 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerMaster: A Vision Foundation Model for Soccer Understanding
Dec 11, 2025Soccer understanding has recently garnered growing research interest due to its domain-specific complexity and unique challenges. Unlike prior works that typically rely on isolated, task-specific expert models, this work aims to propose a unified model to handle diverse soccer visual understanding tasks, ranging from fine-grained perception (e.g., athlete detection) to semantic reasoning (e.g., event classification). Specifically, our contributions are threefold: (i) we present SoccerMaster, the first soccer-specific vision foundation model that unifies diverse understanding tasks within a single framework via supervised multi-task pretraining; (ii) we develop an automated data curation pipeline to generate scalable spatial annotations, and integrate them with various existing soccer video datasets to construct SoccerFactory, a comprehensive pretraining data resource; and (iii) we conduct extensive evaluations demonstrating that SoccerMaster consistently outperforms task-specific expert models across diverse downstream tasks, highlighting its breadth and superiority. The data, code, and model will be publicly available.
Multi-Agent System for Comprehensive Soccer Understanding
May 06, 2025Recent advancements in AI-driven soccer understanding have demonstrated rapid progress, yet existing research predominantly focuses on isolated or narrow tasks. To bridge this gap, we propose a comprehensive framework for holistic soccer understanding. Specifically, we make the following contributions in this paper: (i) we construct SoccerWiki, the first large-scale multimodal soccer knowledge base, integrating rich domain knowledge about players, teams, referees, and venues to enable knowledge-driven reasoning; (ii) we present SoccerBench, the largest and most comprehensive soccer-specific benchmark, featuring around 10K standardized multimodal (text, image, video) multi-choice QA pairs across 13 distinct understanding tasks, curated through automated pipelines and manual verification; (iii) we introduce SoccerAgent, a novel multi-agent system that decomposes complex soccer questions via collaborative reasoning, leveraging domain expertise from SoccerWiki and achieving robust performance; (iv) extensive evaluations and ablations that benchmark state-of-the-art MLLMs on SoccerBench, highlighting the superiority of our proposed agentic system. All data and code are publicly available at: https://jyrao.github.io/SoccerAgent/.
Towards Universal Soccer Video Understanding
Dec 02, 2024As a globally celebrated sport, soccer has attracted widespread interest from fans over the world. This paper aims to develop a comprehensive multi-modal framework for soccer video understanding. Specifically, we make the following contributions in this paper: (i) we introduce SoccerReplay-1988, the largest multi-modal soccer dataset to date, featuring videos and detailed annotations from 1,988 complete matches, with an automated annotation pipeline; (ii) we present the first visual-language foundation model in the soccer domain, MatchVision, which leverages spatiotemporal information across soccer videos and excels in various downstream tasks; (iii) we conduct extensive experiments and ablation studies on action classification, commentary generation, and multi-view foul recognition, and demonstrate state-of-the-art performance on all of them, substantially outperforming existing models, which has demonstrated the superiority of our proposed data and model. We believe that this work will offer a standard paradigm for sports understanding research. The code and model will be publicly available for reproduction.
MatchTime: Towards Automatic Soccer Game Commentary Generation
Jun 26, 2024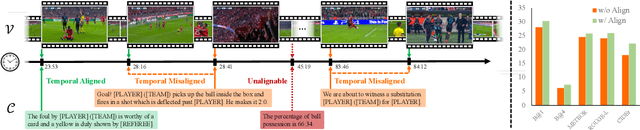

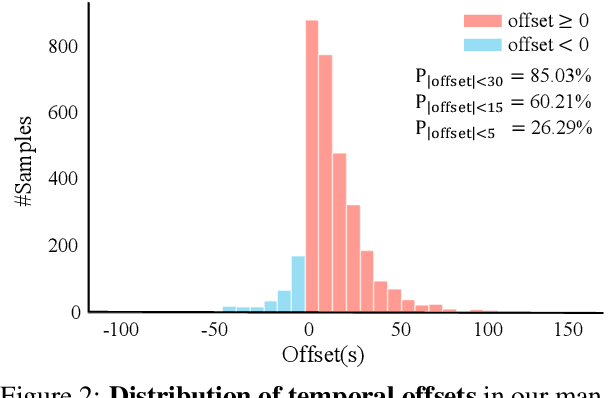
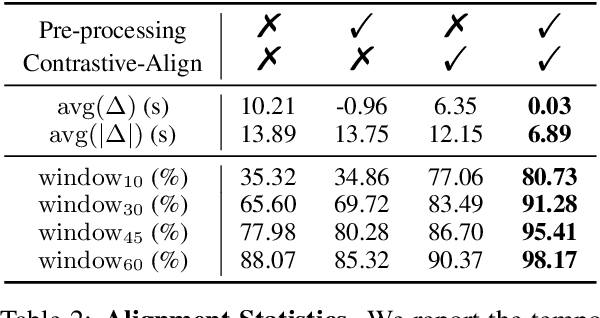
Soccer is a globally popular sport with a vast audience, in this paper, we consider constructing an automatic soccer game commentary model to improve the audiences' viewing experience. In general, we make the following contributions: First, observing the prevalent video-text misalignment in existing datasets, we manually annotate timestamps for 49 matches, establishing a more robust benchmark for soccer game commentary generation, termed as SN-Caption-test-align; Second, we propose a multi-modal temporal alignment pipeline to automatically correct and filter the existing dataset at scale, creating a higher-quality soccer game commentary dataset for training, denoted as MatchTime; Third, based on our curated dataset, we train an automatic commentary generation model, named MatchVoice. Extensive experiments and ablation studies have demonstrated the effectiveness of our alignment pipeline, and training model on the curated datasets achieves state-of-the-art performance for commentary generation, showcasing that better alignment can lead to significant performance improvements in downstream tasks.