 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC$^2$LEVA: Toward Comprehensive and Contamination-Free Language Model Evaluation
Dec 06, 2024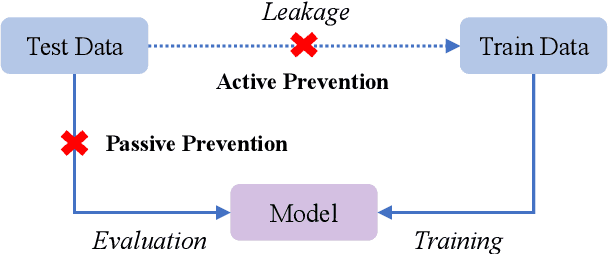

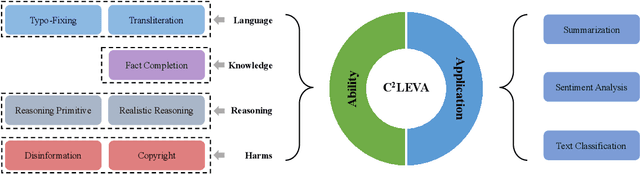

Recent advances in large language models (LLMs) have shown significant promise, yet their evaluation raises concerns, particularly regarding data contamination due to the lack of access to proprietary training data. To address this issue, we present C$^2$LEVA, a comprehensive bilingual benchmark featuring systematic contamination prevention. C$^2$LEVA firstly offers a holistic evaluation encompassing 22 tasks, each targeting a specific application or ability of LLMs, and secondly a trustworthy assessment due to our contamination-free tasks, ensured by a systematic contamination prevention strategy that fully automates test data renewal and enforces data protection during benchmark data release. Our large-scale evaluation of 15 open-source and proprietary models demonstrates the effectiveness of C$^2$LEVA.