 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeAPN: Adaptive Amplitude-Phase Non-Stationarity Normalization for Time Series Forecasting
Mar 18, 2026Non-stationarity is a fundamental challenge in multivariate long-term time series forecasting, often manifested as rapid changes in amplitude and phase. These variations lead to severe distribution shifts and consequently degrade predictive performance. Existing normalization-based methods primarily rely on first- and second-order statistics, implicitly assuming that distributions evolve smoothly and overlooking fine-grained temporal dynamics. To address these limitations, we propose TimeAPN, an Adaptive Amplitude-Phase Non-Stationarity Normalization framework that explicitly models and predicts non-stationary factors from both the time and frequency domains. Specifically, TimeAPN first models the mean sequence jointly in the time and frequency domains, and then forecasts its evolution over future horizons. Meanwhile, phase information is extracted in the frequency domain, and the phase discrepancy between the predicted and ground-truth future sequences is explicitly modeled to capture temporal misalignment. Furthermore, TimeAPN incorporates amplitude information into an adaptive normalization mechanism, enabling the model to effectively account for abrupt fluctuations in signal energy. The predicted non-stationary factors are subsequently integrated with the backbone forecasting outputs through a collaborative de-normalization process to reconstruct the final non-stationary time series. The proposed framework is model-agnostic and can be seamlessly integrated with various forecasting backbones. Extensive experiments on seven real-world multivariate datasets demonstrate that TimeAPN consistently improves long-term forecasting accuracy across multiple prediction horizons and outperforms state-of-the-art reversible normalization methods.
SAQNN: Spectral Adaptive Quantum Neural Network as a Universal Approximator
Feb 10, 2026Quantum machine learning (QML), as an interdisciplinary field bridging quantum computing and machine learning, has garnered significant attention in recent years. Currently, the field as a whole faces challenges due to incomplete theoretical foundations for the expressivity of quantum neural networks (QNNs). In this paper we propose a constructive QNN model and demonstrate that it possesses the universal approximation property (UAP), which means it can approximate any square-integrable function up to arbitrary accuracy. Furthermore, it supports switching function bases, thus adaptable to various scenarios in numerical approximation and machine learning. Our model has asymptotic advantages over the best classical feed-forward neural networks in terms of circuit size and achieves optimal parameter complexity when approximating Sobolev functions under $L_2$ norm.
LLM-PS: Empowering Large Language Models for Time Series Forecasting with Temporal Patterns and Semantics
Mar 12, 2025Time Series Forecasting (TSF) is critical in many real-world domains like financial planning and health monitoring. Recent studies have revealed that Large Language Models (LLMs), with their powerful in-contextual modeling capabilities, hold significant potential for TSF. However, existing LLM-based methods usually perform suboptimally because they neglect the inherent characteristics of time series data. Unlike the textual data used in LLM pre-training, the time series data is semantically sparse and comprises distinctive temporal patterns. To address this problem, we propose LLM-PS to empower the LLM for TSF by learning the fundamental \textit{Patterns} and meaningful \textit{Semantics} from time series data. Our LLM-PS incorporates a new multi-scale convolutional neural network adept at capturing both short-term fluctuations and long-term trends within the time series. Meanwhile, we introduce a time-to-text module for extracting valuable semantics across continuous time intervals rather than isolated time points. By integrating these patterns and semantics, LLM-PS effectively models temporal dependencies, enabling a deep comprehension of time series and delivering accurate forecasts. Intensive experimental results demonstrate that LLM-PS achieves state-of-the-art performance in both short- and long-term forecasting tasks, as well as in few- and zero-shot settings.
Hybrid Data-Free Knowledge Distillation
Dec 18, 2024Data-free knowledge distillation aims to learn a compact student network from a pre-trained large teacher network without using the original training data of the teacher network. Existing collection-based and generation-based methods train student networks by collecting massive real examples and generating synthetic examples, respectively. However, they inevitably become weak in practical scenarios due to the difficulties in gathering or emulating sufficient real-world data. To solve this problem, we propose a novel method called \textbf{H}ybr\textbf{i}d \textbf{D}ata-\textbf{F}ree \textbf{D}istillation (HiDFD), which leverages only a small amount of collected data as well as generates sufficient examples for training student networks. Our HiDFD comprises two primary modules, \textit{i.e.}, the teacher-guided generation and student distillation. The teacher-guided generation module guides a Generative Adversarial Network (GAN) by the teacher network to produce high-quality synthetic examples from very few real-world collected examples. Specifically, we design a feature integration mechanism to prevent the GAN from overfitting and facilitate the reliable representation learning from the teacher network. Meanwhile, we drive a category frequency smoothing technique via the teacher network to balance the generative training of each category. In the student distillation module, we explore a data inflation strategy to properly utilize a blend of real and synthetic data to train the student network via a classifier-sharing-based feature alignment technique. Intensive experiments across multiple benchmarks demonstrate that our HiDFD can achieve state-of-the-art performance using 120 times less collected data than existing methods. Code is available at https://github.com/tangjialiang97/HiDFD.
Learn from Balance: Rectifying Knowledge Transfer for Long-Tailed Scenarios
Sep 12, 2024


