 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatchTime: Towards Automatic Soccer Game Commentary Generation
Paper and Code
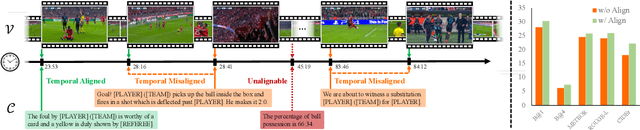

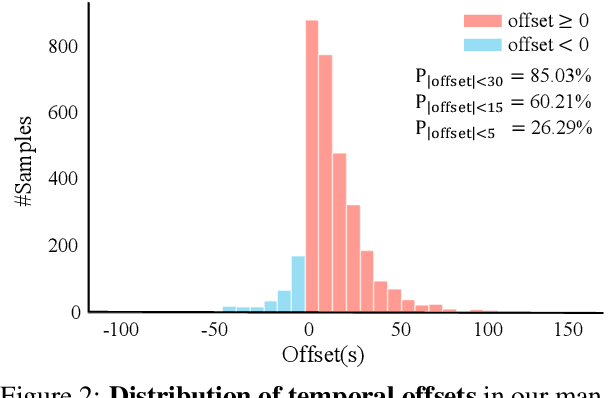
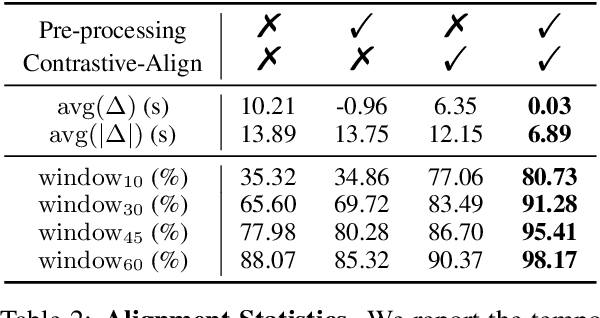
Soccer is a globally popular sport with a vast audience, in this paper, we consider constructing an automatic soccer game commentary model to improve the audiences' viewing experience. In general, we make the following contributions: First, observing the prevalent video-text misalignment in existing datasets, we manually annotate timestamps for 49 matches, establishing a more robust benchmark for soccer game commentary generation, termed as SN-Caption-test-align; Second, we propose a multi-modal temporal alignment pipeline to automatically correct and filter the existing dataset at scale, creating a higher-quality soccer game commentary dataset for training, denoted as MatchTime; Third, based on our curated dataset, we train an automatic commentary generation model, named MatchVoice. Extensive experiments and ablation studies have demonstrated the effectiveness of our alignment pipeline, and training model on the curated datasets achieves state-of-the-art performance for commentary generation, showcasing that better alignment can lead to significant performance improvements in downstream tasks.