orders in Live-Streaming. OneMall has been deployed, serving over 400 million daily active users at Kuaishou.
QARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou
Nov 18, 2024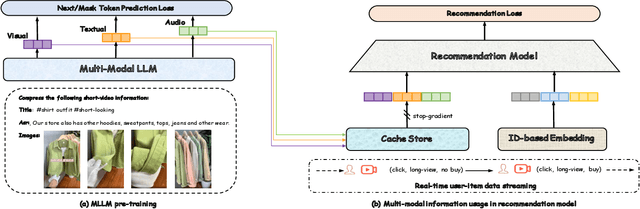
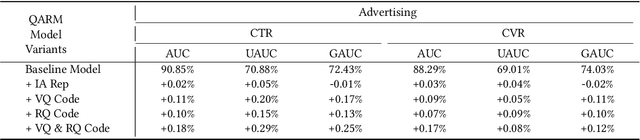
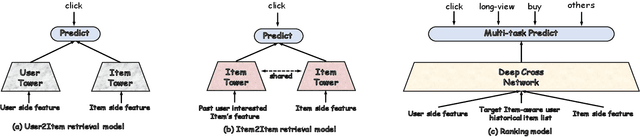
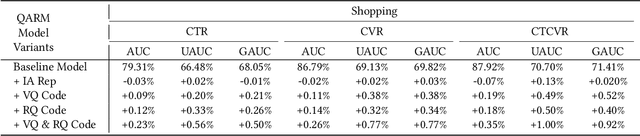
In recent years, with the significant evolution of multi-modal large models, many recommender researchers realized the potential of multi-modal information for user interest modeling. In industry, a wide-used modeling architecture is a cascading paradigm: (1) first pre-training a multi-modal model to provide omnipotent representations for downstream services; (2) The downstream recommendation model takes the multi-modal representation as additional input to fit real user-item behaviours. Although such paradigm achieves remarkable improvements, however, there still exist two problems that limit model performance: (1) Representation Unmatching: The pre-trained multi-modal model is always supervised by the classic NLP/CV tasks, while the recommendation models are supervised by real user-item interaction. As a result, the two fundamentally different tasks' goals were relatively separate, and there was a lack of consistent objective on their representations; (2) Representation Unlearning: The generated multi-modal representations are always stored in cache store and serve as extra fixed input of recommendation model, thus could not be updated by recommendation model gradient, further unfriendly for downstream training. Inspired by the two difficulties challenges in downstream tasks usage, we introduce a quantitative multi-modal framework to customize the specialized and trainable multi-modal information for different downstream models.
MvKSR: Multi-view Knowledge-guided Scene Recovery for Hazy and Rainy Degradation
Jan 09, 2024



High-quality imaging is crucial for ensuring safety supervision and intelligent deployment in fields like transportation and industry. It enables precise and detailed monitoring of operations, facilitating timely detection of potential hazards and efficient management. However, adverse weather conditions, such as atmospheric haziness and precipitation, can have a significant impact on image quality. When the atmosphere contains dense haze or water droplets, the incident light scatters, leading to degraded captured images. This degradation is evident in the form of image blur and reduced contrast, increasing the likelihood of incorrect assessments and interpretations by intelligent imaging systems (IIS). To address the challenge of restoring degraded images in hazy and rainy conditions, this paper proposes a novel multi-view knowledge-guided scene recovery network (termed MvKSR). Specifically, guided filtering is performed on the degraded image to separate high/low-frequency components. Subsequently, an en-decoder-based multi-view feature coarse extraction module (MCE) is used to coarsely extract features from different views of the degraded image. The multi-view feature fine fusion module (MFF) will learn and infer the restoration of degraded images through mixed supervision under different views. Additionally, we suggest an atrous residual block to handle global restoration and local repair in hazy/rainy/mixed scenes. Extensive experimental results demonstrate that MvKSR outperforms other state-of-the-art methods in terms of efficiency and stability for restoring degraded scenarios in IIS.