 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProactive Knowledge Inquiry in Doctor-Patient Dialogue: Stateful Extraction, Belief Updating, and Path-Aware Action Planning
Mar 18, 2026Most automated electronic medical record (EMR) pipelines remain output-oriented: they transcribe, extract, and summarize after the consultation, but they do not explicitly model what is already known, what is still missing, which uncertainty matters most, or what question or recommendation should come next. We formulate doctor-patient dialogue as a proactive knowledge-inquiry problem under partial observability. The proposed framework combines stateful extraction, sequential belief updating, gap-aware state modeling, hybrid retrieval over objectified medical knowledge, and a POMDP-lite action planner. Instead of treating the EMR as the only target artifact, the framework treats documentation as the structured projection of an ongoing inquiry loop. To make the formulation concrete, we report a controlled pilot evaluation on ten standardized multi-turn dialogues together with a 300-query retrieval benchmark aggregated across dialogues. On this pilot protocol, the full framework reaches 83.3% coverage, 80.0% risk recall, 81.4% structural completeness, and lower redundancy than the chunk-only and template-heavy interactive baselines. These pilot results do not establish clinical generalization; rather, they suggest that proactive inquiry may be methodologically interesting under tightly controlled conditions and can be viewed as a conceptually appealing formulation worth further investigation for dialogue-based EMR generation. This work should be read as a pilot concept demonstration under a controlled simulated setting rather than as evidence of clinical deployment readiness. No implication of clinical deployment readiness, clinical safety, or real-world clinical utility should be inferred from this pilot protocol.
Subtype-Aware Dynamic Unsupervised Domain Adaptation
Aug 16, 2022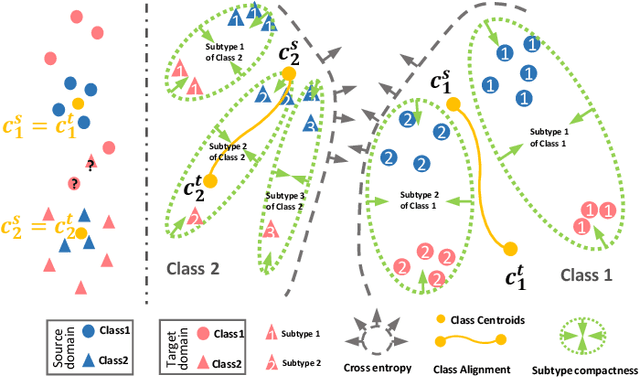
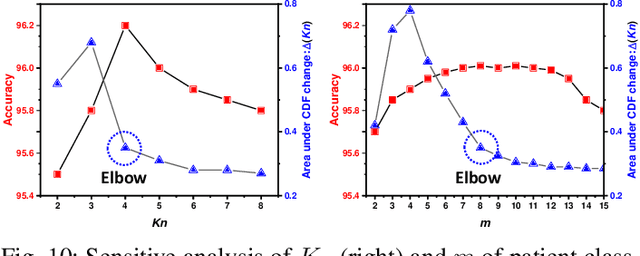
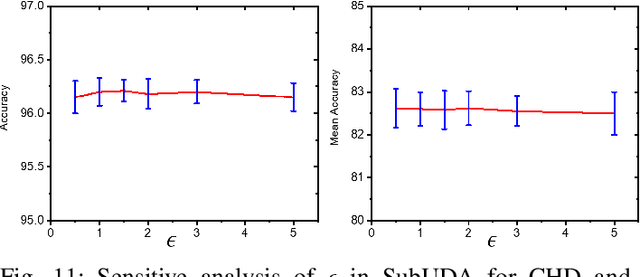
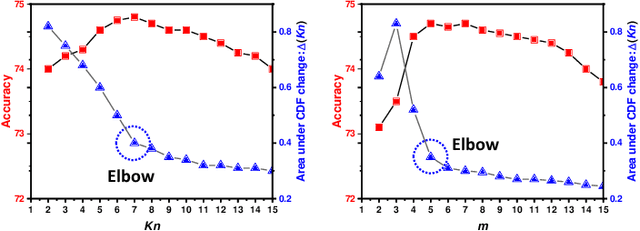
Unsupervised domain adaptation (UDA) has been successfully applied to transfer knowledge from a labeled source domain to target domains without their labels. Recently introduced transferable prototypical networks (TPN) further addresses class-wise conditional alignment. In TPN, while the closeness of class centers between source and target domains is explicitly enforced in a latent space, the underlying fine-grained subtype structure and the cross-domain within-class compactness have not been fully investigated. To counter this, we propose a new approach to adaptively perform a fine-grained subtype-aware alignment to improve performance in the target domain without the subtype label in both domains. The insight of our approach is that the unlabeled subtypes in a class have the local proximity within a subtype, while exhibiting disparate characteristics, because of different conditional and label shifts. Specifically, we propose to simultaneously enforce subtype-wise compactness and class-wise separation, by utilizing intermediate pseudo-labels. In addition, we systematically investigate various scenarios with and without prior knowledge of subtype numbers, and propose to exploit the underlying subtype structure. Furthermore, a dynamic queue framework is developed to evolve the subtype cluster centroids steadily using an alternative processing scheme. Experimental results, carried out with multi-view congenital heart disease data and VisDA and DomainNet, show the effectiveness and validity of our subtype-aware UDA, compared with state-of-the-art UDA methods.
