 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePotential and Limitations of LLMs in Capturing Structured Semantics: A Case Study on SRL
May 10, 2024


Large Language Models (LLMs) play a crucial role in capturing structured semantics to enhance language understanding, improve interpretability, and reduce bias. Nevertheless, an ongoing controversy exists over the extent to which LLMs can grasp structured semantics. To assess this, we propose using Semantic Role Labeling (SRL) as a fundamental task to explore LLMs' ability to extract structured semantics. In our assessment, we employ the prompting approach, which leads to the creation of our few-shot SRL parser, called PromptSRL. PromptSRL enables LLMs to map natural languages to explicit semantic structures, which provides an interpretable window into the properties of LLMs. We find interesting potential: LLMs can indeed capture semantic structures, and scaling-up doesn't always mirror potential. Additionally, limitations of LLMs are observed in C-arguments, etc. Lastly, we are surprised to discover that significant overlap in the errors is made by both LLMs and untrained humans, accounting for almost 30% of all errors.
CausalCellSegmenter: Causal Inference inspired Diversified Aggregation Convolution for Pathology Image Segmentation
Mar 10, 2024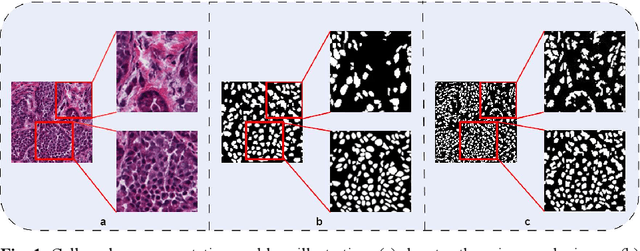



Deep learning models have shown promising performance for cell nucleus segmentation in the field of pathology image analysis. However, training a robust model from multiple domains remains a great challenge for cell nucleus segmentation. Additionally, the shortcomings of background noise, highly overlapping between cell nucleus, and blurred edges often lead to poor performance. To address these challenges, we propose a novel framework termed CausalCellSegmenter, which combines Causal Inference Module (CIM) with Diversified Aggregation Convolution (DAC) techniques. The DAC module is designed which incorporates diverse downsampling features through a simple, parameter-free attention module (SimAM), aiming to overcome the problems of false-positive identification and edge blurring. Furthermore, we introduce CIM to leverage sample weighting by directly removing the spurious correlations between features for every input sample and concentrating more on the correlation between features and labels. Extensive experiments on the MoNuSeg-2018 dataset achieves promising results, outperforming other state-of-the-art methods, where the mIoU and DSC scores growing by 3.6% and 2.65%.
OpenNDD: Open Set Recognition for Neurodevelopmental Disorders Detection
Jun 28, 2023


Neurodevelopmental disorders (NDDs) are a highly prevalent group of disorders and represent strong clinical behavioral similarities, and that make it very challenging for accurate identification of different NDDs such as autism spectrum disorder (ASD) and attention-deficit hyperactivity disorder (ADHD). Moreover, there is no reliable physiological markers for NDDs diagnosis and it solely relies on psychological evaluation criteria. However, it is crucial to prevent misdiagnosis and underdiagnosis by intelligent assisted diagnosis, which is closely related to the follow-up corresponding treatment. In order to relieve these issues, we propose a novel open set recognition framework for NDDs screening and detection, which is the first application of open set recognition in this field. It combines auto encoder and adversarial reciprocal points open set recognition to accurately identify known classes as well as recognize classes never encountered. And considering the strong similarities between different subjects, we present a joint scaling method called MMS to distinguish unknown disorders. To validate the feasibility of our presented method, we design a reciprocal opposition experiment protocol on the hybrid datasets from Autism Brain Imaging Data Exchange I (ABIDE I) and THE ADHD-200 SAMPLE (ADHD-200) with 791 samples from four sites and the results demonstrate the superiority on various metrics. Our OpenNDD has achieved promising performance, where the accuracy is 77.38%, AUROC is 75.53% and the open set classification rate is as high as 59.43%.