 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC$^2$LEVA: Toward Comprehensive and Contamination-Free Language Model Evaluation
Dec 06, 2024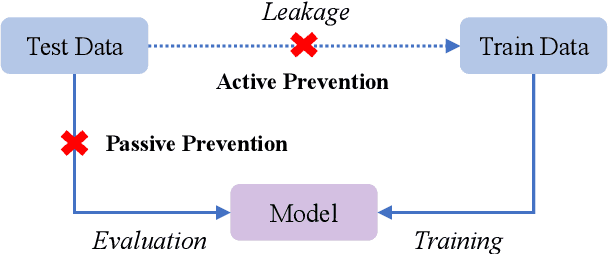

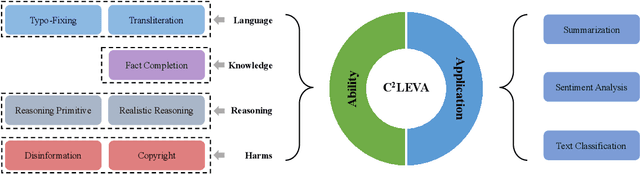

Recent advances in large language models (LLMs) have shown significant promise, yet their evaluation raises concerns, particularly regarding data contamination due to the lack of access to proprietary training data. To address this issue, we present C$^2$LEVA, a comprehensive bilingual benchmark featuring systematic contamination prevention. C$^2$LEVA firstly offers a holistic evaluation encompassing 22 tasks, each targeting a specific application or ability of LLMs, and secondly a trustworthy assessment due to our contamination-free tasks, ensured by a systematic contamination prevention strategy that fully automates test data renewal and enforces data protection during benchmark data release. Our large-scale evaluation of 15 open-source and proprietary models demonstrates the effectiveness of C$^2$LEVA.
CLEVA: Chinese Language Models EVAluation Platform
Aug 09, 2023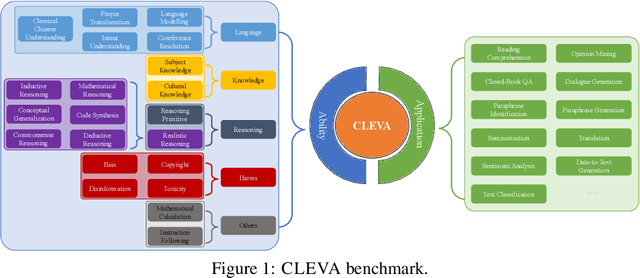
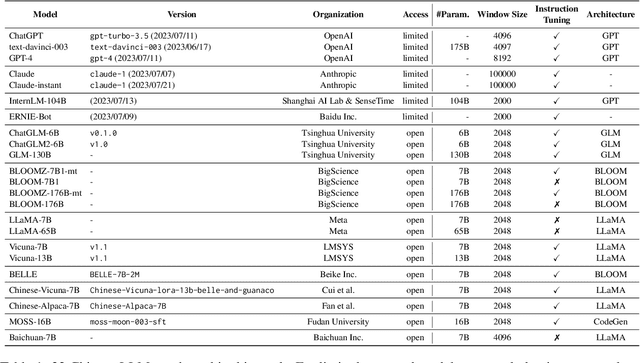
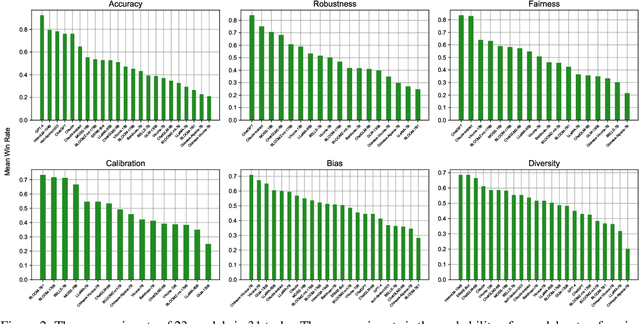

With the continuous emergence of Chinese Large Language Models (LLMs), how to evaluate a model's capabilities has become an increasingly significant issue. The absence of a comprehensive Chinese benchmark that thoroughly assesses a model's performance, the unstandardized and incomparable prompting procedure, and the prevalent risk of contamination pose major challenges in the current evaluation of Chinese LLMs. We present CLEVA, a user-friendly platform crafted to holistically evaluate Chinese LLMs. Our platform employs a standardized workflow to assess LLMs' performance across various dimensions, regularly updating a competitive leaderboard. To alleviate contamination, CLEVA curates a significant proportion of new data and develops a sampling strategy that guarantees a unique subset for each leaderboard round. Empowered by an easy-to-use interface that requires just a few mouse clicks and a model API, users can conduct a thorough evaluation with minimal coding. Large-scale experiments featuring 23 influential Chinese LLMs have validated CLEVA's efficacy.
Eliciting Knowledge from Large Pre-Trained Models for Unsupervised Knowledge-Grounded Conversation
Nov 08, 2022