A Deep Dive into Conflict Generating Decisions
May 10, 2021
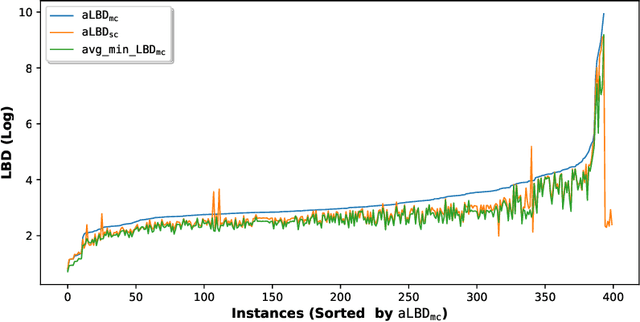
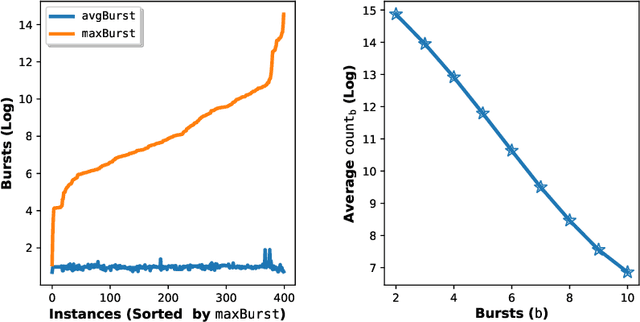

Boolean Satisfiability (SAT) is a well-known NP-complete problem. Despite this theoretical hardness, SAT solvers based on Conflict Driven Clause Learning (CDCL) can solve large SAT instances from many important domains. CDCL learns clauses from conflicts, a technique that allows a solver to prune its search space. The selection heuristics in CDCL prioritize variables that are involved in recent conflicts. While only a fraction of decisions generate any conflicts, many generate multiple conflicts. In this paper, we study conflict-generating decisions in CDCL in detail. We investigate the impact of single conflict (sc) decisions, which generate only one conflict, and multi-conflict (mc) decisions which generate two or more. We empirically characterize these two types of decisions based on the quality of the learned clauses produced by each type of decision. We also show an important connection between consecutive clauses learned within the same mc decision, where one learned clause triggers the learning of the next one forming a chain of clauses. This leads to the consideration of similarity between conflicts, for which we formulate the notion of conflictsproximity as a similarity measure. We show that conflicts in mc decisions are more closely related than consecutive conflicts generated from sc decisions. Finally, we develop Common Reason Variable Reduction (CRVR) as a new decision strategy that reduces the selection priority of some variables from the learned clauses of mc decisions. Our empirical evaluation of CRVR implemented in three leading solvers demonstrates performance gains in benchmarks from the main track of SAT Competition-2020.
Automated Computer Evaluation of Acute Ischemic Stroke and Large Vessel Occlusion
Jun 18, 2019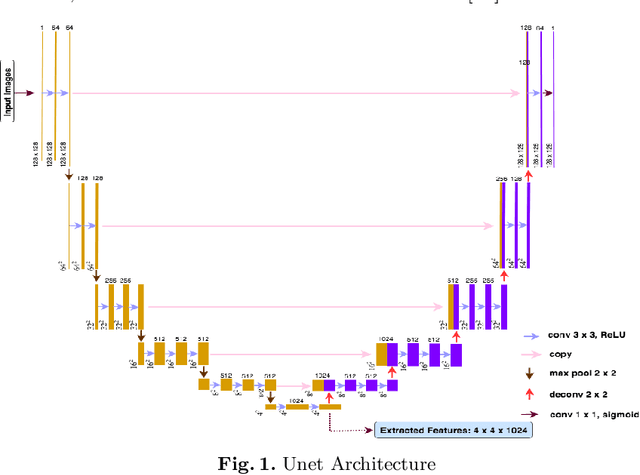
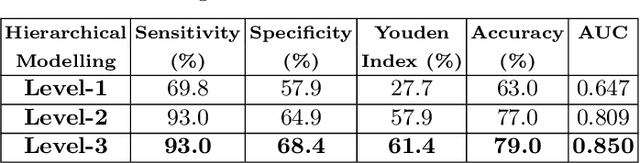
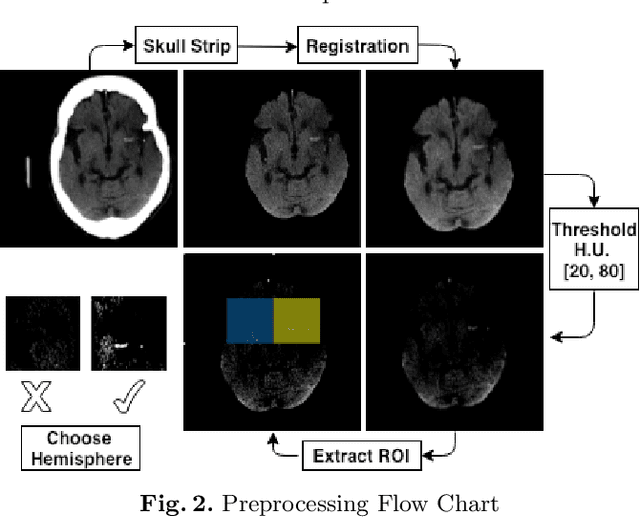
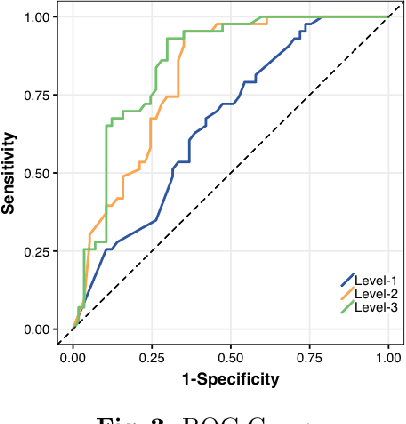
