 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn from Balance: Rectifying Knowledge Transfer for Long-Tailed Scenarios
Paper and Code



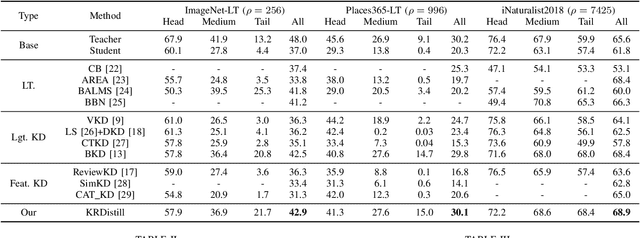
Knowledge Distillation (KD) transfers knowledge from a large pre-trained teacher network to a compact and efficient student network, making it suitable for deployment on resource-limited media terminals. However, traditional KD methods require balanced data to ensure robust training, which is often unavailable in practical applications. In such scenarios, a few head categories occupy a substantial proportion of examples. This imbalance biases the trained teacher network towards the head categories, resulting in severe performance degradation on the less represented tail categories for both the teacher and student networks. In this paper, we propose a novel framework called Knowledge Rectification Distillation (KRDistill) to address the imbalanced knowledge inherited in the teacher network through the incorporation of the balanced category priors. Furthermore, we rectify the biased predictions produced by the teacher network, particularly focusing on the tail categories. Consequently, the teacher network can provide balanced and accurate knowledge to train a reliable student network. Intensive experiments conducted on various long-tailed datasets demonstrate that our KRDistill can effectively train reliable student networks in realistic scenarios of data imbalance.