Recent advances in large-scale pre-training provide large models with the potential to learn knowledge from the raw text. It is thus natural to ask whether it is possible to leverage these large models as knowledge bases for downstream tasks. In this work, we answer the aforementioned question in unsupervised knowledge-grounded conversation. We explore various methods that best elicit knowledge from large models. Our human study indicates that, though hallucinations exist, large models post the unique advantage of being able to output common sense and summarize facts that cannot be directly retrieved from the search engine. To better exploit such generated knowledge in dialogue generation, we treat the generated knowledge as a noisy knowledge source and propose the posterior-based reweighing as well as the noisy training strategy. Empirical results on two benchmarks show advantages over the state-of-the-art methods.
Diverse Text Generation via Variational Encoder-Decoder Models with Gaussian Process Priors
Apr 04, 2022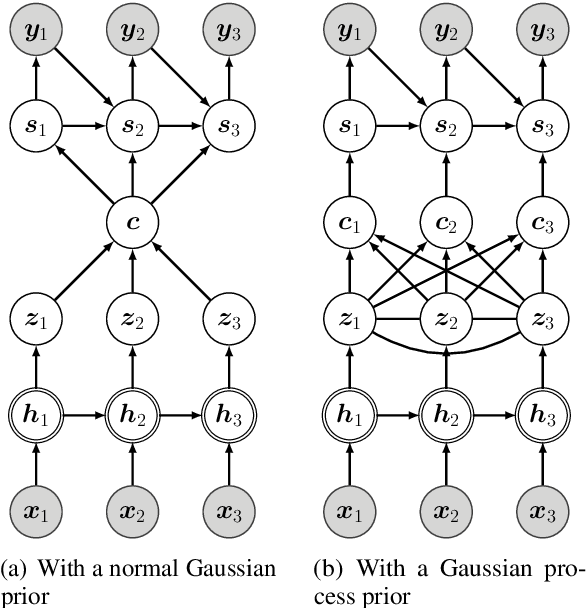



Generating high quality texts with high diversity is important for many NLG applications, but current methods mostly focus on building deterministic models to generate higher quality texts and do not provide many options for promoting diversity. In this work, we present a novel latent structured variable model to generate high quality texts by enriching contextual representation learning of encoder-decoder models. Specifically, we introduce a stochastic function to map deterministic encoder hidden states into random context variables. The proposed stochastic function is sampled from a Gaussian process prior to (1) provide infinite number of joint Gaussian distributions of random context variables (diversity-promoting) and (2) explicitly model dependency between context variables (accurate-encoding). To address the learning challenge of Gaussian processes, we propose an efficient variational inference approach to approximate the posterior distribution of random context variables. We evaluate our method in two typical text generation tasks: paraphrase generation and text style transfer. Experimental results on benchmark datasets demonstrate that our method improves the generation quality and diversity compared with other baselines.
FlowEval: A Consensus-Based Dialogue Evaluation Framework Using Segment Act Flows
Feb 14, 2022



Despite recent progress in open-domain dialogue evaluation, how to develop automatic metrics remains an open problem. We explore the potential of dialogue evaluation featuring dialog act information, which was hardly explicitly modeled in previous methods. However, defined at the utterance level in general, dialog act is of coarse granularity, as an utterance can contain multiple segments possessing different functions. Hence, we propose segment act, an extension of dialog act from utterance level to segment level, and crowdsource a large-scale dataset for it. To utilize segment act flows, sequences of segment acts, for evaluation, we develop the first consensus-based dialogue evaluation framework, FlowEval. This framework provides a reference-free approach for dialog evaluation by finding pseudo-references. Extensive experiments against strong baselines on three benchmark datasets demonstrate the effectiveness and other desirable characteristics of our FlowEval, pointing out a potential path for better dialogue evaluation.
NaturalConv: A Chinese Dialogue Dataset Towards Multi-turn Topic-driven Conversation
Mar 05, 2021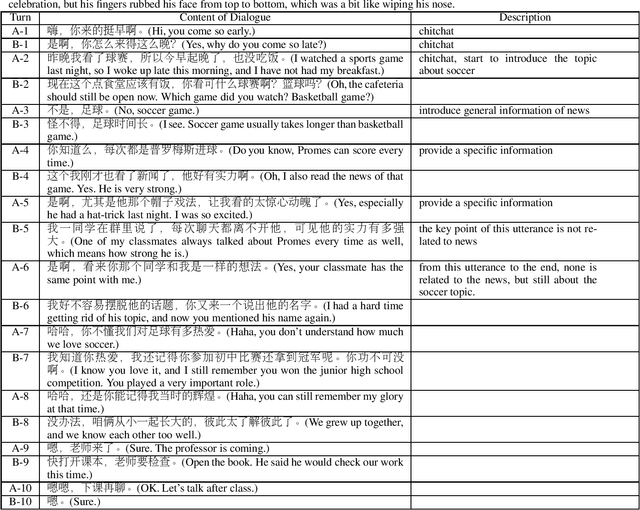



In this paper, we propose a Chinese multi-turn topic-driven conversation dataset, NaturalConv, which allows the participants to chat anything they want as long as any element from the topic is mentioned and the topic shift is smooth. Our corpus contains 19.9K conversations from six domains, and 400K utterances with an average turn number of 20.1. These conversations contain in-depth discussions on related topics or widely natural transition between multiple topics. We believe either way is normal for human conversation. To facilitate the research on this corpus, we provide results of several benchmark models. Comparative results show that for this dataset, our current models are not able to provide significant improvement by introducing background knowledge/topic. Therefore, the proposed dataset should be a good benchmark for further research to evaluate the validity and naturalness of multi-turn conversation systems. Our dataset is available at https://ai.tencent.com/ailab/nlp/dialogue/#datasets.