Large vessel occlusion (LVO) plays an important role in the diagnosis of acute ischemic stroke. Identifying LVO of patients in the early stage on admission would significantly lower the probabilities of suffering from severe effects due to stroke or even save their lives. In this paper, we utilized both structural and imaging data from all recorded acute ischemic stroke patients in Hong Kong. Total 300 patients (200 training and 100 testing) are used in this study. We established three hierarchical models based on demographic data, clinical data and features obtained from computerized tomography (CT) scans. The first two stages of modeling are merely based on demographic and clinical data. Besides, the third model utilized extra CT imaging features obtained from deep learning model. The optimal cutoff is determined at the maximal Youden index based on 10-fold cross-validation. With both clinical and imaging features, the Level-3 model achieved the best performance on testing data. The sensitivity, specificity, Youden index, accuracy and area under the curve (AUC) are 0.930, 0.684, 0.614, 0.790 and 0.850 respectively.
Automated Segmentation for Hyperdense Middle Cerebral Artery Sign of Acute Ischemic Stroke on Non-Contrast CT Images
May 22, 2019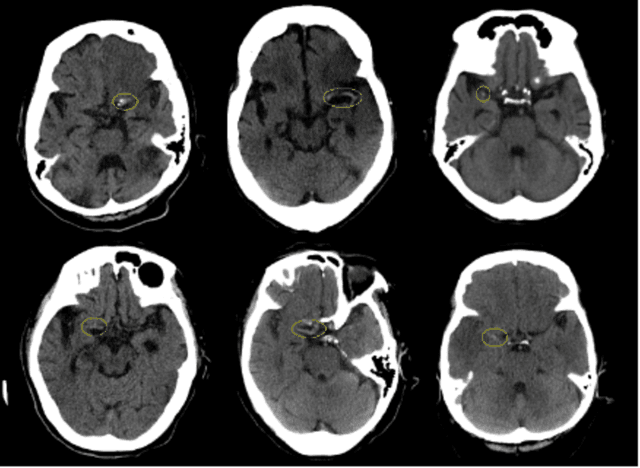

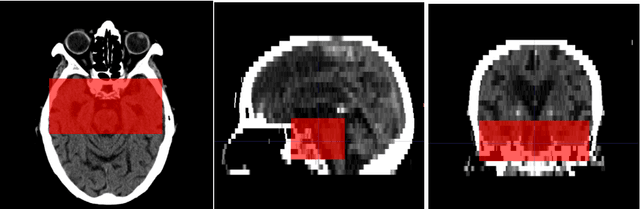
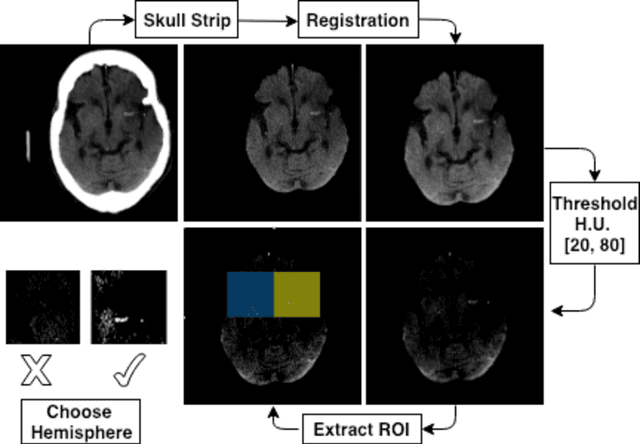
The hyperdense middle cerebral artery (MCA) dot sign has been reported as an important factor in the diagnosis of acute ischemic stroke due to large vessel occlusion. Interpreting the initial CT brain scan in these patients requires high level of expertise, and has high inter-observer variability. An automated computerized interpretation of the urgent CT brain image, with an emphasis to pick up early signs of ischemic stroke will facilitate early patient diagnosis, triage, and shorten the door-to-revascularization time for these group of patients. In this paper, we present an automated detection method of segmenting the MCA dot sign on non-contrast CT brain image scans based on powerful deep learning technique.