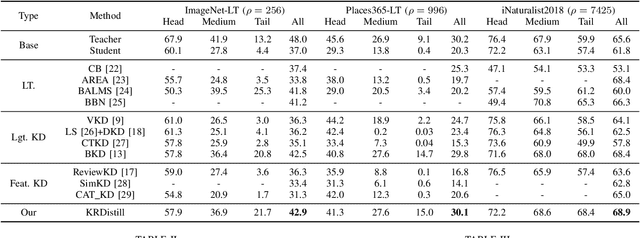
Knowledge Distillation (KD) transfers knowledge from a large pre-trained teacher network to a compact and efficient student network, making it suitable for deployment on resource-limited media terminals. However, traditional KD methods require balanced data to ensure robust training, which is often unavailable in practical applications. In such scenarios, a few head categories occupy a substantial proportion of examples. This imbalance biases the trained teacher network towards the head categories, resulting in severe performance degradation on the less represented tail categories for both the teacher and student networks. In this paper, we propose a novel framework called Knowledge Rectification Distillation (KRDistill) to address the imbalanced knowledge inherited in the teacher network through the incorporation of the balanced category priors. Furthermore, we rectify the biased predictions produced by the teacher network, particularly focusing on the tail categories. Consequently, the teacher network can provide balanced and accurate knowledge to train a reliable student network. Intensive experiments conducted on various long-tailed datasets demonstrate that our KRDistill can effectively train reliable student networks in realistic scenarios of data imbalance.
Direct Distillation between Different Domains
Jan 12, 2024



Knowledge Distillation (KD) aims to learn a compact student network using knowledge from a large pre-trained teacher network, where both networks are trained on data from the same distribution. However, in practical applications, the student network may be required to perform in a new scenario (i.e., the target domain), which usually exhibits significant differences from the known scenario of the teacher network (i.e., the source domain). The traditional domain adaptation techniques can be integrated with KD in a two-stage process to bridge the domain gap, but the ultimate reliability of two-stage approaches tends to be limited due to the high computational consumption and the additional errors accumulated from both stages. To solve this problem, we propose a new one-stage method dubbed ``Direct Distillation between Different Domains" (4Ds). We first design a learnable adapter based on the Fourier transform to separate the domain-invariant knowledge from the domain-specific knowledge. Then, we build a fusion-activation mechanism to transfer the valuable domain-invariant knowledge to the student network, while simultaneously encouraging the adapter within the teacher network to learn the domain-specific knowledge of the target data. As a result, the teacher network can effectively transfer categorical knowledge that aligns with the target domain of the student network. Intensive experiments on various benchmark datasets demonstrate that our proposed 4Ds method successfully produces reliable student networks and outperforms state-of-the-art approaches.
Distribution Shift Matters for Knowledge Distillation with Webly Collected Images
Jul 21, 2023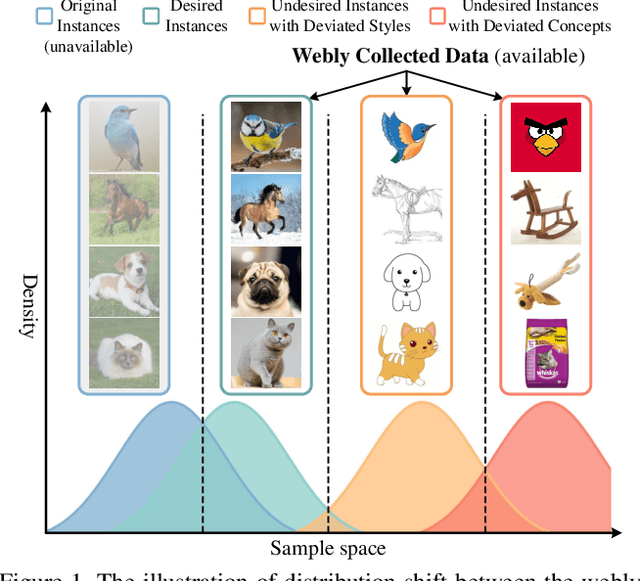



Knowledge distillation aims to learn a lightweight student network from a pre-trained teacher network. In practice, existing knowledge distillation methods are usually infeasible when the original training data is unavailable due to some privacy issues and data management considerations. Therefore, data-free knowledge distillation approaches proposed to collect training instances from the Internet. However, most of them have ignored the common distribution shift between the instances from original training data and webly collected data, affecting the reliability of the trained student network. To solve this problem, we propose a novel method dubbed ``Knowledge Distillation between Different Distributions" (KD$^{3}$), which consists of three components. Specifically, we first dynamically select useful training instances from the webly collected data according to the combined predictions of teacher network and student network. Subsequently, we align both the weighted features and classifier parameters of the two networks for knowledge memorization. Meanwhile, we also build a new contrastive learning block called MixDistribution to generate perturbed data with a new distribution for instance alignment, so that the student network can further learn a distribution-invariant representation. Intensive experiments on various benchmark datasets demonstrate that our proposed KD$^{3}$ can outperform the state-of-the-art data-free knowledge distillation approaches.